Adaptive Parallel Reasoning: The Next Paradigm in Efficient Inference Scaling
The BAIR Blog

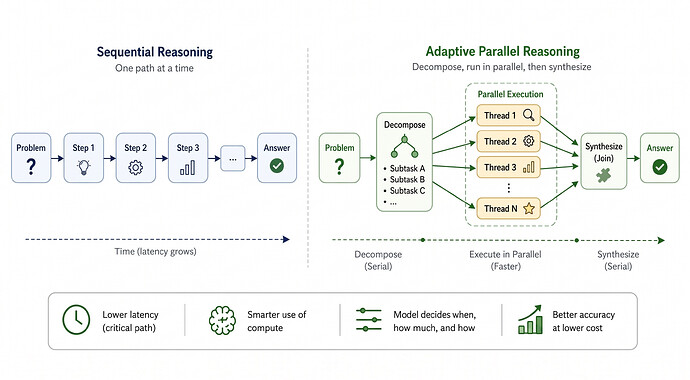
推理时,我们实际上是要求模型执行映射-还原操作:
将问题分叉为子任务/线程,并发处理它们
将它们合并为最终答案
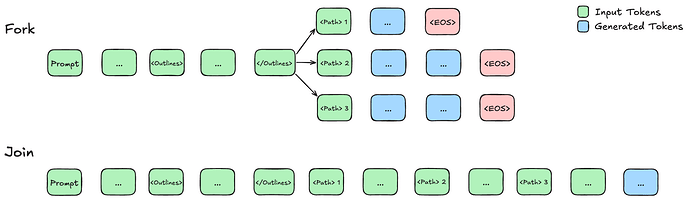
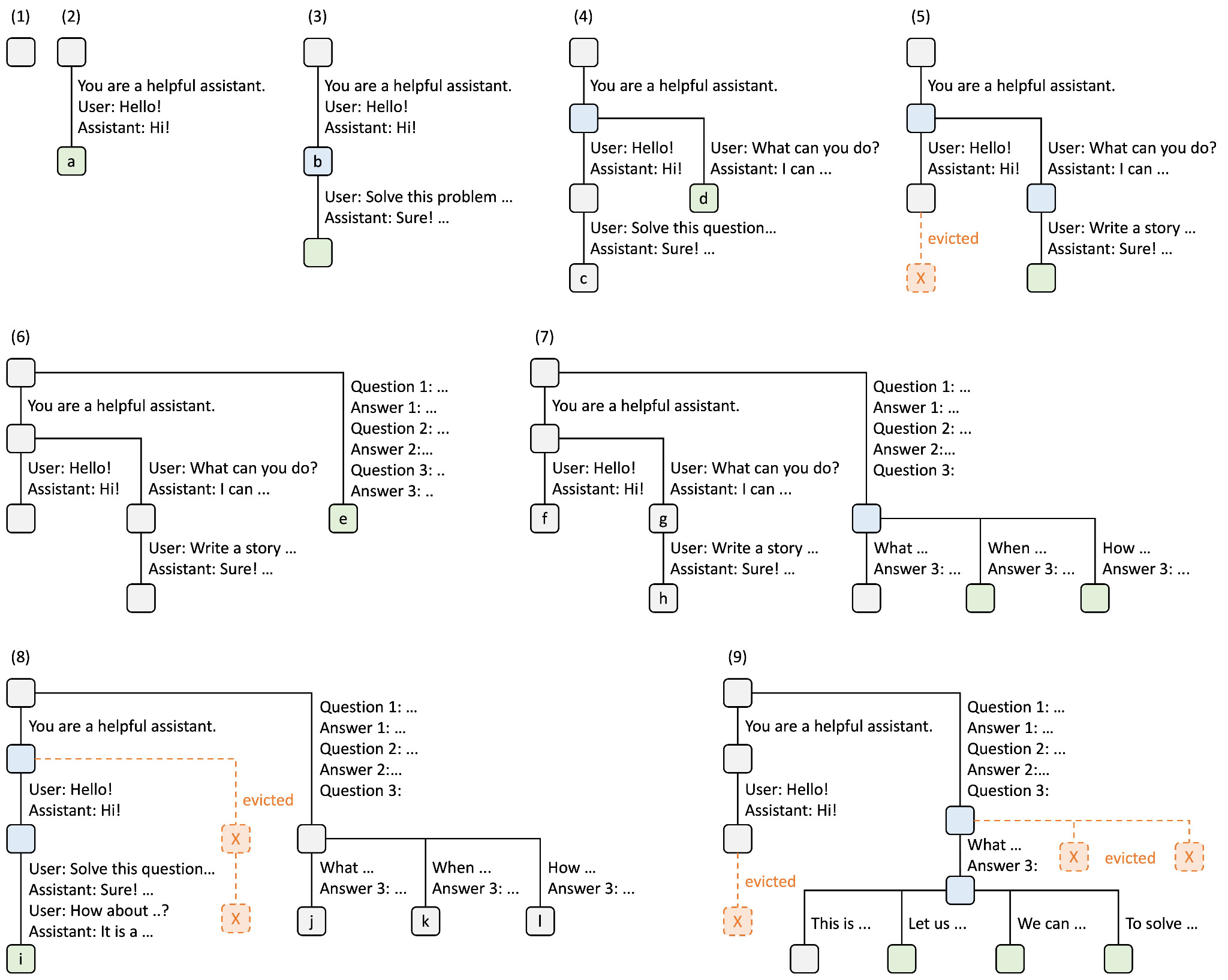
具体来说,模型会遇到一个子任务列表。然后,它将预填充每个子任务,并将其作为独立请求发送给推理引擎处理。然后,这些线程会同时进行解码,直到遇到结束标记或超过最大长度。这一过程会阻塞,直到所有线程完成解码,然后汇总结果。这在各种自适应并行推理方法中都很常见。但是,在聚合过程中会出现一个问题:分支中生成的内容无法在 KV 缓存级别上轻松聚合。这是因为独立线程中的标记从相同的位置 ID 开始,导致编码重叠,并在将 KV 缓存合并时产生非标准行为。同样,由于独立线程之间互不关注,因此它们合并后的 KV 缓存会产生非因果关注模式,而基础模型在训练过程中并没有看到这种模式。
为了解决这个问题,在如何执行聚合过程的问题上,该领域分成了两派,分别以修改推理引擎还是绕过推理引擎来定义。
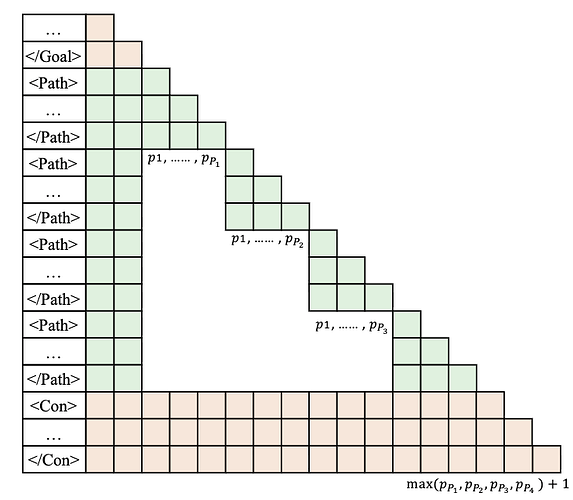
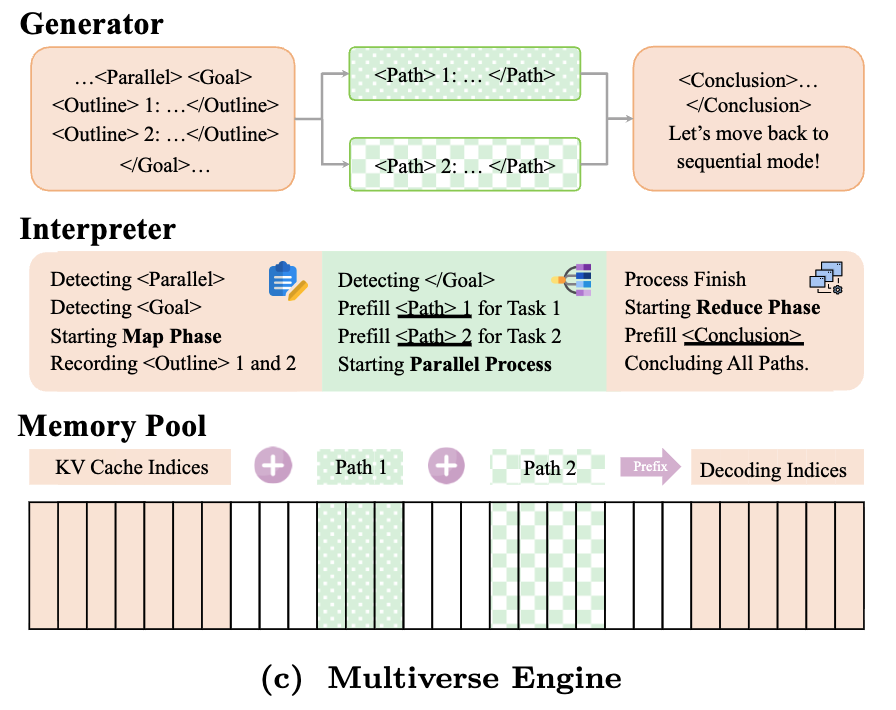
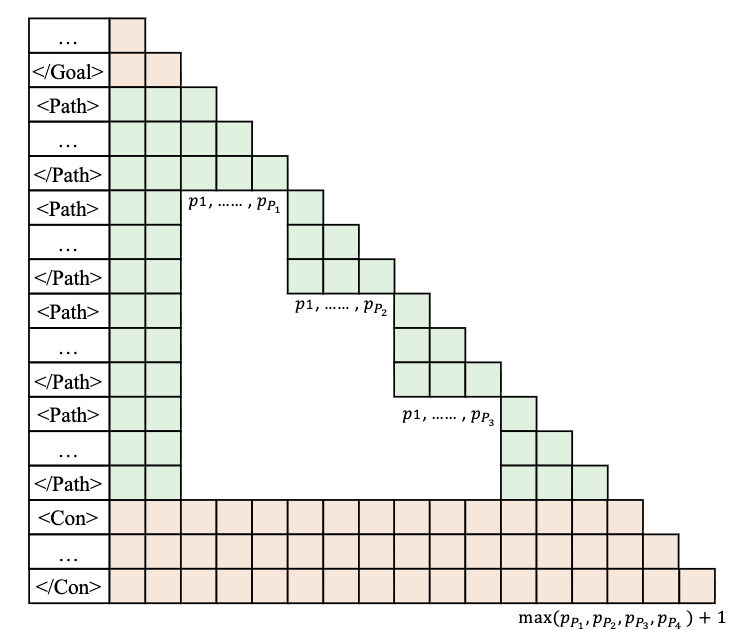
**Multiverse 修改了推理引擎,以便在连接过程中重复使用 KV 缓存。**在深入了解 Multiverse(Yang 等人,2025 年)的内存管理之前,我们先来了解一下 KV 缓存在 "连接 "阶段之前是如何处理的。请注意每个独立线程是如何共享前缀序列(即子任务列表)的。如果不进行优化,每个线程都需要为前缀序列预填充和重新计算 KV 缓存。然而,SGLang 的 RadixAttention(Sheng 等人,2023 年)可以避免这种冗余,它将多个请求组织成一棵词缀树,一棵由不同长度的元素序列而不是单个元素组成的三角形(词缀树)。这样一来,新的 KV 缓存条目只能是独立线程生成的条目。
现在,如果一切顺利,所有独立线程都已从推理引擎返回。我们现在的目标是找出如何将它们合成为一个单一的序列,以便为下一步继续解码。事实证明,我们可以在合成阶段重复使用这些独立线程的 KV 缓存。具体来说,Multiverse(Yang 等人,2025 年)、Parallel-R1(Zheng 等人,2025 年)和 NPR(Wu 等人,2025 年)修改了推理引擎,将每个线程生成的 KV 缓存复制过来,并编辑页表,以便将非连续的内存块拼接成单个 KV 缓存序列。这避免了第二次预填充的冗余计算,并尽可能地重复使用现有的 KV 缓存。然而,这也有几个主要的局限性。
首先,这种方法需要修改推理引擎来执行非标准的内存处理,这可能会导致意想不到的行为。具体来说,由于合成请求会引用之前请求的 KV 缓存,因此会造成系统的脆弱性,并可能出现坏指针。在合成请求完成之前,另一个请求可能会进来并驱逐所引用的 KV 缓存,这就要求合成请求停止,并触发前一个线程请求的重新填充。这个问题导致 Multiverse 研究人员(Yang 等人,2025 年)限制了推理引擎可以处理的批量大小,从而限制了吞吐量。
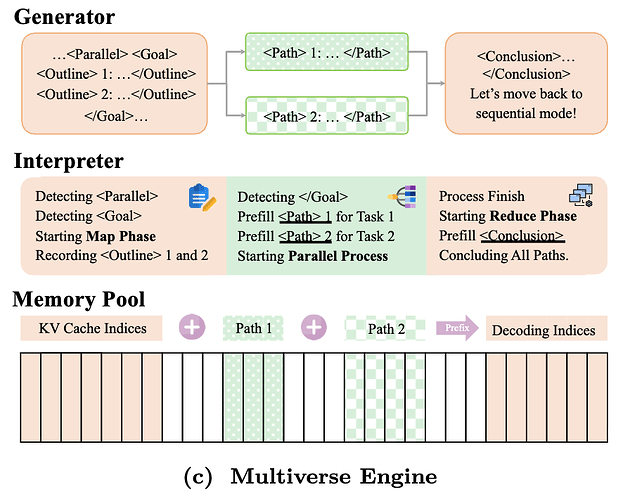
其次,这种方法改变了模型看待序列的方式,从而产生了分布上的变化,而模型并没有经过预训练,因此需要更广泛的训练来调整行为。具体来说,当我们以这种方式拼接 KV 缓存时,我们会创建一个具有非标准位置编码的序列。在独立线程生成过程中,所有线程都从相同的位置索引开始,并关注之前的子任务,而不是彼此。因此,当线程重新合并时,生成的 KV 缓存具有非标准位置编码,并且不使用因果注意。因此,这种方法需要大量的训练才能使模型与这种新行为保持一致。为了解决这个问题,Multiverse(Yang 等人,2025 年)和相关研究在训练过程中应用了改进的注意力掩码,以防止独立线程相互关注,从而使训练和推理行为保持一致。
面对非标准 KV 缓存管理所带来的这些问题,我们能否尝试一种不修改引擎的方法?
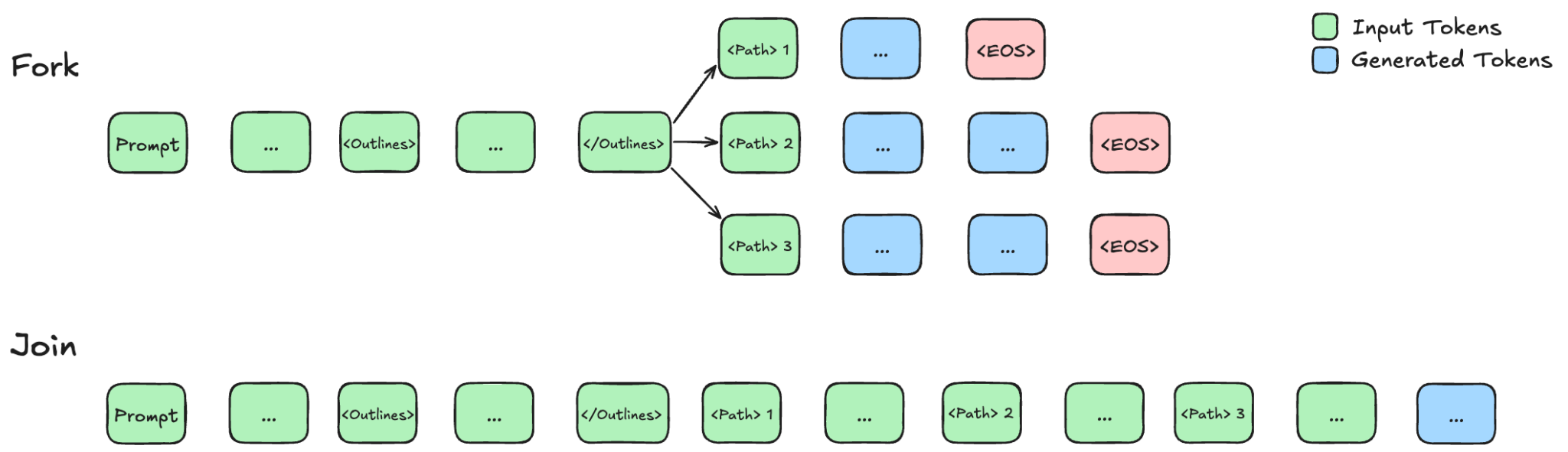
**ThreadWeaver 保持推理引擎不变,将协调工作转移到客户端。**ThreadWeaver(Lian 等人,2025 年)将并行推理纯粹视为客户端问题。分叉 "过程与 Multiverse 的几乎完全相同,但连接阶段对内存的处理方式却截然不同,因为它并不修改引擎内部结构。相反,客户端会将来自独立分支的所有文本输出连接成一个连续的序列。然后,引擎执行第二次预填充,为结论生成步骤生成 KV 缓存。虽然这引入了 Multiverse 竭力避免的计算冗余,但预填的成本明显低于解码。此外,由于第二次预填充使用的是因果注意力(线程之间会相互看到),因此在推理过程中不需要特殊的注意力处理,这使得顺序自回归模型更容易适应这项任务。
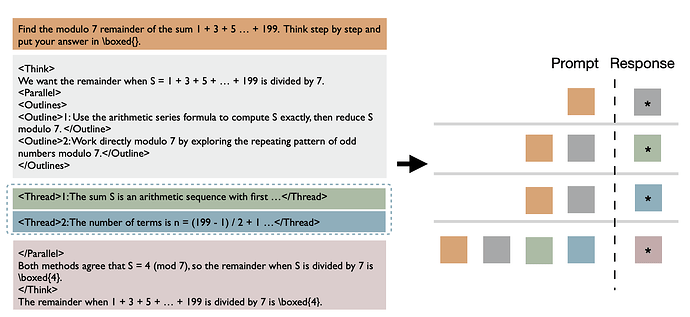
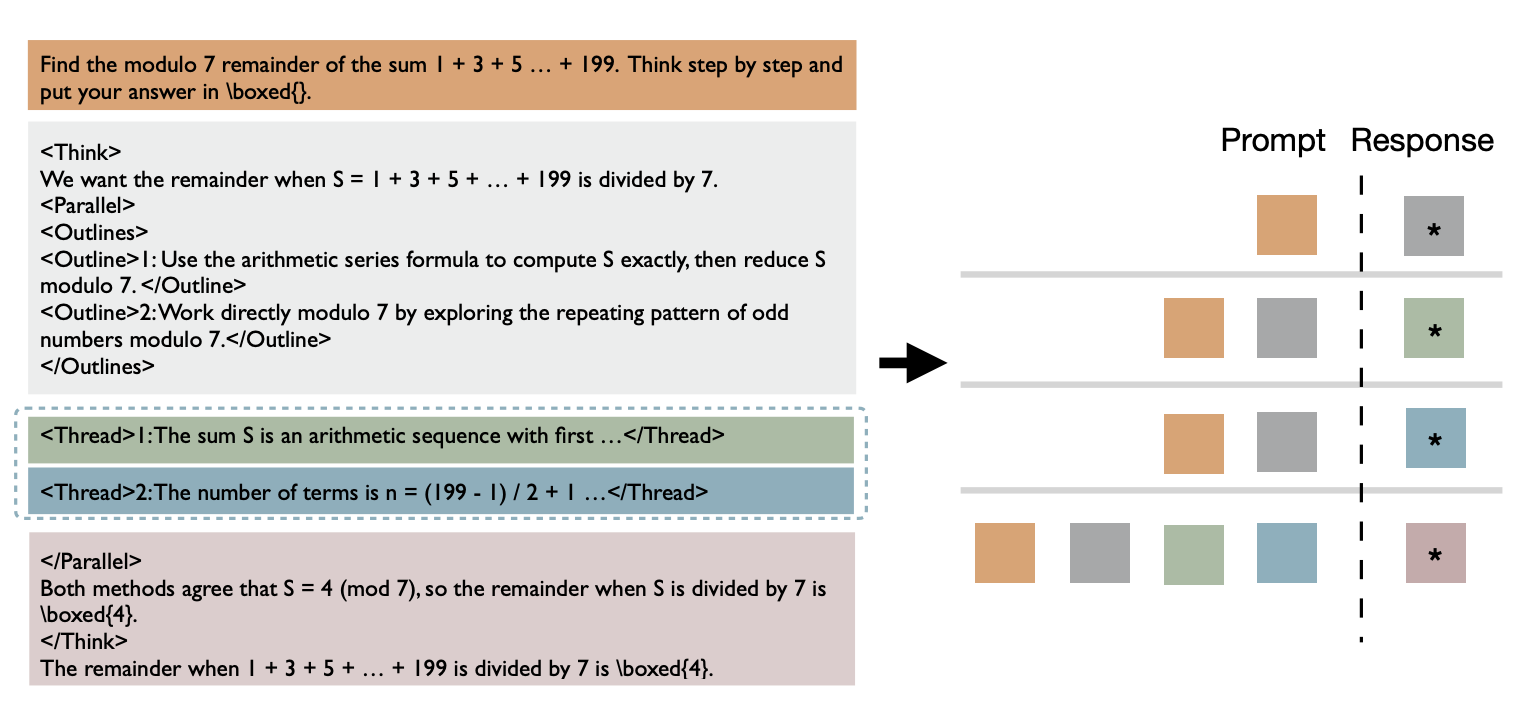
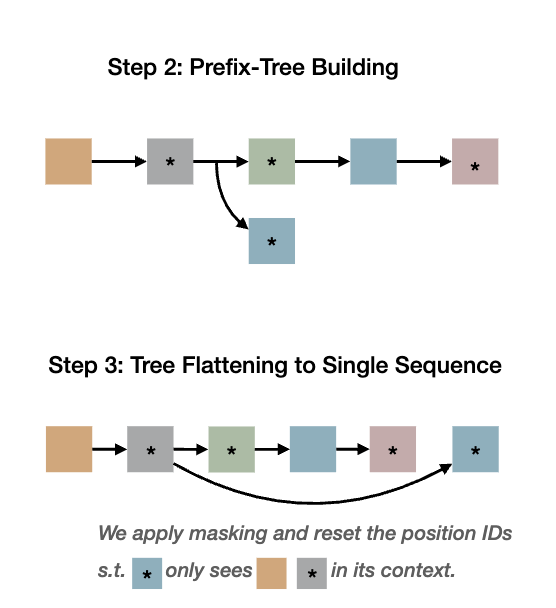
我们应该如何训练模型来学习这种行为呢?简单地说,对于每个并行轨迹,我们可以按照推理模式将其分解为多个连续的部分。例如,我们可以训练模型输出给定提示的子任务、给定提示+子任务分配的单个线程,以及给定提示+子任务+对应线程的结论。然而,这似乎是多余的,而且计算效率不高。我们能做得更好吗?事实证明,可以。就像在 ThreadWeaver(Lian 等人,2025 年)中一样,我们可以将并行轨迹组织成前缀树(trie),将其扁平化为单个序列,并在训练(而非推理!)过程中应用只关注祖先的掩码。
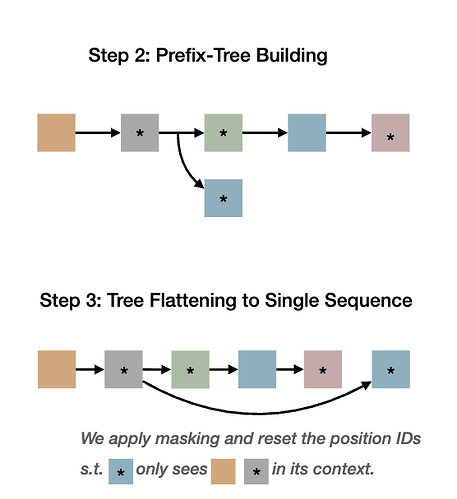
具体来说,我们使用掩码和位置 ID 来模拟推理行为,这样每个线程就只受提示+子任务的制约,而无需关注同级线程或最终结论。
与引擎无关的设计让采用变得容易,因为你不需要另外想办法托管,还可以利用现有的硬件基础设施。随着现有推理引擎的改进,它也会变得更好。更重要的是,有了引擎无关的方法,我们就能提供一种混合模型,在顺序和并行思维模式之间轻松切换。
1 个帖子 - 1 位参与者