不是让 AI 替你读论文,而是让每篇论文都沉淀进知识库:我现在怎么用 Obsidian + Notemd 做论文深读与长期积累
本帖使用社区开源推广,符合推广要求。我申明并遵循社区要求的以下内容:
- 我的帖子已经打上 开源推广 标签:是
- 我的开源项目完整开源,无未开源部分:是
- 我的开源项目已链接认可 LINUX DO 社区:是
- 我帖子内的项目介绍,AI 生成或润色部分已截图发出:是
- 以上选择我承诺长期有效,并接受社区监督:是
以下为项目介绍正文内容,AI生成、润色内容已使用截图方式发出
这两年大家聊 AI 读论文,很多讨论都很热闹,但我自己真正卡住的地方其实不是“怎么让 AI 回答我这篇论文讲了什么”,而是另一件更朴素的事:
我读完一篇论文以后,到底有没有把它沉淀下来?
很多时候,我们在对话框里问了很多问题,AI 也回答得很快。可一周以后再回头看,真正留下来的往往只有一点模糊印象。那篇 paper 的核心概念、方法关系、实验设置、局限性、和我已有知识库的连接,最后还是散的。
所以我后来越来越想把这件事做反一点:不是让 AI 只在对话框里“陪我聊”,而是让它把论文阅读过程中真正有价值的东西,持续写回我的 Obsidian 知识库里。
Notemd 就是在这个思路下比较顺手的一种做法。它不是一个“神奇的一键读懂论文机器”,而是一个把论文笔记、概念卡片、研究摘要、翻译、图表和工作流串起来的 Obsidian 工作台。
如果你本来就在用 Obsidian,或者你也受不了“读了一堆论文,但最后没沉淀下来”的状态,如果你还在受语言对学习效率的制约,这个项目可能刚好适合你。
一句话介绍:
Notemd 是一个开源的 Obsidian 社区插件。它不追求“帮你一键读懂论文”,而是把论文阅读过程里的概念链接、概念笔记、原文证据摘录、背景补充、翻译、图表和工作流,尽量都沉淀回你的知识库里。支持数十种语言的UI、README与转换!
实际阅读状态示例:
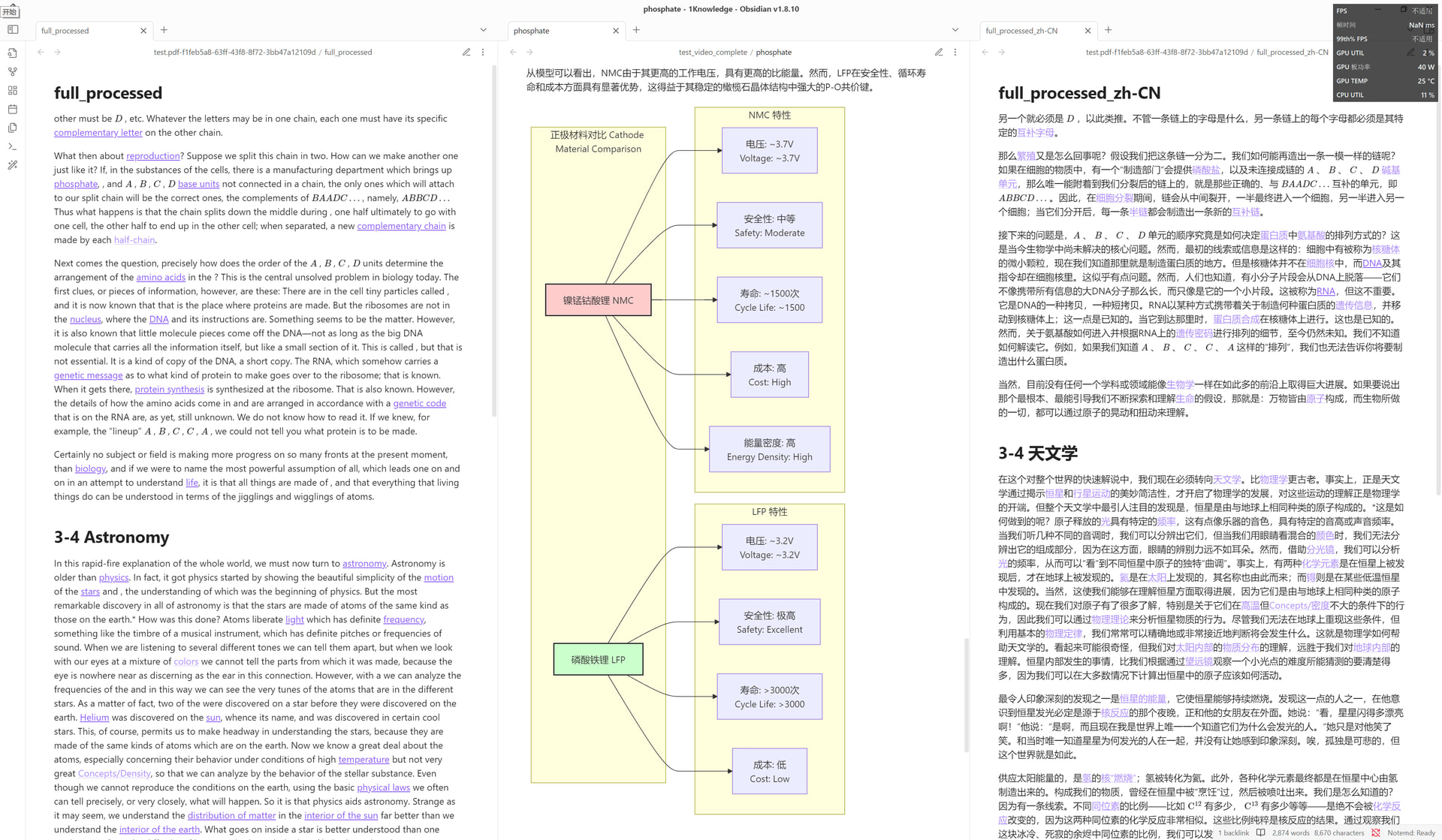
多语言支持:
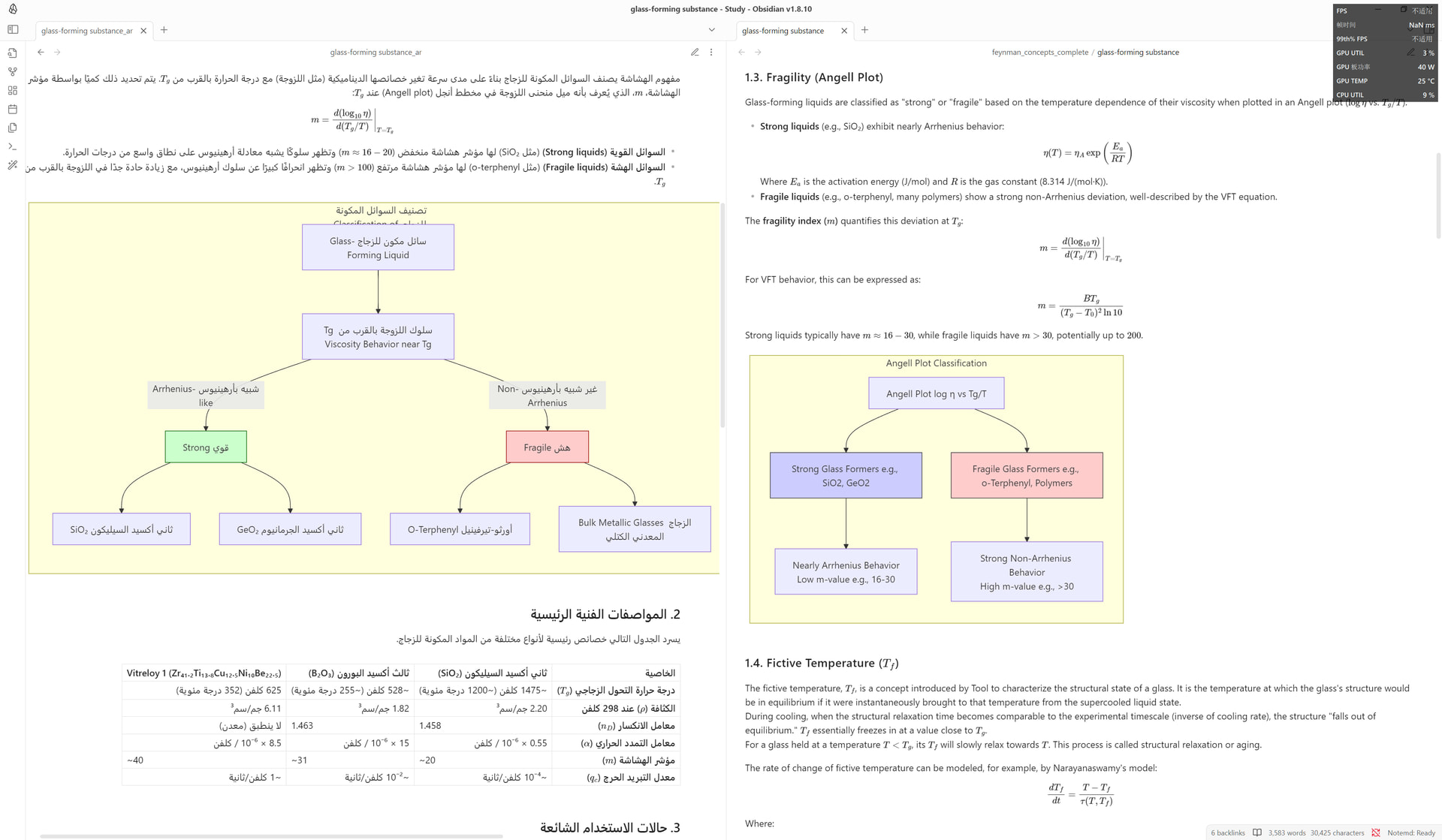
我想解决的,其实不是“读一篇”,而是“沉淀一批”
我现在对“AI 读论文”这件事有个很强的感受:
单次对话很容易,长期积累很难。
你当然可以把 PDF 扔给模型,问它总结、翻译、解释公式、分析贡献。这些都没问题。但科研里真正麻烦的是,论文不是一篇一篇孤立存在的。你读到的每一个术语、方法、数据集、实验范式,理论上都应该慢慢长进你的知识网络里。
我比较想要的是这样一种结果:
- 一篇论文读完以后,关键概念被自动打上
[[wiki-link]] - 新出现的概念可以直接生成概念笔记
- 我关心的问题能从原文里抽出对应证据,而不是只得到一段二手转述
- 背景资料和补充搜索能直接附着到笔记旁边
- 复杂方法链路能被压成 Mermaid 或图表,方便回看
- 这些东西都留在我的 vault 里,而不是散落在不同聊天记录中
Notemd 的价值点,恰恰在这里。它不是替你“看完就算”,而是尽量把阅读过程变成一个可复用、可积累、可回看的知识流。
和常见“聊天式读论文”相比,区别到底在哪
如果要用一句话说区别,大概就是:
聊天式 AI 更擅长当场回答问题,Notemd 更擅长把结果沉淀进知识库。
我比较在意下面这些差异:
维度 聊天式 AI Notemd 核心落点 当前会话 当前笔记和 vault 文件 结果形态 一段回答 链接、概念笔记、译文、图表、日志、工作流产物 适合场景 快速问答、临时解释 长期阅读、积累、复用 主要风险 聊完就散 需要你自己维护知识库结构这两种方式不是互斥关系。我自己也还在用对话式 AI 做即时追问。但如果目标是让今天读过的东西,三周后还能准确召回,文件化、结构化和可回写就很重要。
结构化总结:
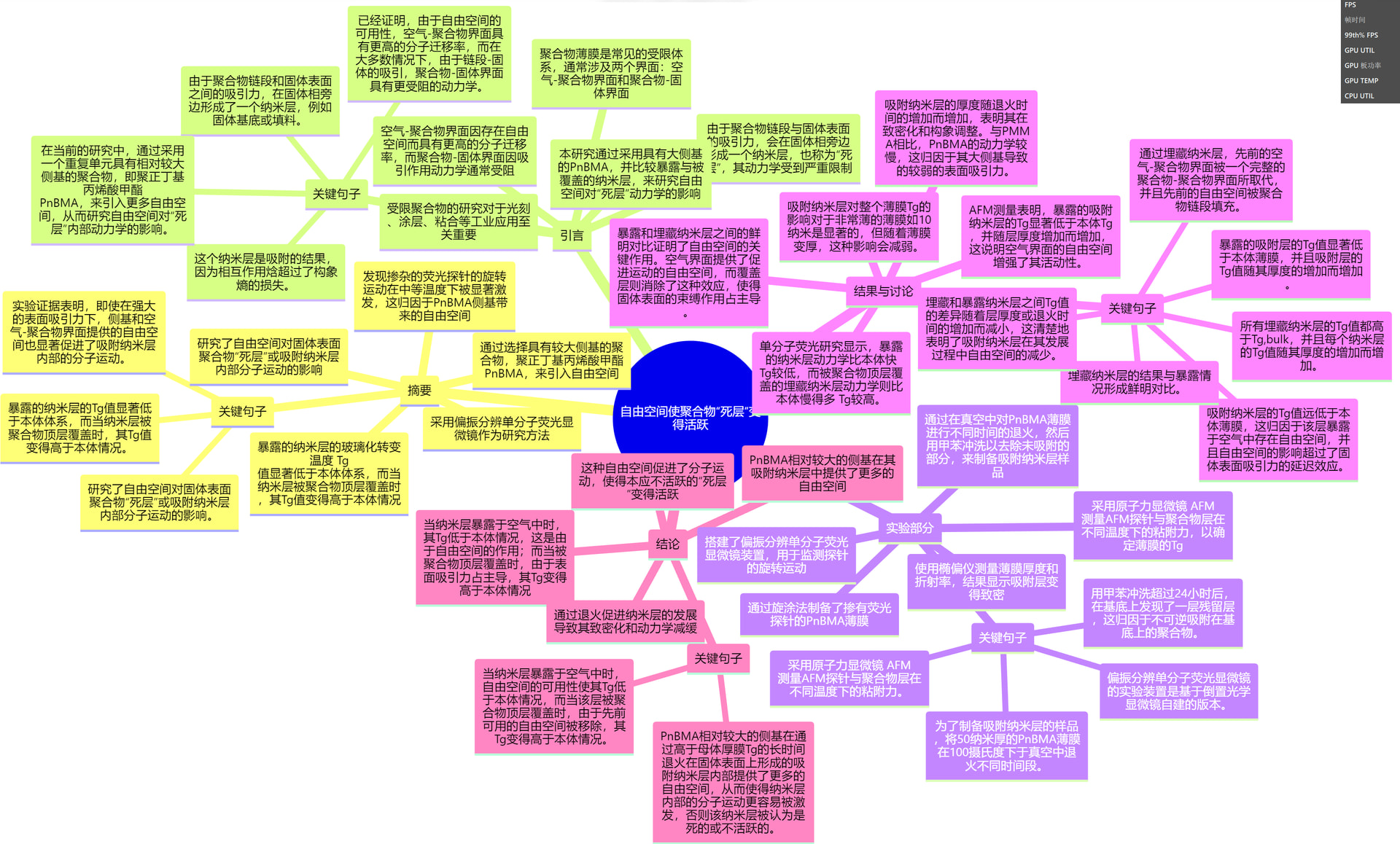
我现在比较顺手的一套论文工作流
先说前提:Notemd 目前处理的是 Markdown / txt 内容,不是直接载入 PDF。这个边界我觉得反而挺重要,因为它会让整个流程更干净,并且MD是AI的原生语言。
我现在一般会这样走:
1. 先把 PDF 变成 Markdown
比如用 MinerU 之类的工具先做 PDF → Markdown 转换,再把结果放进 Obsidian。(当前MinerU在目前的免费软件里使用起来解析质量高且速度较快)
这样做的好处很直接:
- 原文结构更清晰
- 后续链接、翻译、提取、图表都能围绕同一份 Markdown 笔记发生
- 你的“论文阅读结果”从一开始就是知识库资产,而不是临时输入
这一步很关键。因为后面所有自动化,都是建立在“原文已经进入你的知识库工作台”这个前提上的。
2. 先做概念链接,再做概念沉淀
导入 Markdown 以后,我一般先跑两类动作:
处理文件(添加链接)| Process file (add links)从标题批量生成| Batch Generate from Title
前者会把论文里的关键概念补成 [[wiki-links]],后者则可以借助高质量AI(比如Gemini-3.1-pro)把每个具体的概念扩充为深入的领域知识与术语间的关系总结,而且这是支持调用搜索api(比如Tavily)进行定向高质量搜索后生成。
这对论文阅读特别有用。因为很多时候,一篇 paper 真正难的不是某个公式,而是里面塞了太多默认你“已经知道”的术语。比如某个 backbone、某种训练范式、某个 benchmark、某个统计指标。如果这些概念每次都是临时去查,那你永远在重复补课。
我更喜欢让它们直接长成卡片,沉淀到固定的概念文件夹里。后面再读第二篇、第三篇相关论文时,这些概念会越来越完整,而不是每次都重新认识一遍。
如果你愿意,还可以把概念日志也打开。这样每次跑完以后,新增了哪些概念,会有一个很直观的落地记录。
我已经将这套流程固化为一键处理按钮,不需要拆解单独执行(但需要注意tokens消耗),最大化便利佬友们使用。

3. 用“提取特定原始内容”做证据导向的精读
这个功能我觉得很适合论文深读,而且容易被低估。
你可以预先在设置里定义一组问题,比如:
- 这篇论文的核心贡献是什么?
- 作者怎么定义问题?
- 实验设置是什么?
- 主要 baseline 有哪些?
- 作者明确承认了哪些 limitation?
然后让插件从当前论文里逐字提取对应原文片段。
这一点和普通摘要很不一样。摘要是模型理解后的转述,而“提取特定原始内容”更像是在做证据定位。你最后拿到的是更贴近原文的依据,适合拿来做精读笔记、组会汇报、或者后续写 related work 时快速回查。
如果你平时最怕的是“AI 讲得很像那么回事,但我找不到它到底依据了原文哪一句”,那这个功能会比一味让模型总结更稳。
4. 不懂的背景,直接接上 Research & summarize
论文阅读经常会碰到一种情况:文章本身只讲了 20%,剩下 80% 的背景默认你已经知道。
这时候我通常不会立刻跳出 Obsidian 去开十几个网页,而是直接在当前笔记旁边做 Research & summarize。
它会调用配置好的搜索服务和 LLM,把主题相关的补充信息整理出来,再附加回当前笔记。这样做的好处是:
- 背景知识不会飘在浏览器里
- 你查过什么,会和当前 paper 绑在一起
- 后面回看时,不只看到论文本身,还能看到你当时补了哪些上下文
我自己更把这个功能当作“补背景”和“补术语网络”,而不是拿它直接替代正式文献检索。尤其在做课题早期扫盲时,它能明显降低阅读门槛。
5. 英文精读压力大时,直接翻译,但翻译结果也要回到库里
很多人用 AI 翻译论文,最大的问题不是翻译质量,而是翻译完以后内容又留在一个临时界面里,跟你的笔记体系断开了。
Translate current file 这个链路我喜欢的地方在于,它不是单次翻译一下就结束,而是把结果作为 Obsidian 里的另一份产物保存下来。而且成功后会直接打开在侧边栏
对双语知识库用户来说,这很舒服。原文、译文、概念卡片、研究摘要都能在一个 vault 里互相引用,不需要来回搬运。
而且 UI Locale 和 Task Output Language 是分开的。界面可以跟着 Obsidian 走中文,但任务输出可以保持英文,或者反过来按你的需要配置。这一点对科研场景挺实用。
给一个效果图,内容摘选自feynmann的物理学讲义:
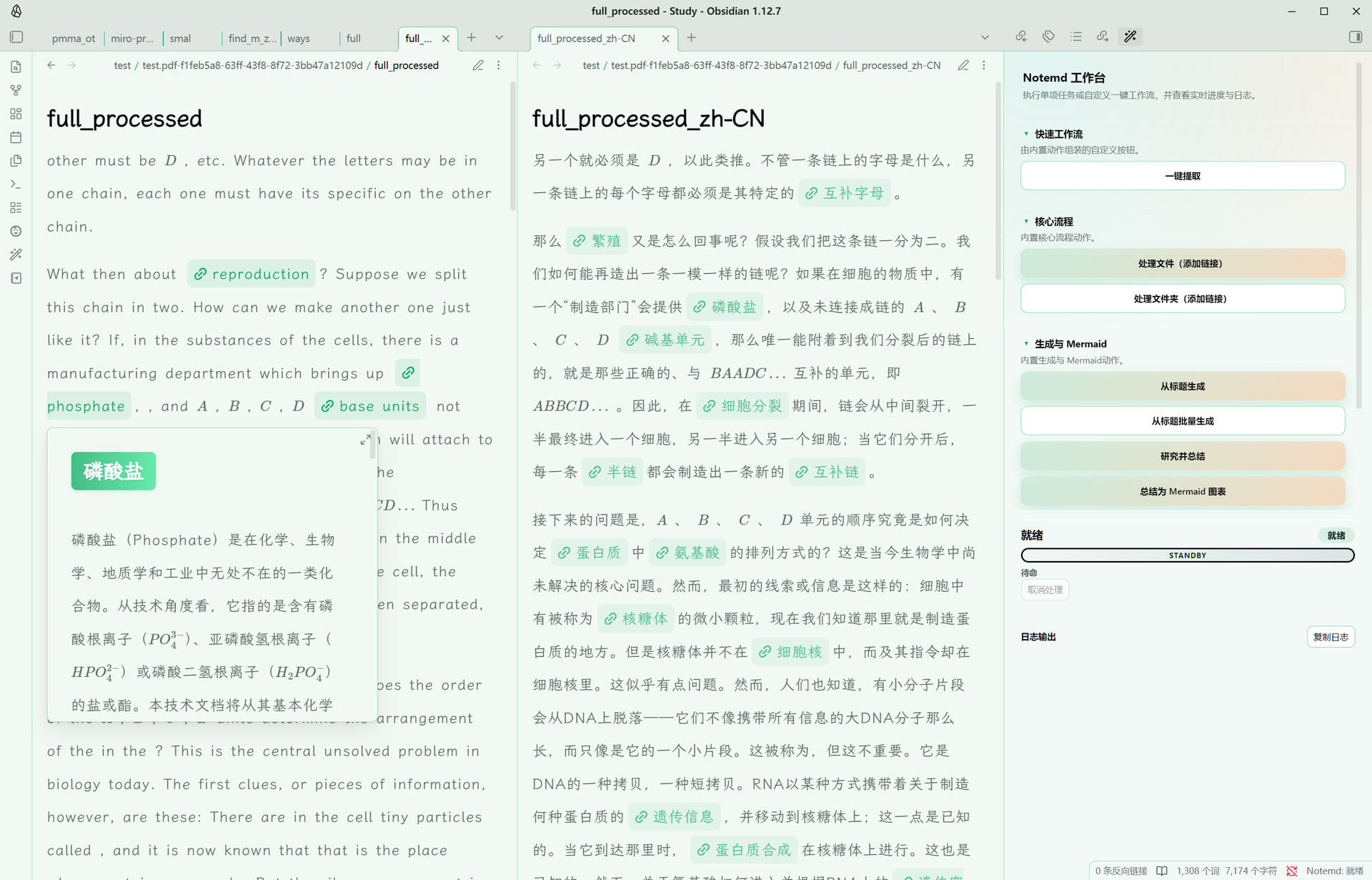
6. 最后把理解压缩成图
论文读到后面,很多时候不是“我没看过”,而是“我脑子里有一团东西,但还没压成结构”。
这时候我一般会做两类事:
Summarise as Mermaid diagramGenerate diagram (experimental)
前者更适合方法流程、模块关系、因果链路这类结构化内容;后者在当前版本里已经能走到 Mermaid、JSON Canvas 和 Vega-Lite 这几条图表路径,其中 dataChart 还可以用 Vega-Lite 做更规整的数据图。
我很喜欢把图当成“理解压缩层”。不是因为图一定比文字高级,而是因为当你开始要求 AI 把一篇论文画成流程图、关系图或数据图时,它必须对结构做一次显式整理。你自己在检查图的时候,也更容易一眼发现哪里不对。
当然,这里一定要说一句实话:图不是事实本身。AI 生成的图,尤其是科研图,只适合当草图、摘要层和检查层,不适合不经核对就直接当最终结论。
如图1.8.4最新版支持众多种类图的生成:
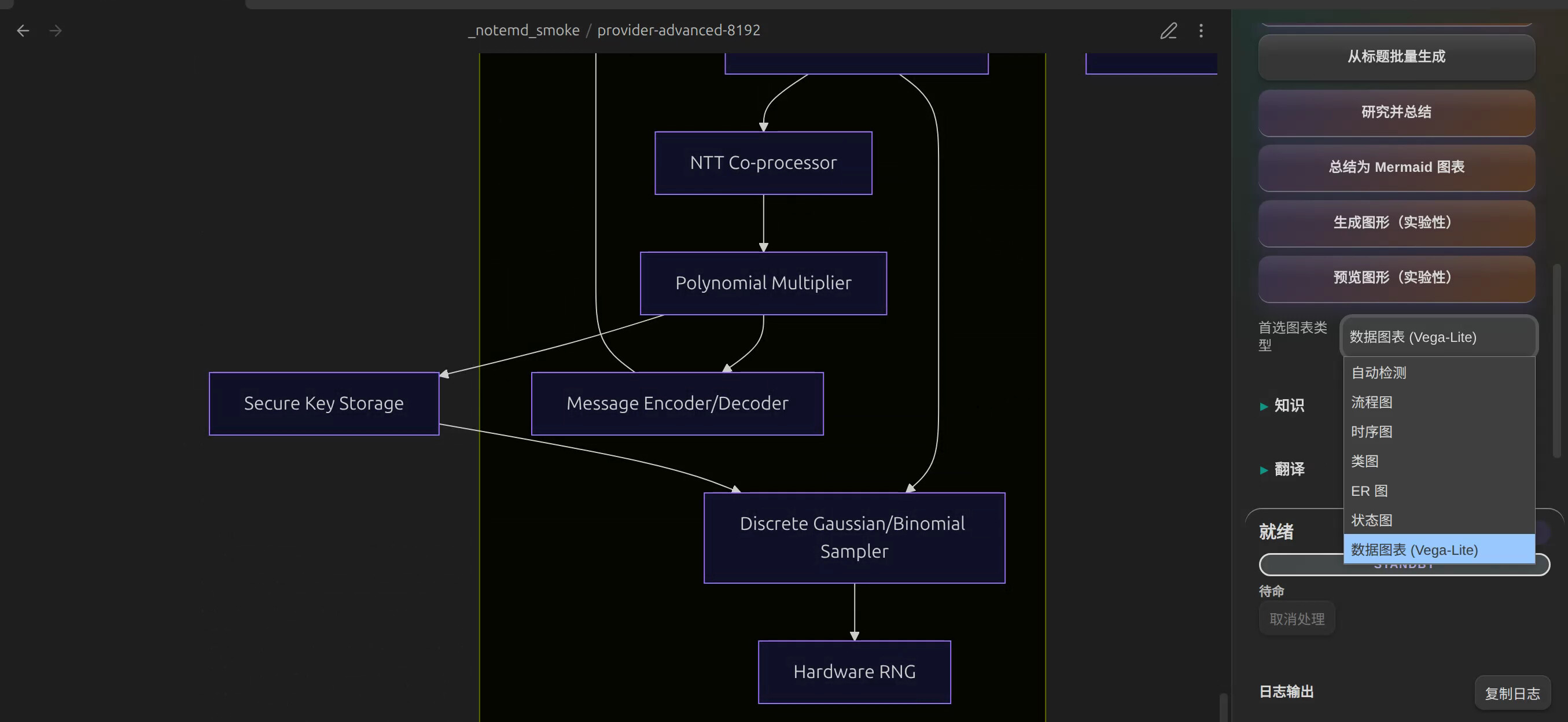
这里给一些举例:
Mermaid正常图:

时序图:
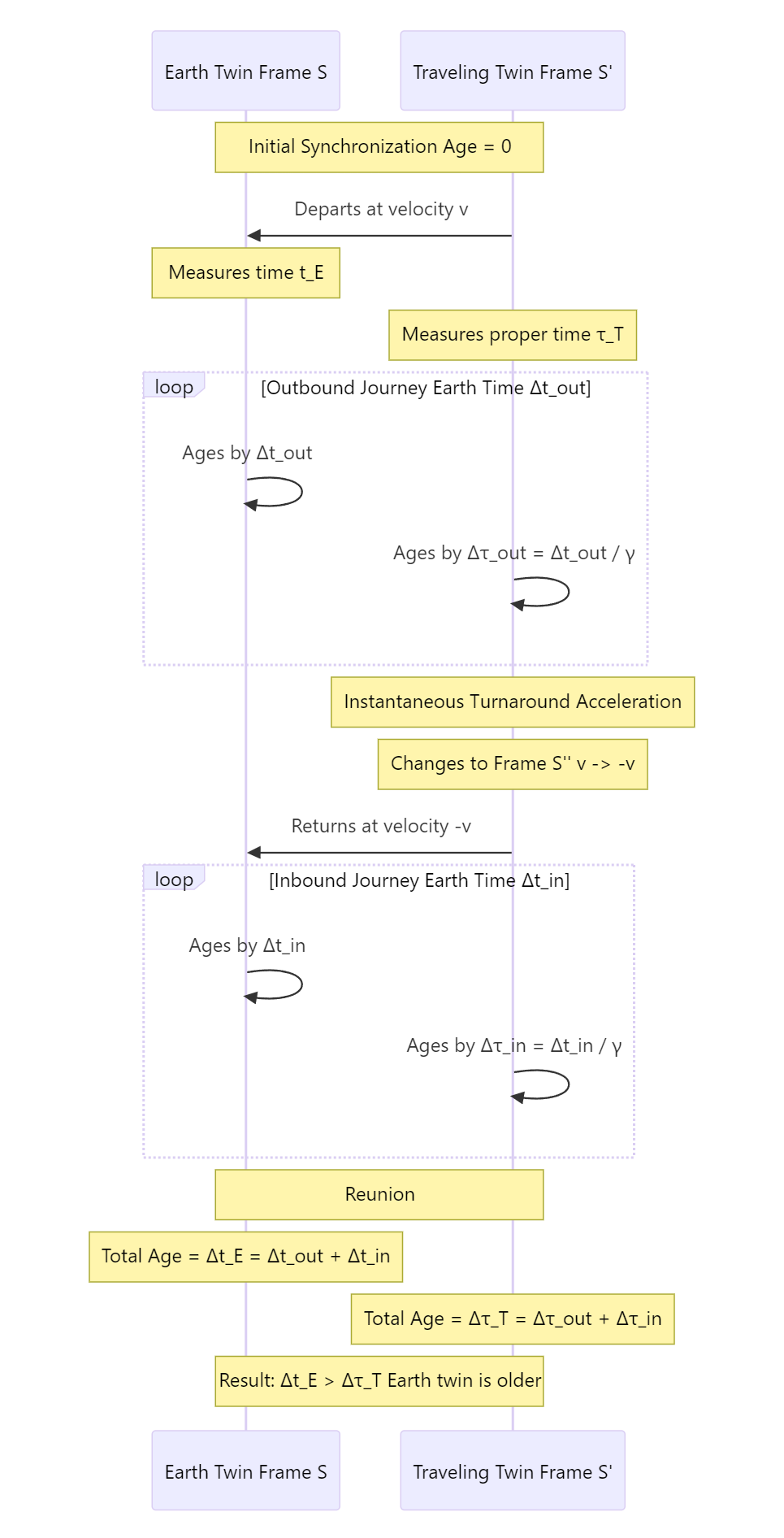
7. 最后用工作流把这些动作串起来
如果上面这些动作每次都手动点一遍,久了还是会烦。所以 Notemd 里我很喜欢的另一个点是:你可以把常用动作编成自己的 One-Click Workflow。
默认就有一个 One-Click Extract,会把几个动作串起来跑。除此之外,你也可以按自己的论文习惯重组,比如:
论文入库::process-current-add-links>extract-concepts-current>research-and-summarize>summarize-as-mermaid
在设置中有非常高度自定义工作流的支持:
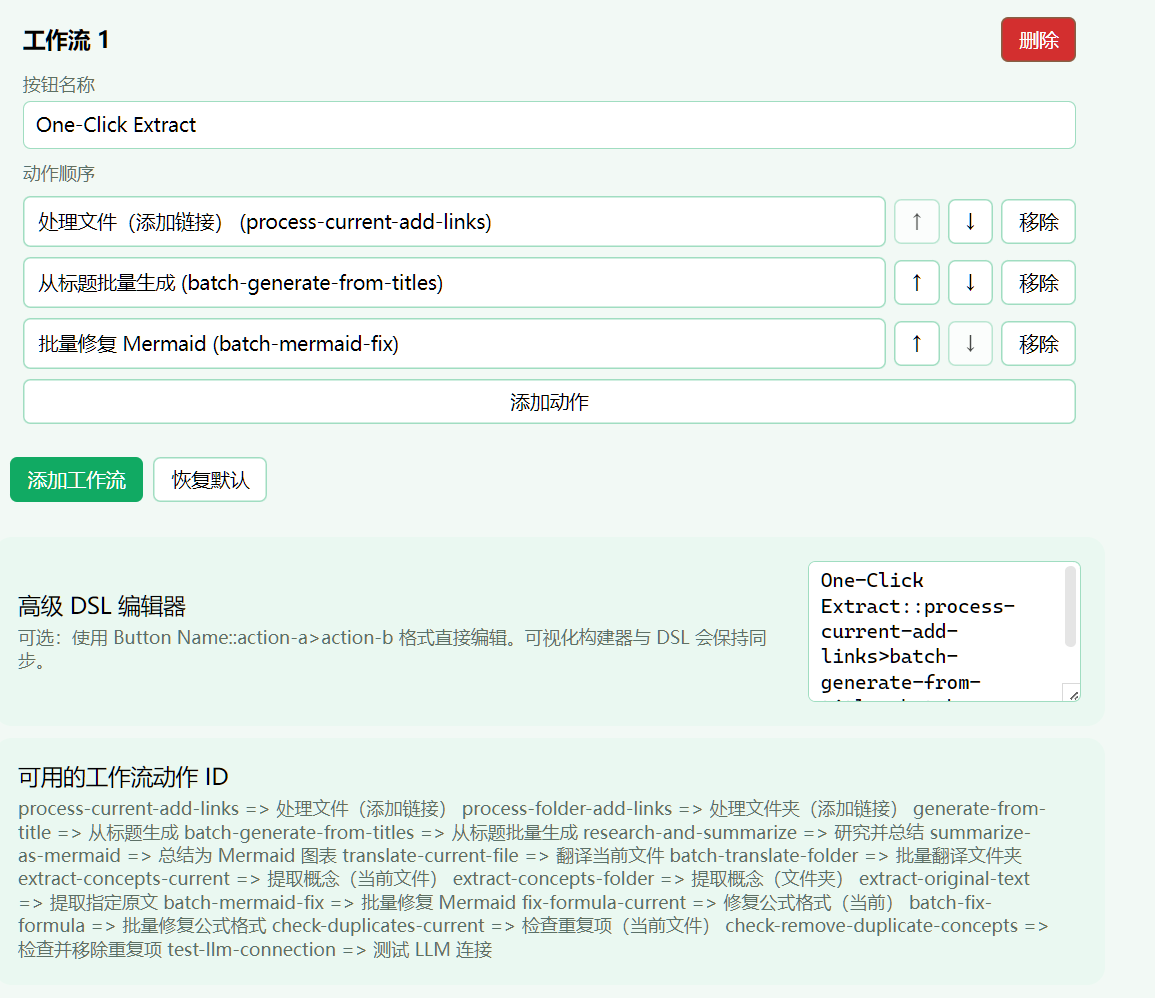
对我来说,这种工作流的意义不是“省一次点击”,而是把自己的阅读习惯固化下来。你跑得越多,知识库结构越稳定,后面的复用价值越高。
为什么我觉得它适合分享给佬友
我觉得这个项目比较贴 linux.do 社区气质,主要是因为它不是单纯演示模型效果,而是更偏实际工作流:
- 完整开源。不是云端黑盒,也不是只放截图不放代码。
- 模型选择自由。支持 OpenAI、Anthropic、Google、DeepSeek、Qwen、Ollama,以及通用
OpenAI Compatible网关。 - 不同任务可配不同模型。链接、研究、翻译、生成可以分开选 provider 和 model。
- 每个任务都支持prompt修改。自定义prompt功能给这个插件留下了充分的扩展性与可玩性
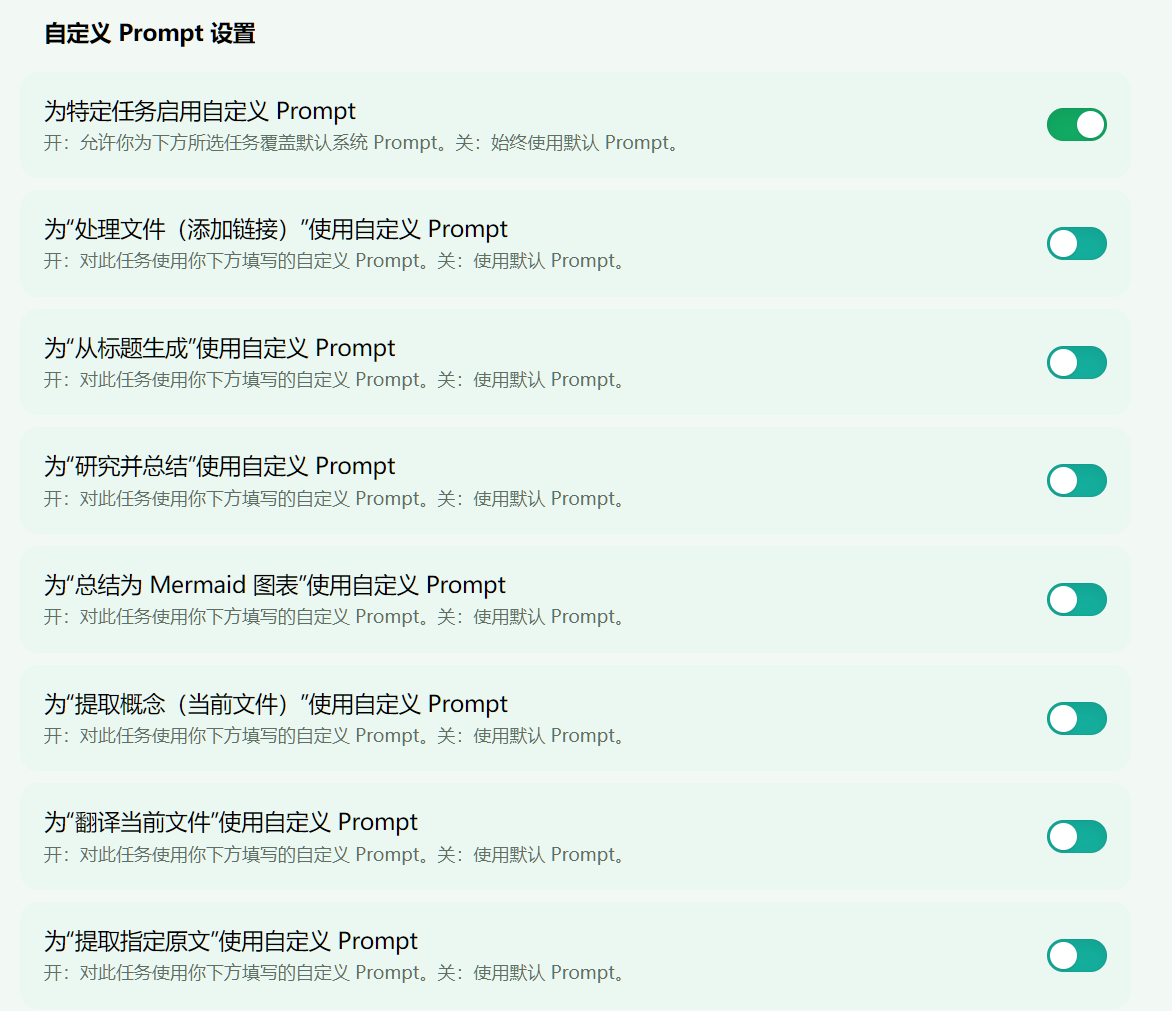
- 结果落在文件里。不是只有一段临时回答,而是能留下链接、概念笔记、译文、图表和日志。
- 对本地用户友好。如果你本来就在用 Obsidian,它几乎就是往现有工作台里加了一层 AI 能力,而不是要求你换一整套笔记体系。
边界和实话
最后还是要把边界说清楚,免得写成一篇“看起来什么都能做”的宣传稿。
Notemd现在不是直接读 PDF 的工具,推荐先做 PDF → Markdown。Research & summarize适合补背景,不是正式文献检索系统的替代品。- 图表生成功能适合做草图和结构压缩,不适合替代严肃核对。
- 它不能替你完成真正的理解。方法假设、实验边界、指标含义、反例和局限性,最后还是得回到原文。
所以我更愿意把 Notemd 当成一个“理解增强器”,而不是“理解外包器”。
适合哪些人
- 已经在用 Obsidian 管理读书或论文笔记的人
- 读论文量比较大,想把零散理解慢慢织成网络的人
- 不满足于“总结一下”,而是想保留概念、证据、图表和上下文的人
- 想把翻译、搜索、概念提取、图表生成收敛到一个工作台里的人
- 对模型选择有要求,想自由切换云端和本地模型的人
如果你只是偶尔看一两篇 paper,或者你本来就不想维护知识库,那它也能帮助你快速翻译与核心概念提取,易于上手。这个项目能帮助你长期积累自己的"知识星球",构建自己的知识护城河。
安装
如果只是想先试一下:
- Obsidian 社区插件里直接搜索
Notemd - 或者去 GitHub 仓库看源码和 release
项目地址:
- GitHub: notemd github项目
- Obsidian Community Plugin: 搜索
Notemd
如果大家感兴趣,后面我还可以再单独整理一篇更偏实操的帖子,专门讲:
- 我怎么配置提取问题模板
- 如何配置prompt兼容任何领域
如果觉得喜欢有所收获就支持一下吧!
 credit.linux.do
credit.linux.do
LINUX DO Credit
Linux Do 社区积分服务平台
6 个帖子 - 3 位参与者