好几周前就听说了v4要出,我用过文心、千问、minimax和glm等,比较好用的也就glm5了,平常还是gpt和cc用的多。我同事是坚定的国产模型拥护者,上班一直给我吹v4有多么牛,我先前用过ds v3,吐token是挺快,但是幻觉率挺高。
昨天充了5块,改了下配置文件直接用deepseek-v4-pro了。
{
"env": {
"ANTHROPIC_BASE_URL": "https://api.deepseek.com/anthropic",
"ANTHROPIC_AUTH_TOKEN": "sk-xxxxxxxxxxxxxxx",
"ANTHROPIC_DEFAULT_OPUS_MODEL": "deepseek-v4-pro[1m]",
"ANTHROPIC_DEFAULT_SONNET_MODEL": "deepseek-v4-pro[1m]",
"ANTHROPIC_DEFAULT_HAIKU_MODEL": "deepseek-v4-flash[1m]",
"CLAUDE_CODE_EFFORT_LEVEL": "max",
"API_TIMEOUT_MS": "3000000",
"CLAUDE_CODE_DISABLE_NONESSENTIAL_TRAFFIC": "1",
"CLAUDE_CODE_ATTRIBUTION_HEADER": "false"
},
"model": "opus[1m]",
"skipDangerousModePermissionPrompt": true
}
写了个时钟网页,对比下看起来还不错:
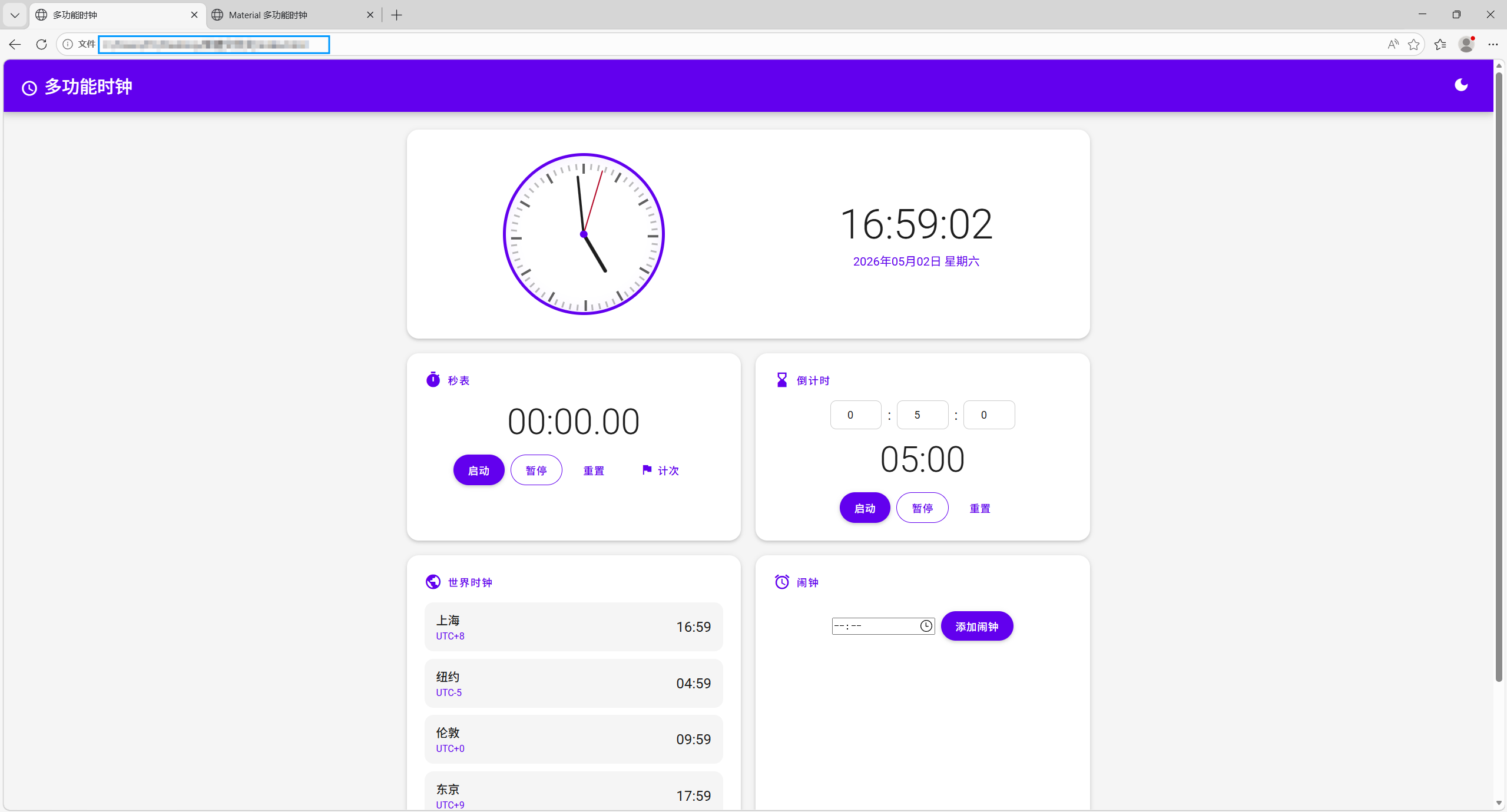
有点不敢相信是 DeepSeek 写的,怀疑是 Claude Prompt 发力了,然后整了个 Python 脚本直接 Raw 输出
import json, time, requests
API_KEY = "sk-xxxxxxxxx"
BASE_URL = "https://api.deepseek.com/anthropic"
MODEL = "deepseek-v4-pro[1m]"
PROMPT = "写个在线时钟网页,要求有多功能,使用 Material Design,不准联网搜索。把所有代码写在一个 HTML 文件里,直接可用。"
print(f"正在调用 DeepSeek Anthropic API ...")
print(f" Endpoint: {BASE_URL}/v1/messages")
print(f" Model: {MODEL}")
start = time.time()
resp = requests.post(
f"{BASE_URL}/v1/messages",
headers={
"x-api-key": API_KEY,
"anthropic-version": "2023-06-01",
"Content-Type": "application/json",
},
json={
"model": MODEL,
"max_tokens": 32768,
"messages": [
{"role": "user", "content": PROMPT}
],
},
timeout=180,
)
elapsed = time.time() - start
print(f"HTTP {resp.status_code} | 耗时 {elapsed:.1f}s")
# 保存完整原始响应
with open("raw_response.json", "w", encoding="utf-8") as f:
f.write(resp.text)
print(f"原始响应已保存到 raw_response.json ({len(resp.text)} 字符)")
if resp.status_code == 200:
data = resp.json()
# 找到 text 类型的 content block(跳过 thinking block)
text_blocks = [b for b in data["content"] if b["type"] == "text"]
content = text_blocks[0]["text"] if text_blocks else "[无文本输出]"
usage = data.get("usage", {})
print(f"Tokens: input={usage.get('input_tokens')}, output={usage.get('output_tokens')}")
print(f"Stop reason: {data.get('stop_reason')}")
# 提取 HTML
html = content
if "```html" in content:
html = content.split("```html")[1].split("```")[0].strip()
elif "```" in content:
parts = content.split("```")
if len(parts) >= 2:
html = parts[1].strip()
with open("raw_output.html", "w", encoding="utf-8") as f:
f.write(html)
print(f"HTML 已保存到 raw_output.html ({len(html)} 字符)")
else:
print(f"错误: {resp.text[:500]}")
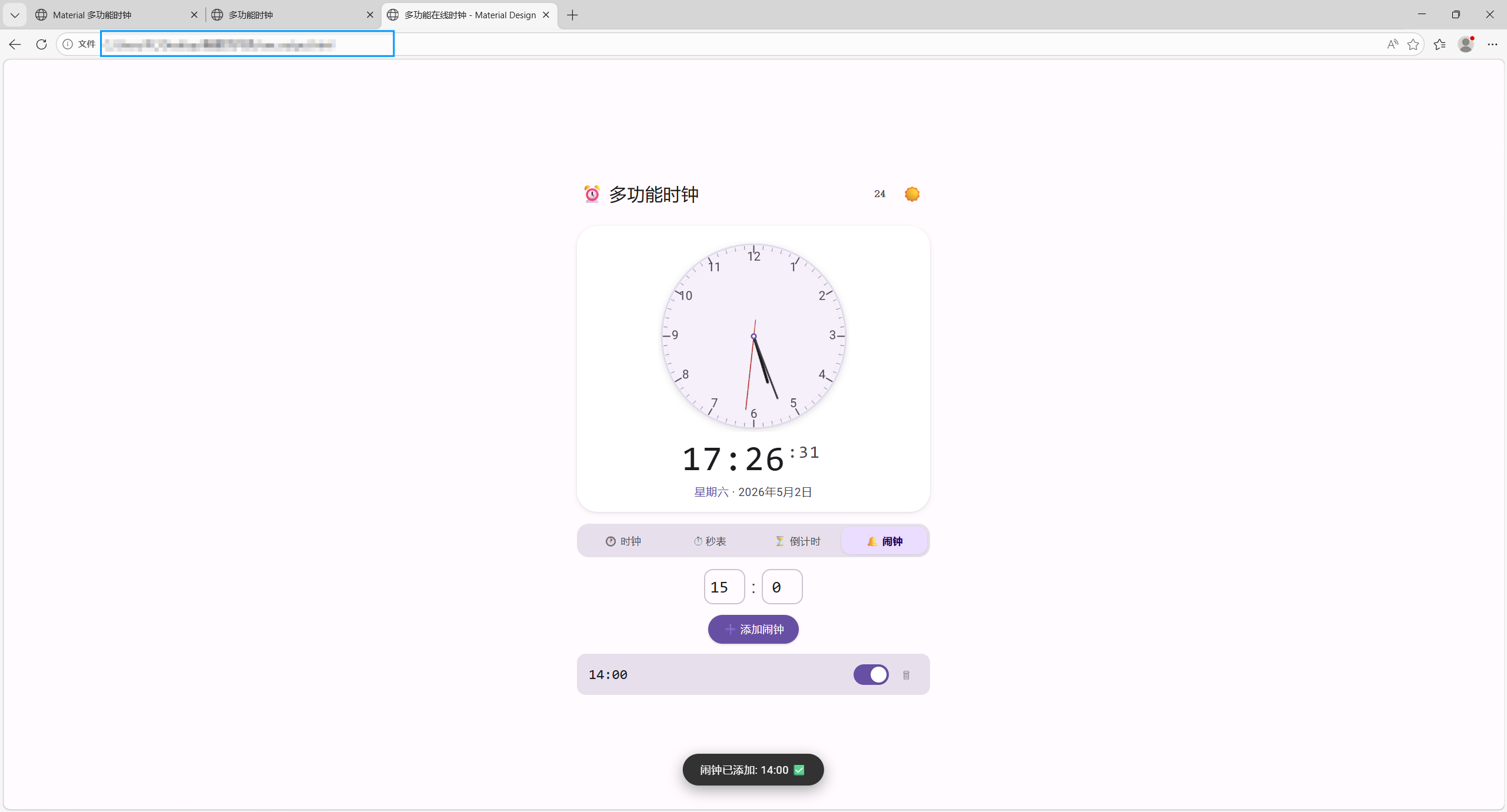
byd 怎么写的更好了
14 个帖子 - 6 位参与者
来源: linux.do查看原文