DeepSeek联合北京大学、清华大学发布论文《Thinking with Visual Primitives》及其开源仓库,提出一种新的多模态推理框架。该框架的核心做法是将空间标记——坐标点和边界框——提升为模型思维链中的“最小思考单元”,在推理过程中直接交织使用,使模型在"思考"的同时能够"指向"图像中的具体位置。
github.com
GitHub - deepseek-ai/Thinking-with-Visual-Primitives
通过在 GitHub 上创建帐户来为 deepseek-ai/Thinking-with-Visual-Primitives 开发做出贡献。

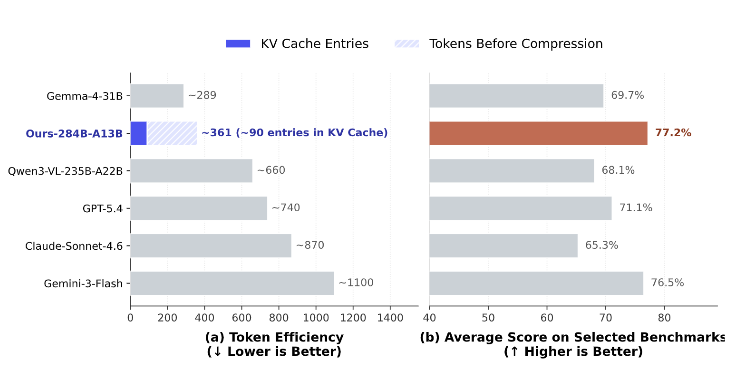
在7项公开基准和4项自建基准的评测中,该模型在计数、空间推理、拓扑推理等维度上达到或超过GPT-5.4、Claude-Sonnet-4.6和Gemini-3-Flash的表现,平均得分77.2%,为所有被测模型中最高。值得关注的是,在迷宫导航和路径追踪两项拓扑推理任务上,该模型分别取得66.9%和56.7%的准确率,而其余前沿模型均未超过51%,这表明现有多模态模型在拓扑推理方面仍有很大提升空间。
论文同时指出了当前的局限:受限于输入分辨率,模型在细粒度场景中的视觉原语输出偶有偏差;视觉原语思考能力目前依赖显式触发词激活,尚不能由模型自主判断何时启用;以坐标点解决复杂拓扑推理的跨场景泛化能力也有待增强。
6 个帖子 - 4 位参与者
来源: linux.do查看原文