刷抖音看到一个博主,跟我部分观点高度重合,干脆直接搬运他的原文过来。相同的部分不再重复,看他的就行;下面只放我自己的补充。
博主名字:程意
博主原文 (点击了解更多详细信息)中国 AI 正式从被卡脖子进入到自身产能爬坡的拐点
虽然 V4 本次实际训练仍是英伟达 + 昇腾的混合方案,V4 技术报告本身(§3.1)已经直接证明:DeepSeek 的训练栈是硬件无关的——同一套 fine-grained EP 方案在英伟达 GPU 和华为昇腾 NPU 上都跑通并 benchmark 过,达到同等的 1.5–1.96× 加速比。这意味着后续从零预训练 V5/V6,完全在华为昇腾上做不存在任何技术约束,只剩产能约束。

本段翻译:
性能与开源巨型内核。 我们在 NVIDIA GPU 和华为昇腾 NPU 平台上验证了细粒度 EP 方案。与强大的非融合基线相比,该方案在一般推理工作负载下实现了 1.50 至 1.73 倍的加速,在诸如强化学习部署和高速代理服务等对延迟敏感的场景下,加速倍数最高可达 1.96 倍。我们已将基于 CUDA 的巨型内核实现 MegaMoE2 作为 DeepGEMM 的一个组件开源。
这一段的工程含义是:DeepSeek 训练系统里最核心、最复杂、最依赖硬件特性的那部分(专家并行的通信-计算融合 kernel),在算法和接口层面已经和具体硬件解耦——它在 NVIDIA Hopper SM 架构和 Ascend Da Vinci 架构上用同一套设计跑出同一档性能。
从 V4 技术报告内在内容可以直接推导出以下三点:
(1) 训练系统层面已经硬件无关——§3.1 明示在英伟达和昇腾两个平台跑通同等性能的 fine-grained EP 方案。这是训练框架最核心的部分,最核心都跑通了,外围(数据加载、优化器、checkpointing 等)只会更通用。
(2) DeepSeek 在论文层面就把硬件抽象掉了——§3.1 后半段直接给硬件厂商列指标,§4.2.2 训练设置整段不提硬件。这是叙事策略,也是事实陈述:硬件可替换。
(3) FP4 路径明确指向未来昇腾硬件——报告原文:“the peak FLOPs for FP4 × FP8 operations… can theoretically be implemented to be 1/3 more efficient on future hardware”。这里的 “future hardware” 在产业语境下精准对应昇腾 950DT(FP4 原生支持,4 PFLOPS FP4,Q4 2026)。
V4 技术报告本身就证明了"后续可以完全摆脱英伟达",这不需要等条件成熟、不需要等华为侧再适配,技术报告里的事实陈述就是证据。
DeepSeek 现在还在用英伟达,是因为:
(1) 2024 年禁运前的 H800 库存沉没成本要利用;
(2) 昇腾 950DT 要等到 Q4 2026;
(3) 当前 token-per-dollar 最优解就是双轨混合。这三点全都是商业决策因素,不涉及任何技术不可行性。
DeepSeek 和华为昇腾让中美第一次站到对等的瓶颈面前——海外"有卡缺基建" vs 中国"缺卡有基建",谁先解开谁赢

信息来源:
https://rmi.org/pjms-speed-to-power-problem-and-how-to-fix-it/
https://newsletter.semianalysis.com/p/are-ai-datacenters-increasing-electric
https://www.tomshardware.com/tech-industry/artificial-intelligence/half-of-planned-us-data-center-builds-have-been-delayed-or-canceled-growth-limited-by-shortages-of-power-infrastructure-and-parts-from-china-the-ai-build-out-flips-the-breakers
https://www.tomshardware.com/tech-industry/artificial-intelligence/half-of-planned-us-data-center-builds-have-been-delayed-or-canceled-growth-limited-by-shortages-of-power-infrastructure-and-parts-from-china-the-ai-build-out-flips-the-breakers
https://www.datacenterdynamics.com/en/news/oracleopenai-drop-plans-to-expand-flagship-abilene-stargate-site-meta-in-talks-to-pick-up-crusoe-capacity-with-nvidias-help/
https://www.datacenterdynamics.com/en/news/lawsuit-launched-against-musks-xai-over-illegal-gas-turbines-at-memphis-data-center/
https://earthjustice.org/press/2026/xai-sued-for-illegal-power-plant
https://fortune.com/2026/03/27/meta-hyperion-10-gas-power-plants-louisiana-entergy/
https://www.datacenterdynamics.com/en/news/microsoft-cancels-up-to-2gw-of-data-center-projects-says-td-cowen/

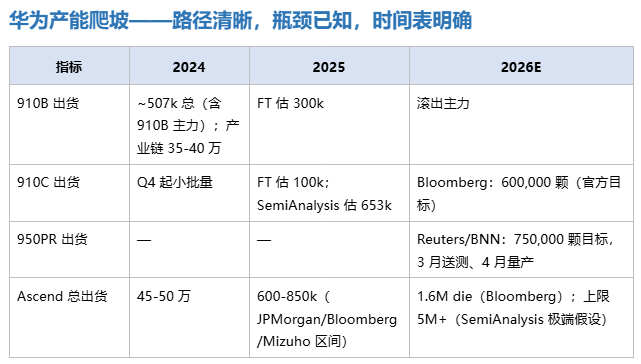
美国的瓶颈是结构性的(电网、土地、监管),中国的瓶颈是周期性的(产能爬坡)——前者解决要 5-10 年甚至无解,后者要 12-24 个月。 但更关键的转变发生在中国侧:V4 之前,中国缺的是被美国锁死的英伟达卡——那是没有解的死结,钱解决不了、时间也解决不了;V4 之后,中国缺的是华为自家的产能——那是有时间表的工程问题。这不是程度的缓解,是性质的转变——从被外部锁死,变成等自己爬坡。死结换成了时钟。 中国 AI 不是和美国"被拉到同一起跑线",而是第一次走出了"根本不在跑道上"的位置——从这一刻起,剩下的只是产能爬坡的时间问题,不再是是否被卡脖子的生存问题。

本文部分内容使用 AI 润色,AI 润色后的部分已换为截图,但全文观点均由本人提出
5 个帖子 - 4 位参与者