用户上传、拖拽图片:
用户上传图片/拖拽图片到指定位置(通过 或JavaScript 事件(如 ondrop)捕获文件),然后生成唯一的一个upload_id。前端将图片封装为multipart/form-data 格式,并且附加 upload_id 作为查询参数
Request URL:https://khang119966-deepseek-ocr-demo.hf.space/gradio_api/upload?upload_id=wbtrc1mgpde
Request Method:POST
Status Code:200 OK
同时触发上传进度监控,浏览器定时发送 GET 请求查询进度(项目中使用WebSocket实时监控),根据进度更新 UI(如显示进度条、百分比)
Request URL:https://khang119966-deepseek-ocr-demo.hf.space/gradio_api/upload_progress?upload_id=wbtrc1mgpde
Request Method:GET
Status Code:200 OK
上传图片:
选择任务类型:
可选图像分辨率和任务类型(项目中图像分辨率可能不需要,任务类型一般是转为markdown格式和json格式),点击处理图片进行OCR处理。


任务执行过程
如果处于高峰期可能会出现失败情况
Request URL: https://khang119966-deepseek-ocr-demo.hf.space/gradio_api/queue/join
Request Method: POST
Status Code: 200 OK
使用 queue/join 表示该应用启用了任务队列(用于处理长时间运行的 OCR 推理任务)。
前端传入负载:
{ "meta": { "\_type": "gradio.FileData" }, "mime_type": "image/png", "orig_name": "Pasted image 20260224140325.png", "path": "/tmp/gradio/7d982982cadb672224178077fafc1e62c9f287b8fc91a507d4af86001c6413ba/Pasted image 20260224140325.png", "size": 32892, "url": "https://khang119966-deepseek-ocr-demo.hf.space/gradio_api/file=/tmp/gradio/7d982982cadb672224178077fafc1e62c9f287b8fc91a507d4af86001c6413ba/Pasted image 20260224140325.png" }, "Large", // 图像分辨率大小选项 "📄 Convert to Markdown", // 表明用户选择了"转换为 Markdown"功能 null, null, 1, // fn_index: 指明调用的函数编号(对应后端逻辑) "aghdgjxbu4t", // session_hash: 会话唯一标识 8 // trigger_id: 触发此操作的前端子项 ID后端响应结果:
{
“event_id”: “200ba9365b3e4bf3a939fa542dad9e30”
}
结果返回200,表示请求已成功加入任务队列,后续需通过WebSocket 或轮询接口监听该 event_id 的处理状态。
如果成功会出现解析之后的图片和解析之后的文档格式:
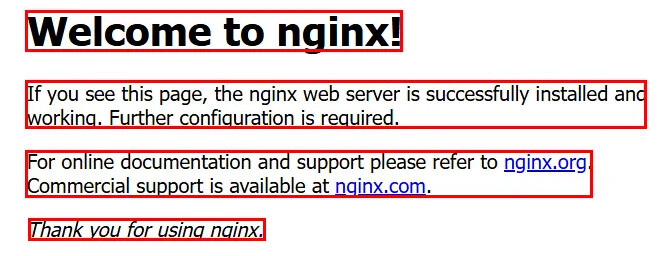
文本内容:
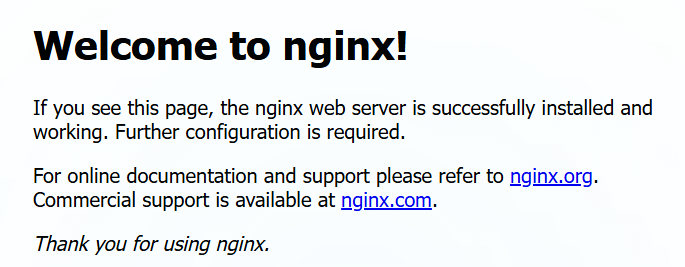
<|ref|>sub_title<|/ref|><|det|>[[48, 66, 580, 202]]<|/det|>
Welcome to nginx!
<|ref|>text<|/ref|><|det|>[[48, 300, 925, 460]]<|/det|>
If you see this page, the nginx web server is successfully installed and working. Further configuration is required.
<|ref|>text<|/ref|><|det|>[[48, 535, 848, 690]]<|/det|>
For online documentation and support please refer to nginx.org.
Commercial support is available at nginx.com.
<|ref|>text<|/ref|><|det|>[[52, 760, 386, 833]]<|/det|>
Thank you for using nginx.
其中ref标签用于目标检测,用于区分文本类型,比如sub_title,text
det标签是用于区分文检测区域,[[x1, y1, x2, y2]] 是 边界框坐标,表示文本在图像中的位置(左上角 x1,y1 到右下角 x2,y2)。
总结:
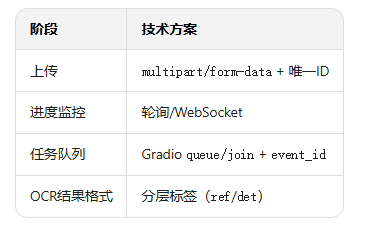
OCR 的流程主要为四个核心维度:数据输入、异步传输、排队推理、结果显示。
4 个帖子 - 2 位参与者