DeepSeek v4好不好,到底有多好,和同行对比如何?一眼就能看出来。
连接不同大模型,给aipy任务提示词:
打开windows画图软件,控制鼠标,画一辆小汽车。接下来看图回答问题:谁的最丑?谁的最抽象?国外谁最好?国内谁最好?DeepSeek进步如何?谁进步最大?
答对有奖!(非本人原帖写的)
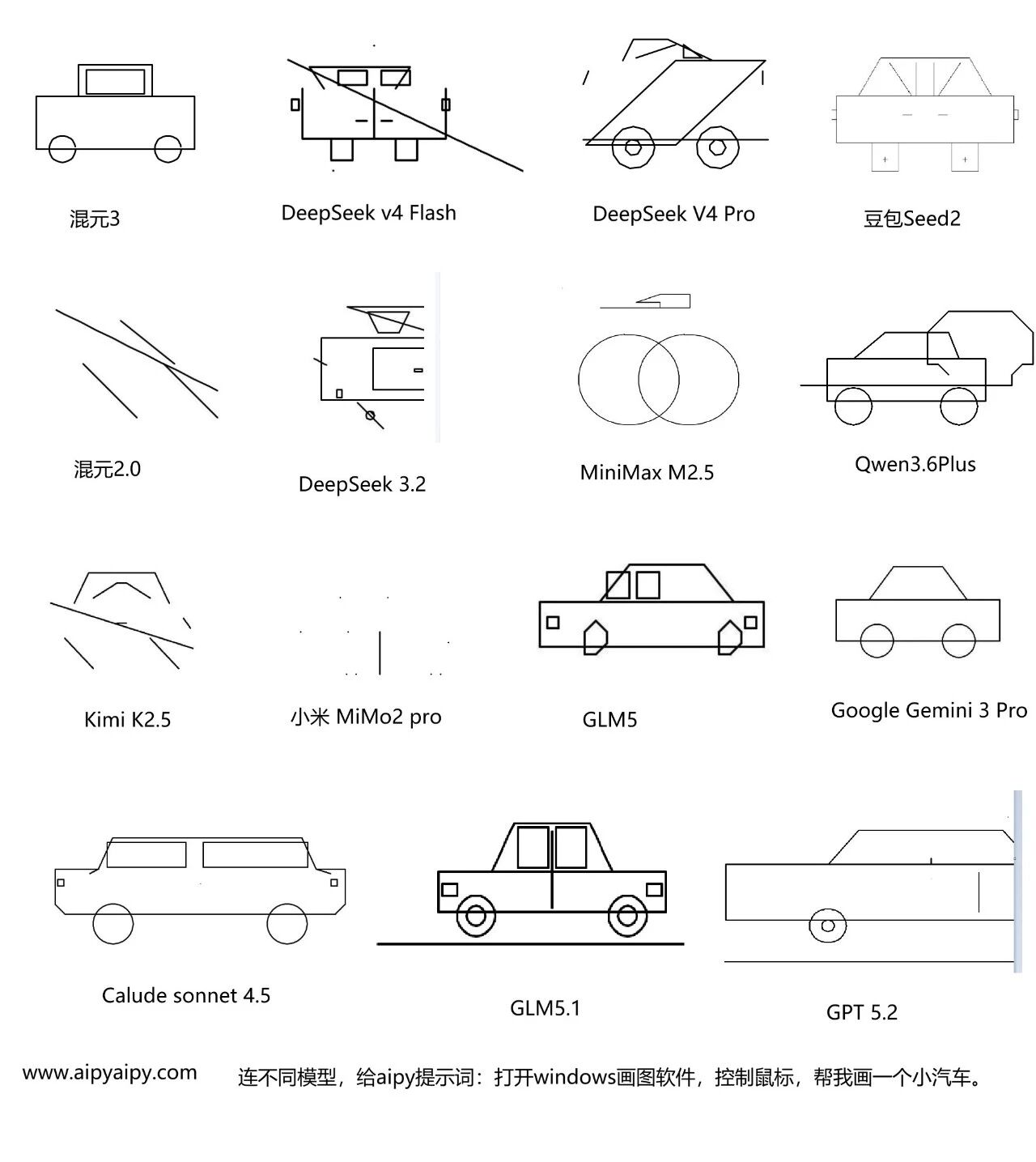
DeepSeek v4 Flash和 v3.2进步并不大,更抽象的是Pro比Flash差,收获了长记忆,失去了部分通识。
GLM5.1和Sonnet并列第一
GPT5.2也不行。QWen3.6本来不错,但出现了幻觉。
再看各家,为什么各家差异这么大?因为大模型能力取决于:训练数据大小,综合性,对世界通识的认知能力这需要数据成本、数据清晰成本训练显卡成本、耗电成本
能力和成本成正比,而任何企业都要算投入产出比,找均衡
因此很多大模型,是对某些方面擅长,损失通识,获得打比赛、场景专长处如何测试大模型通识能力,就是刚才这个测试,测试了这些能力:
知道什么是小汽车
知道如何描述小汽车
知道如何打开windows画图软件
知道如何控制鼠标
知道如何将小汽车描述,转变为鼠标操作
测试了大模型全面的能力。
因此高下一目了然。
DeepSeek v4 整体能力看起来是中间水平,但和期望值相比就让人失望了, 不知道是算力原因,还是数据原因,知情的可以吱一声。
【各位大佬是怎么看待这个测试的(![]() )】
)】
附上原帖地址https://mp.weixin.qq.com/s/yKDQwopbb_HMLCTUh73S-w
10 个帖子 - 9 位参与者
来源: linux.do查看原文