首页
/
科技 / 昇腾910B本地部署DeepSeek-V4-Flash(w8…
昇腾910B本地部署DeepSeek-V4-Flash(w8a8量化版)测试
编辑部
2026-05-04T12:22:28.545646
35711 阅读 tech
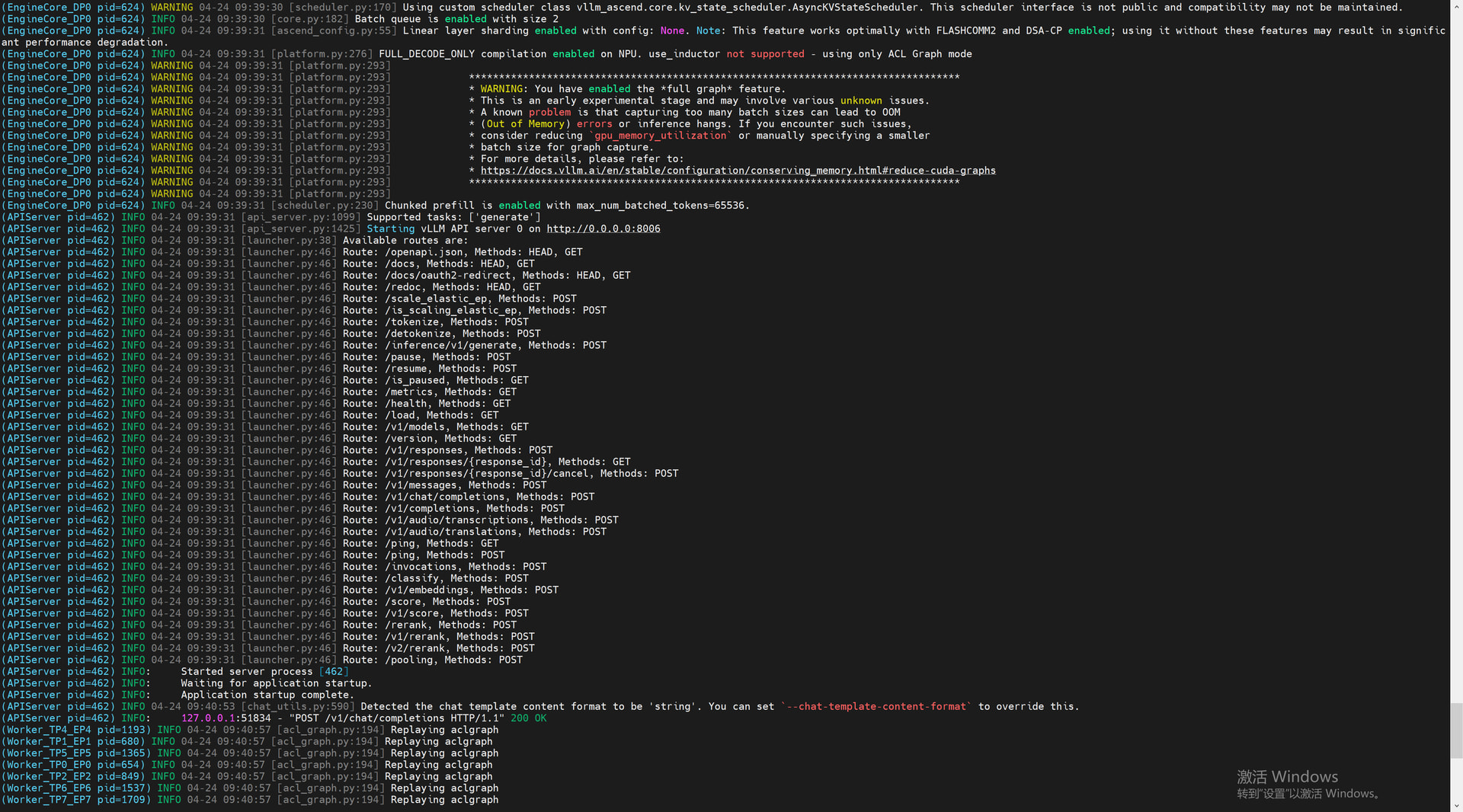
老登们下班了,现在可以霍霍服务器了 vllm-ascend部署文档: DeepSeek-V4 — vllm-ascend 模型: DeepSeek-V4-Flash-w8a8-mtp · 模型库 启动成功: 先问一下洗车问题: 逻辑OK 跑一下文档中的数据集(GSM8K,数学推理能力) 速度慢的发指...
 昇腾910B本地部署DeepSeek-V4-Flash(w8a8量化版)测试
昇腾910B本地部署DeepSeek-V4-Flash(w8a8量化版)测试
老登们下班了,现在可以霍霍服务器了 
vllm-ascend部署文档: DeepSeek-V4 — vllm-ascend
模型:DeepSeek-V4-Flash-w8a8-mtp · 模型库
启动成功:
先问一下洗车问题:

逻辑OK
跑一下文档中的数据集(GSM8K,数学推理能力)

速度慢的发指 ,10个并发~290~480 tokens/s

(毕竟只有一台机器,速度上不去)
先去吃个饭,吃完再来看一下
2 个帖子 - 2 位参与者
阅读完整话题