**叠甲**:不评价minimax现在额度这块的消息,最终肯定会有个定论。![]()
个人看法:跟之前一样minimax并不是很值得付费,仅能够当做龙虾玩具跑一些目标和流程比较具体小功能。
**裁判**:claude-opus-4.8 max
这次测试用的流程:
同一个问题使用这三个模型。。
![]()
首先耗时上,M3很慢。当然有可能是M3还没有highspeed模型。

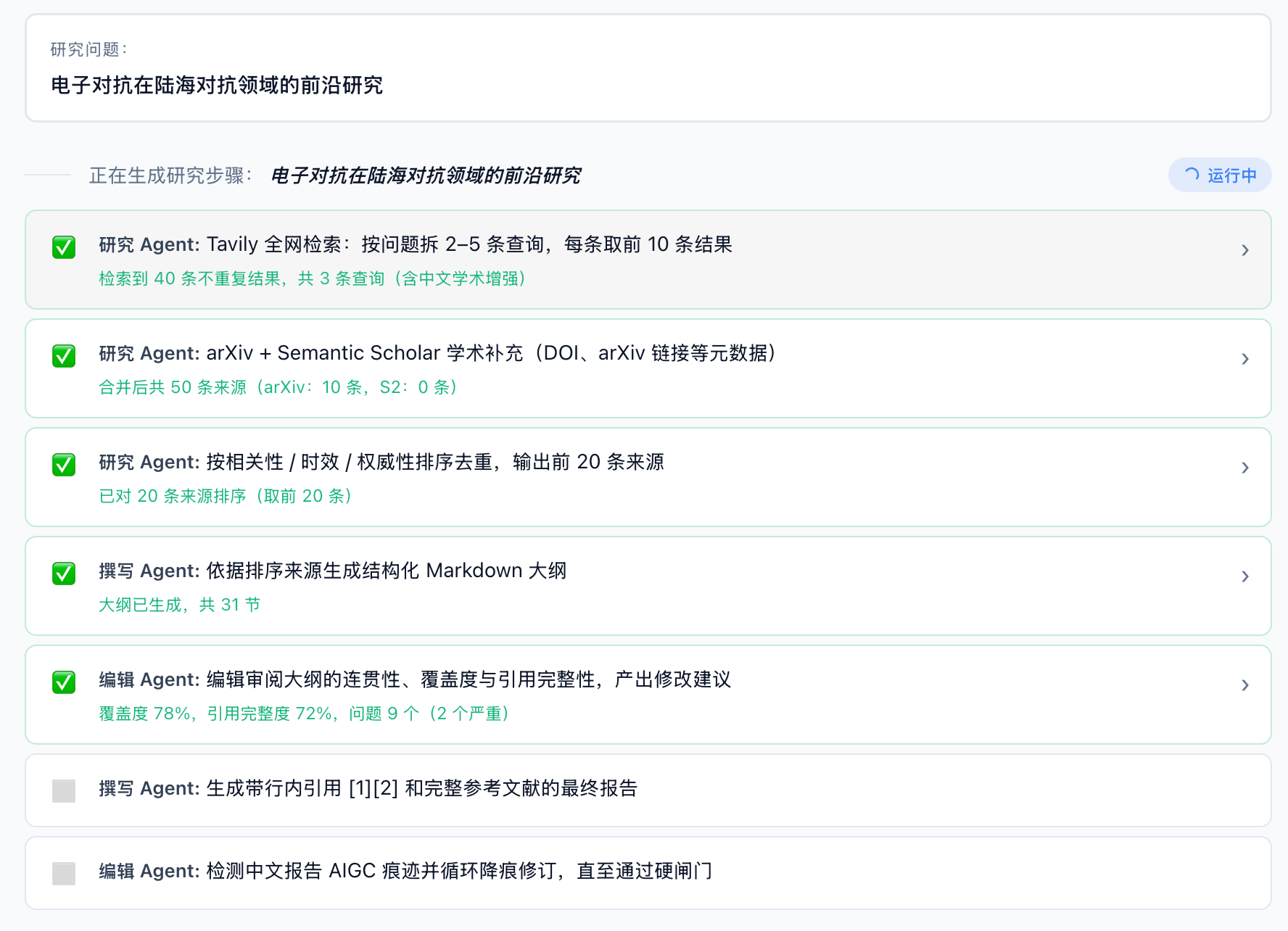
然后是claude评判的结果。直接上对比总结表。

1. M3反直觉:最新的 M3 综合表现最差。 AI味重(57 分,两项高危),一个真实生成缺陷------第三章整章丢失、留了一句翻译模型的报错。。。而且耗时是高速档的 2.2 倍。
文章开头的现状判断:四条主线的证据与边界是三篇里单段推理质量最高的。明确把已验证结论和概念验证/预测分开。思考时间这么久这点优势没什么卵用。而且高质量内容并不稳定:开头还凑合,后半拉胯成模板套话。
2. M2.7 高速是综合最佳。 干净、连贯、数据扎实、AI 味最低(唯一通过硬闸门),至少这个流程上发挥还不错。整体偏保守。
3. M2.5 高速是最像真人专家的一篇。 TRL 路线图、具名武器系统、海面电磁传播物理、UNCLOS 法律维度------信息密度和专业纵深三篇里最高。代价是这种风格是幻觉高发区。。。
佬们。。虽然opus也被吐槽过4.7、4.8并没有比4.6强。。但这minimax搞了这么久吐出来的东西真的难顶。。
多模态,能读视频,能做音频口播什么的在这种模型能力下真的靠谱吗。。。![]()
1 个帖子 - 1 位参与者
来源: LinuxDo 最新话题查看原文