之前刷推老看见有KOL在转发他们的产品,这次技术报告一出来,还挺有意思的
先放架构图:

熟悉文生图模型的老友们都知道,过去的模型都是先将像素的RGB数值转化为向量,放在潜空间里(VAE层)
这次他们的统一架构NEO-Unify完全摒弃了这个做法,采取的是像素输入,像素输出,让模型直接理解图片,而不是一堆潜空间里的数据

在训练数据上,理解类和生成类数据分别用了:
-
预训练混合比例: 包含图文对 (32%)、纯文本 (37%)、详细描述 (17%) 以及信息图表 (14%)。
-
中期训练: 采用 SenseNova V6.5 数据集,并通过多维度过滤(采样平衡 + 提示词增强 + 模型自动化评分)进行精炼。
-
VLM 重标注 (Re-captioning): 所有图像(涵盖自然、设计、人像、合成类)都去重和 VLM 重标注流水线,确保文本与像素之间的语义对齐
-
交错逻辑: 数据分布包括生活方式 (44%)、信息图表 (29%) 和推理 (8%)
-
生成式 CoT (思维链): 每一个推理样本都包含思维链过程,在渲染像素之前,先教会模型理解场景背后的逻辑。
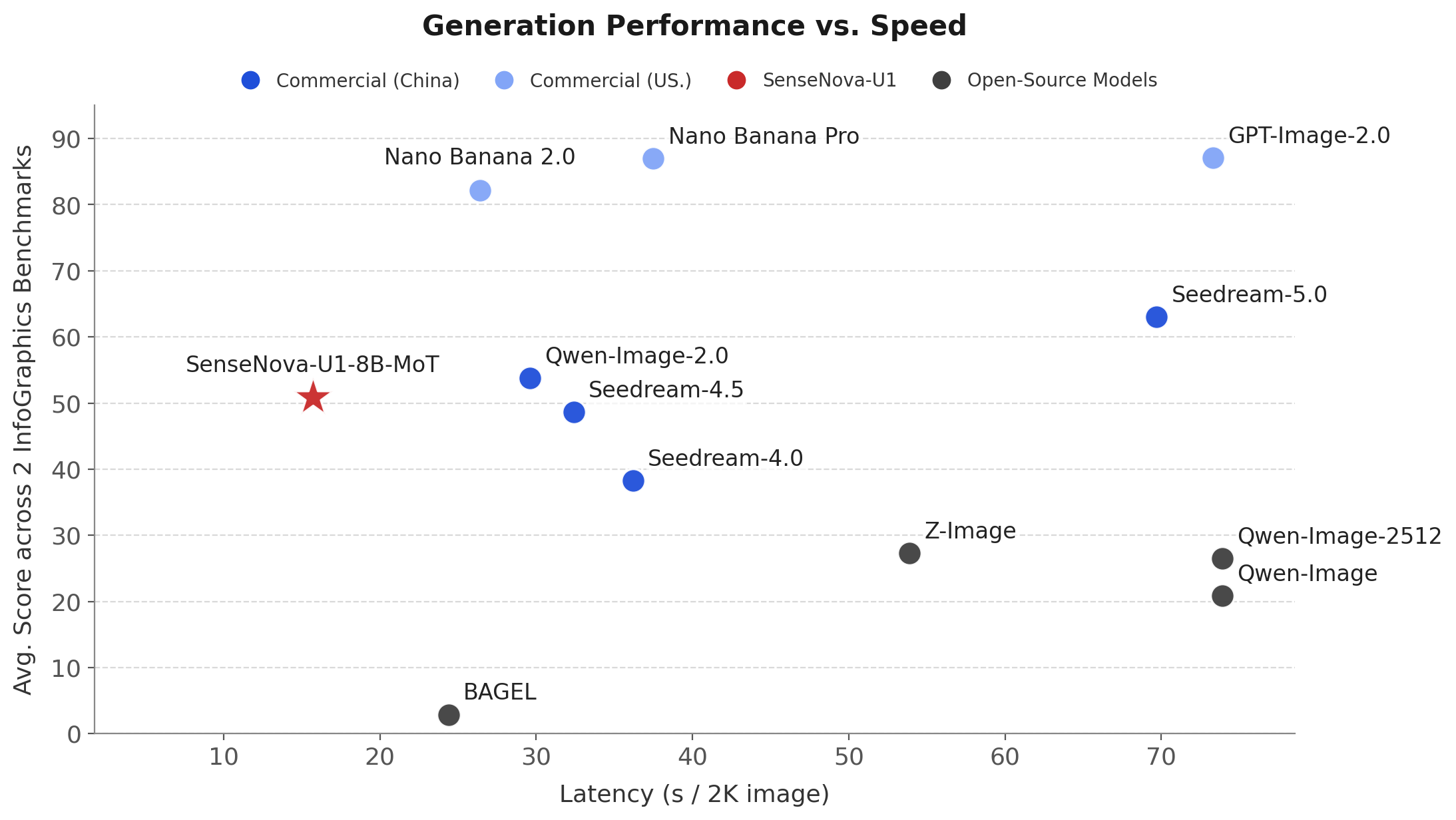
过去我们觉得 VAE 导致的文字模糊和纹理丢失是“必要代价”,但 U1 证明了:只要架构选得对,原生 像素 生成比潜空间(Latent Space)更强。同时在训练方法上,也和其他传统的扩散模型不太一样:
核心方法:
-
无 VAE 视觉接口(VAE-Free Visual Interface): 采用 2 层卷积实现 32 倍的图像压缩编码,并使用 MLP(多层感知机)头部直接预测像素。引入了动态噪声缩放(DNS)技术,确保从 512px 到 2048px 分辨率下的信噪比(SNR)保持一致。
-
原生 MoT(Mixture-of-Transformers): 构建了一个统一的主干网络,使理解与生成流共享自注意力层(Self-Attention),但使用解耦的 FFN(前馈网络)和 Norm(归一化)层,并根据 Token 类型进行动态路由。
-
联合训练与部署: 通过结合自回归(Auto-regressive)和流匹配(Flow Matching)损失函数进行优化。模型经历了从预热(Warm-up)、指令微调(SFT)到 8 步蒸馏(8-step Distillation)的 6 阶段训练流水线。部署方面,利用 LightLLM/LightX2V 实现了独立并行调度。
最后放上他们现在可以免费领的token plan:https://www.sensenova.cn/token-plan
(每 5 小时 1500 次免费调用,Token 消耗比别的模型低 60%)

一些ShowCase:

原文: SenseNova-U1/docs/pdf/SenseNOVA_U1.pdf at main · OpenSenseNova/SenseNova-U1 · GitHub
3 个帖子 - 3 位参与者