- 我的帖子已经打上 开源推广 标签: 是
- 我的开源项目完整开源,无未开源部分: 是
- 我的开源项目已链接认可 LINUX DO 社区: 是
- 我帖子内的项目介绍,AI生成、润色内容部分已截图发出: 整个项目没有一行古法编程,就不截图了
- 以上选择我承诺是永久有效的,接受社区和佬友监督: 是
以下为项目介绍正文内容,AI生成、润色内容已使用截图方式发出
家里这台23年组的小Server也没有派上特别大的用场,4张2080ti,1T DDR4内存。虽然能直接跑跑Qwen,养养龙虾,但还是和主流大模型能力差距不小。此外去年ktransformers刚开源的时候就尝试过run一下DeepSeek-V3/R1,量化版的能力也没有多好。
而在2026年,大人,时代变了。Top-tier的token管够,人负责输出idea,没什么是做不了的。所以——为大家奉上一个2W人民币的本地化DeepSeek-V4-Flash方案。
终极目标
在一台2023 年组的,成本不到 2 万元人民币的 4×RTX 2080 Ti (22G魔改版)老机器上,跑通 DeepSeek-V4-Flash 284B。
这台机器没有 NVLink,没有 BF16/FP8/FP4 tensor core,只有PCIe Gen3,CPU 是双路 Xeon E5-2696 v4,AVX2-only。如果只看硬件参数,这件事看上去不太像是一个正常目标。因为今天绝大多数 frontier-scale open MoE的默认前提,都是更新的 GPU、更快的互联、更现代的低精度格式,以及一整套围绕这些硬件假设构建的 kernel stack。
要搞定这件事,比起租个H100直接拉下来vllm/sglang的docker镜像部署,可谓重重阻碍。事实上在DeepSeek-V4发布当天,我就尝试把vllm和sglang的未合入PR(so called 0-day support?)都试了一下,一切都很理所当然:
- 不支持sm_75
- tilelang无法编译
- flashinfer/flash-attn都不支持
- …
即便是尝试部分组件重写基本上也不可能。转头去看了下ktransformers,彼时还没支持,另外再看看我们这个E5-2696的老CPU配上PCIE3.0,好像在做一件不可能的事?
DeepSeek-V4-Flash的可能性
事实上25年对DeepSeek-V3的尝试,让我几乎断了让这台“老爷车”拉千亿模型的想法,但是DeepSeek-V4-Flash的规格一放出,13B的activate参数又让人觉得有可行性了。

让我们看一下DeepSeek-V4的架构图,一以贯之的极致性价比追求,让V4-Flash带来了这些:
- MoE:routed experts可以天然异构放到host内存,且权重是FP4。
- Top6激活:极少的算力需求,甚至2080ti也足够支撑。
- SWA + CSA + HCA 三种混合Attention:解决超长上下文的 O (n²) 复杂度与显存爆炸问题,将KVCache显存占用与Attention计算量降为Deepseek-V3.2的10%以下。
有了模型结构带来的天然优势,对于显存和算力的需求基本上都可以压到一个非常低的水平,下面是这套方案的一个overview:

- 异构存储,使用host内存放置routed experts,88G显存完全足够embedding+attention+shared expert+head的需求,还可以留有超过2/3的显存给kv cache使用
- TP+EP,4卡自然要充分并行执行,这种一体机的配置自然是TP打底,EP则是按4卡进行分组,虽然先放在host侧,但是后面同时提供了CPU计算和H2D+GPU计算两个选择,取性能更优的方案。
- 逻辑PD分离,4卡虽然不足以做真实的P-D实例,但是Prefill是Computing-bound,Decode是Memory-bound,需要完全不同的算子实现。
- 充分设计计算、通信、内存搬运的overlap,还要充分考虑没有nvlink全部走pcie的限制。
至此,一套需要在异构、切分、Overlap等等细节充分打磨的方案也算成型了。
老硬件without新软件
补齐软件栈缺失
前面提及过,vllm/sglang等推理框架是不考虑这种老旧硬件的,而lmdeploy这样支持老硬件的库也没第一时间支持DeepSeek-V4,只能自力更生了。从DeepSeek-V4官方库的代码开始,先尝试run起来。不出意外地,tilelang根本不支持sm_75,所有官方实现的kernel均不可用,包括:
- act_quant:给 FP8/FP4 linear 和 KV 低精度路径提供 activation 量化
- fp4_act_quant: 给 compressor/indexer 的 FP4/QAT 路径做低精度模拟
- fp8_gemm:FP8 act × FP8 weight GEMM
- fp4_gemm:FP8-quant act × FP4 packed weight GEMM
- sparse_attn:基于 top-k KV 的 sparse attention
- hc_split_sinkhorn:HC mixing 的 pre/post/comb 生成
这些算子又可以分为两部分:
- 功能模块的自定义算子
- 低精度GEMM算子
既然没有,就让天才程序员手搓吧,首先生成一版pytorch接口的小算子版本,保证精度ok,然后逐个手写cuda kernel进行性能优化。
而另外一个很大的问题就是2080ti不支持bf16/fp8/fp4,而pytorch框架实际上用fp32模拟了bf16,很自然地fp8/fp4的支持也可以靠fp16模拟,把tensorcore利用起来。但是这又和极致显存利用冲突,且fp16的权重直接变成了fp4的4倍,H2D的压力骤增。一番trade-off,最后还是选择W8A8的方案。
除了device侧的问题,由于要做异构,host侧同样,没有fp4的计算算子,而我们的老CPU只有AVX2指令,所以只能尽可能通过多核来优化routed experts的执行性能。
硬件的骨头怎么啃
众所周知,MoE模型最吃带宽。而这台“老爷车”只有PICE 3.0。
既然PICE的带宽上限摆在这里了,先想办法压模型。这时候你会发现DeepSeek-V4-Flash的原始权重就是fp4存routed experts的,虽然官方很贴心的给了转fp8的脚本,但是x2的weight传输,就意味着x2的h2d时间。所以必须要保持fp4的原始权重不变,h2d之后再进行fp4![]() int8的unpack,这些全部都要放到device侧做,最终达成了0.9x的初版int8 kernel的性能,最终收益还不错。
int8的unpack,这些全部都要放到device侧做,最终达成了0.9x的初版int8 kernel的性能,最终收益还不错。
除此之外,在fp4版本做完的时候,看到有海外的佬在macbook/mac studio上做了ds4这个库(性能确实好, 还有统一内存的优势,但是看一下价格…好像2080ti又香了),有q2量化版,这可以进一步降低h2d的开销,这一版也同样做了支持,只是q2的精度损失会明显高于fp4+int8方案,就看如何取舍了。
最终效果
(很久没写技术文章果然会变懒)先放一下结果:
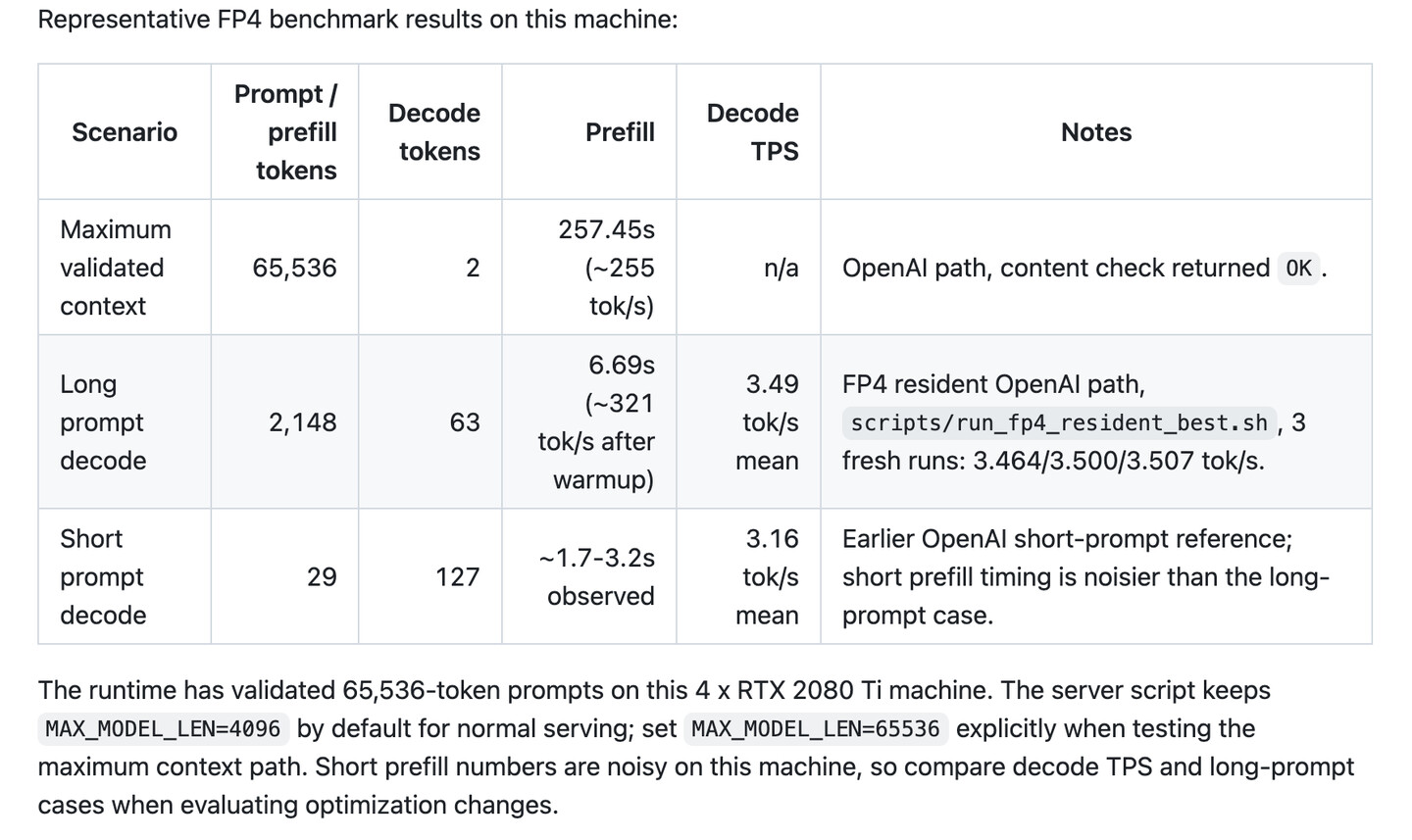
prefill 255 token/s,decode 3.x token/s,堪堪可用。录了一个简短的cherry studio接入效果:
代码已开源,欢迎使用![]() 和Star
和Star![]() :
:
github.com/lvyufeng/deepseek-v4-2080ti/
Arxiv报告正在路上(on hold很久了。。。。),有兴趣的话可以先看代码仓里上传的,核心技术点都进行了详细说明:
5 个帖子 - 5 位参与者