直接上菜:GenericAgent
https://github.com/lsdefine/GenericAgent
本人基本信息:国内某 top3 的计算机博士在读,大模型方向。
最近对 cc 的使用情况:
推荐阅读[推广] [Token 抽奖 + 招推广人] 我们做了个 token 中转,先上来挨打,顺便送点额度
推荐阅读[推广] 辰友 AI 中转,支持 gpt-5.5 与图片生成,自费 pro 号池,包月套餐最低 0.2 倍率
我最近在 github trending 上关注了 GA 这个项目,并高强度使用了一周多(完全接管我的科研+生活),然后我就卸载了 cc 、codex 和 openclaw(但是感谢 cc 曾经在我的生命中出现过,不过 openclaw 你是真的垃圾啊)。。
那么有人问了,cc 那么屌,openclaw 被吹的那么神,有什么问题? 我想但凡用过的人此时在心里都有答案了。。
下文的数据来自 arxiv.org/abs/2604.17091,也就是 GA 的技术报告,里面有些 insights 我非常喜欢,而且我的风格也是用数据说话。
一、你的钱包顶得住吗?
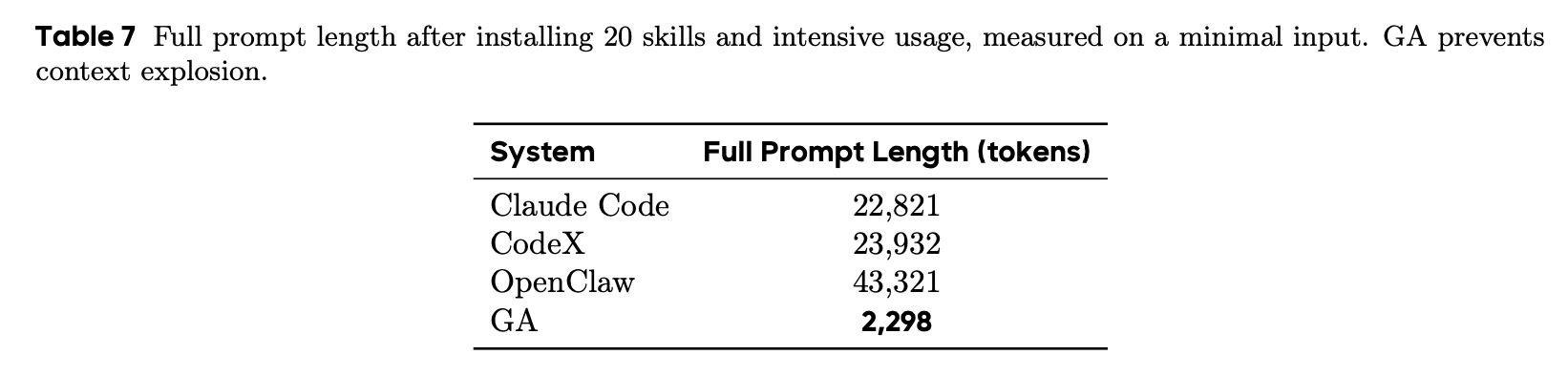
打一个招呼,oc 要用 4w tokens ,cc 和 codex 也是 2w tokens 打底了,真当我 token 不是花钱买的?
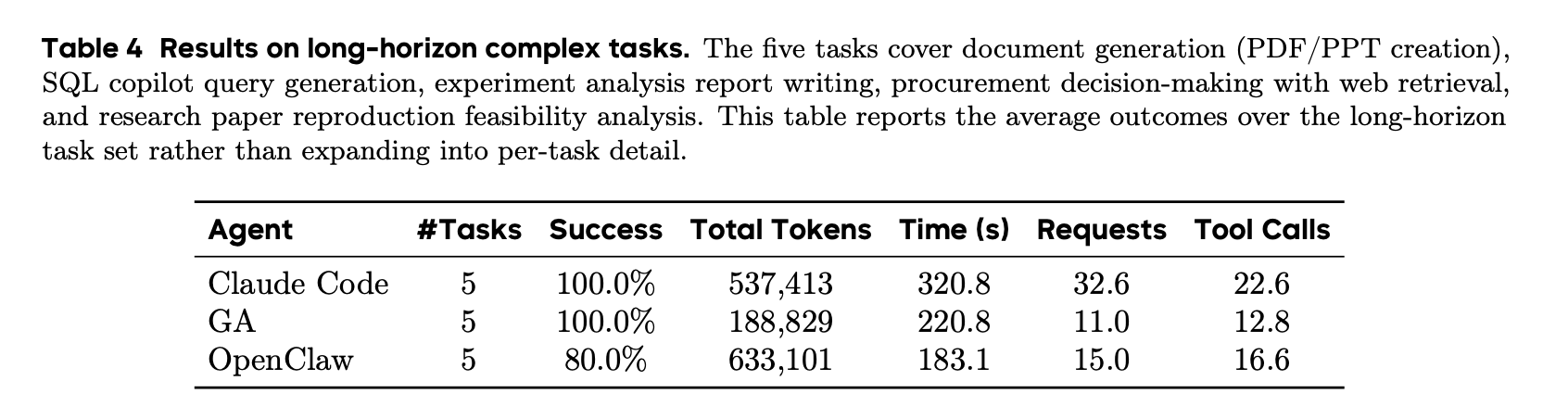
在长程任务上,GA 能够用更少的预算( 1/3 或者更少)获得一样甚至更好的效果。
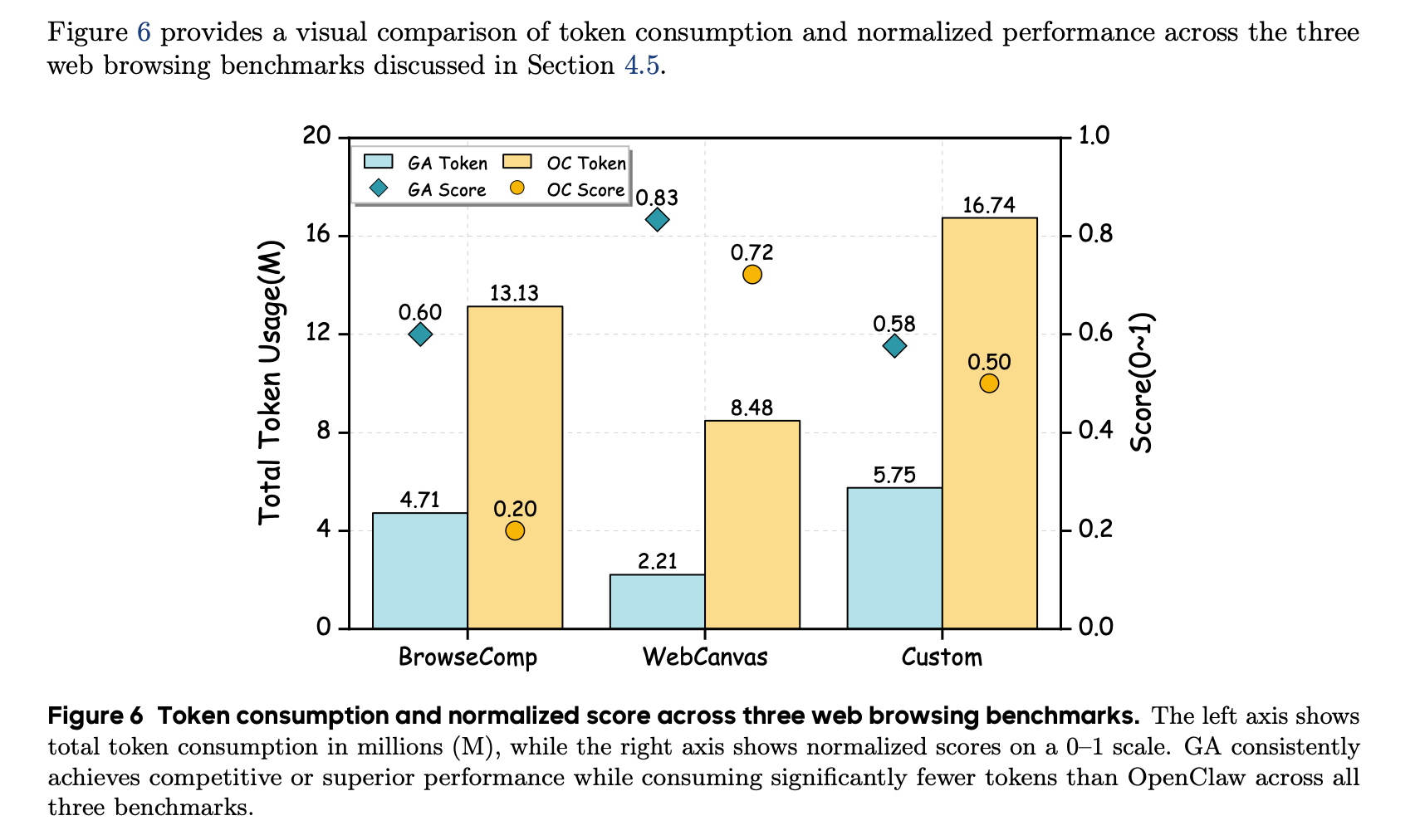
GA 有无敌的原生浏览器操作,能用非常夸张的极低的预算(1/5 左右)实现非常非常 nice 的网页搜索、浏览器操作(1-3 倍的成功率)。
插个题外话,我就是做 deepresearch 的,论文里选的 browsecamp 、webcanvas 这些数据集是非常有挑战的,也给我打开新世界了 hh
最近看大家都在流行 claude code 的各种 web 插件,我的嘴角慢慢上扬。 说实话,ga 的原生浏览器操作吊打所有的 web 插件,不服来战(本人已服)。
二、更好用的智能体一定能自进化
这也是最近 hermes 风头正盛的原因。在这一点上,我认为 GA 做的更好。
不要谈参数自进化,因为我认为的自进化就是 agent 对错误经验的总结学习,就像人的进化就是在直立行走之后能够制造和使用工具,而不是长出第六根手指。
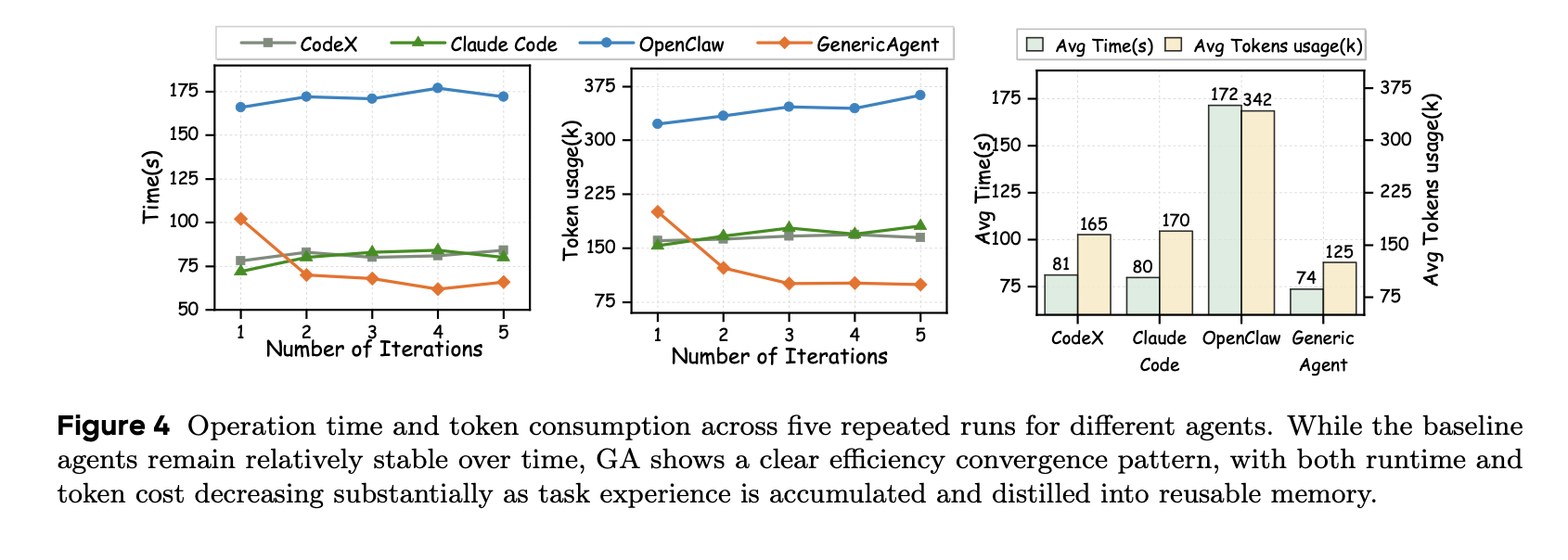
直接上结果,oc 就不谈了,纯垃圾。。看 codex 和 cc ,实际上由于这两者的定位( coding ),所以他们是不会自主的总结重复的工作经验的。如果你每次都让他们做一些崭新的项目,那当然没问题,但是你要是让他们去追踪股票,能够按你一句话帮你去网上填表,去做你日常做的操作,那他们每次探索的成本则是巨大的。
GA 的自进化机制让 GA 得以越用越快,越用越方便(最后甚至能到心领神会的地步。。)
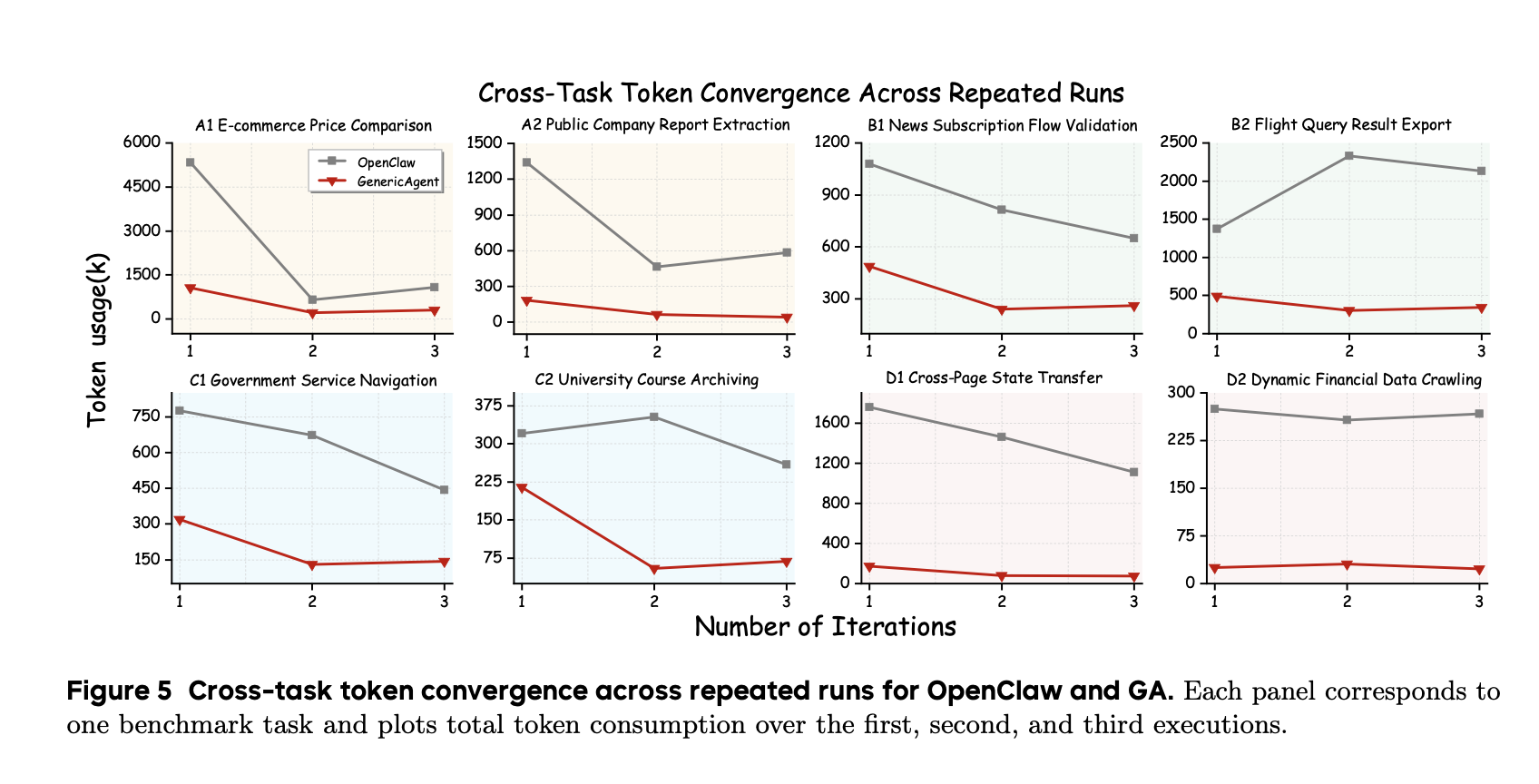
依旧吊打 oc ,oc 赶紧下桌吧。。
三、好的智能体离不开记忆
我知道大家这时候说了,LLM-Wiki 很吊,Evermemos 很吊,Mem0 很吊,我装这些插件就能让我的智能体有记忆。
先不谈这几个插件到底真实性能怎么样,我作为一个看了很多 memory 论文的从事大模型的人来说,作为一个 agent 的 memory 框架:
测 Locomo 、LongtermMem 这几个数据集就是不合适的! 现在的大模型的记忆不再是 user-centric 了!现在我们需要的大模型记忆是 task-centric,这两者有本质的区别。
所以,停止人云亦云吧。。
我深扒了 GA 的记忆设计,其简洁性和有效性真的令人印象深刻,但是在这里就不展开(如果大家感兴趣,我可能再开一篇帖子详细讲讲)。
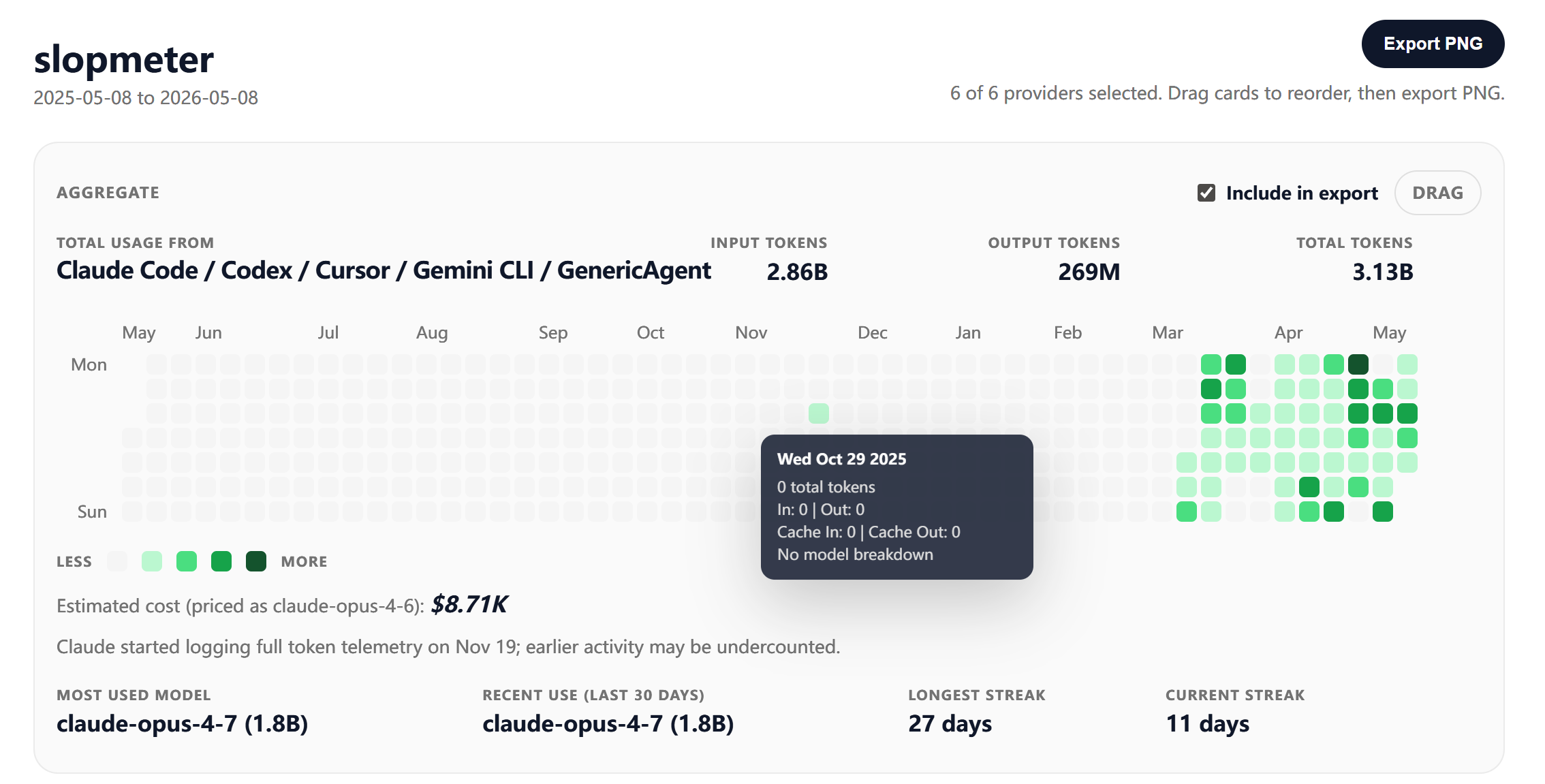
我现在对 GA 的使用如图:
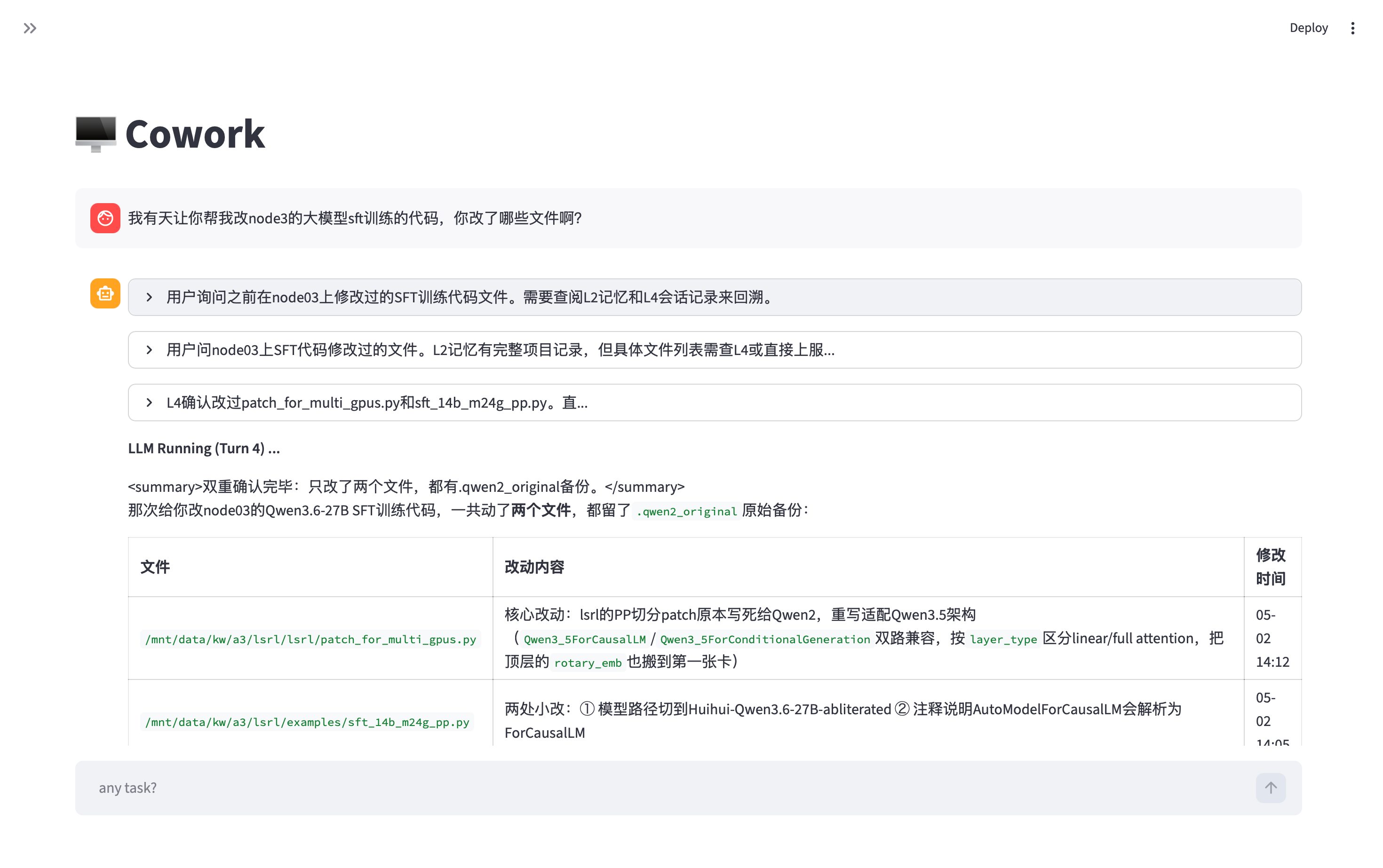
有什么记不得的,直接问就好了。。太 tm 牛逼了。
彩蛋
另外,我是第一次在 V2EX 发帖,发现这图床都要买。。然后也让 GA 给我整了一个,就一句话:
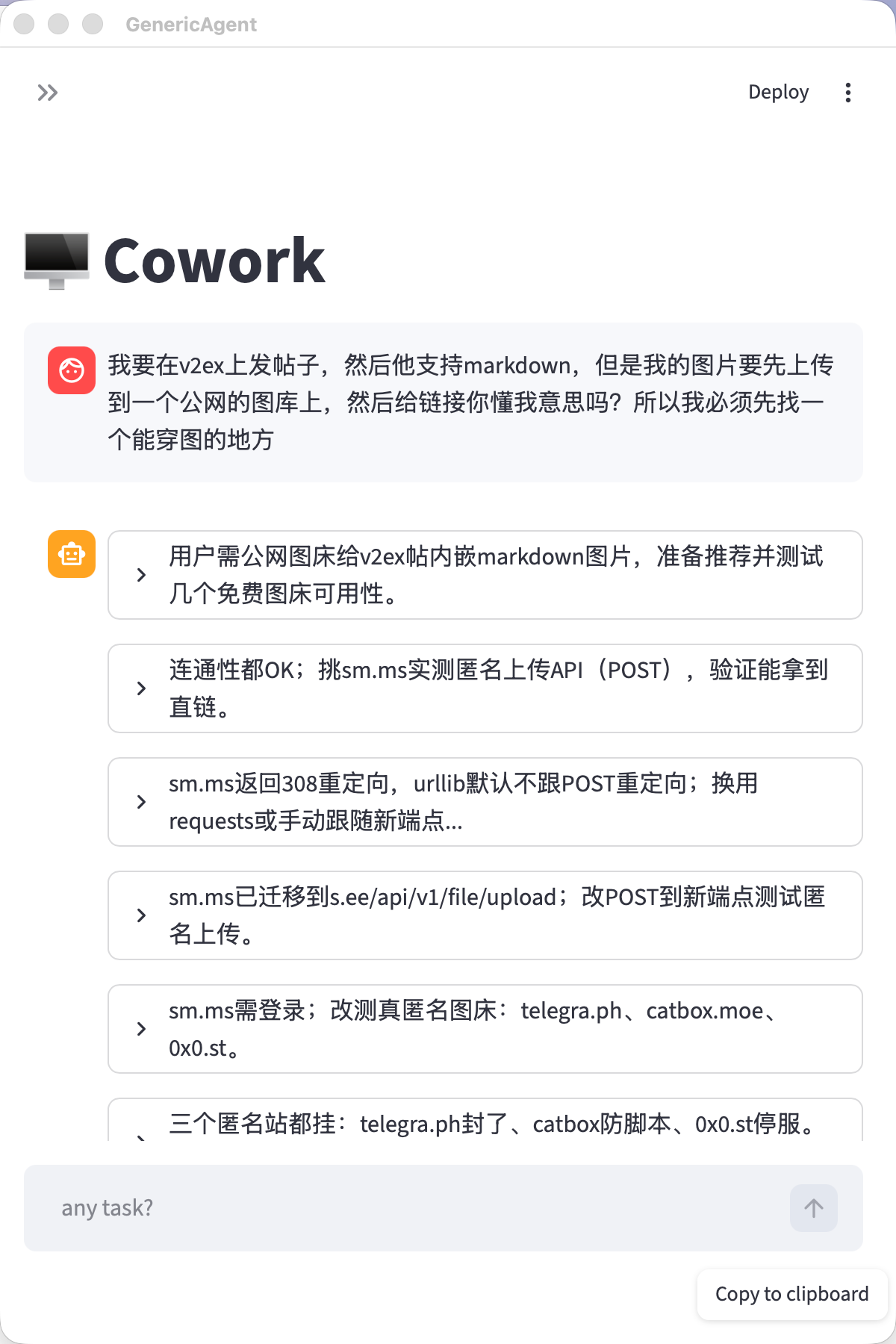
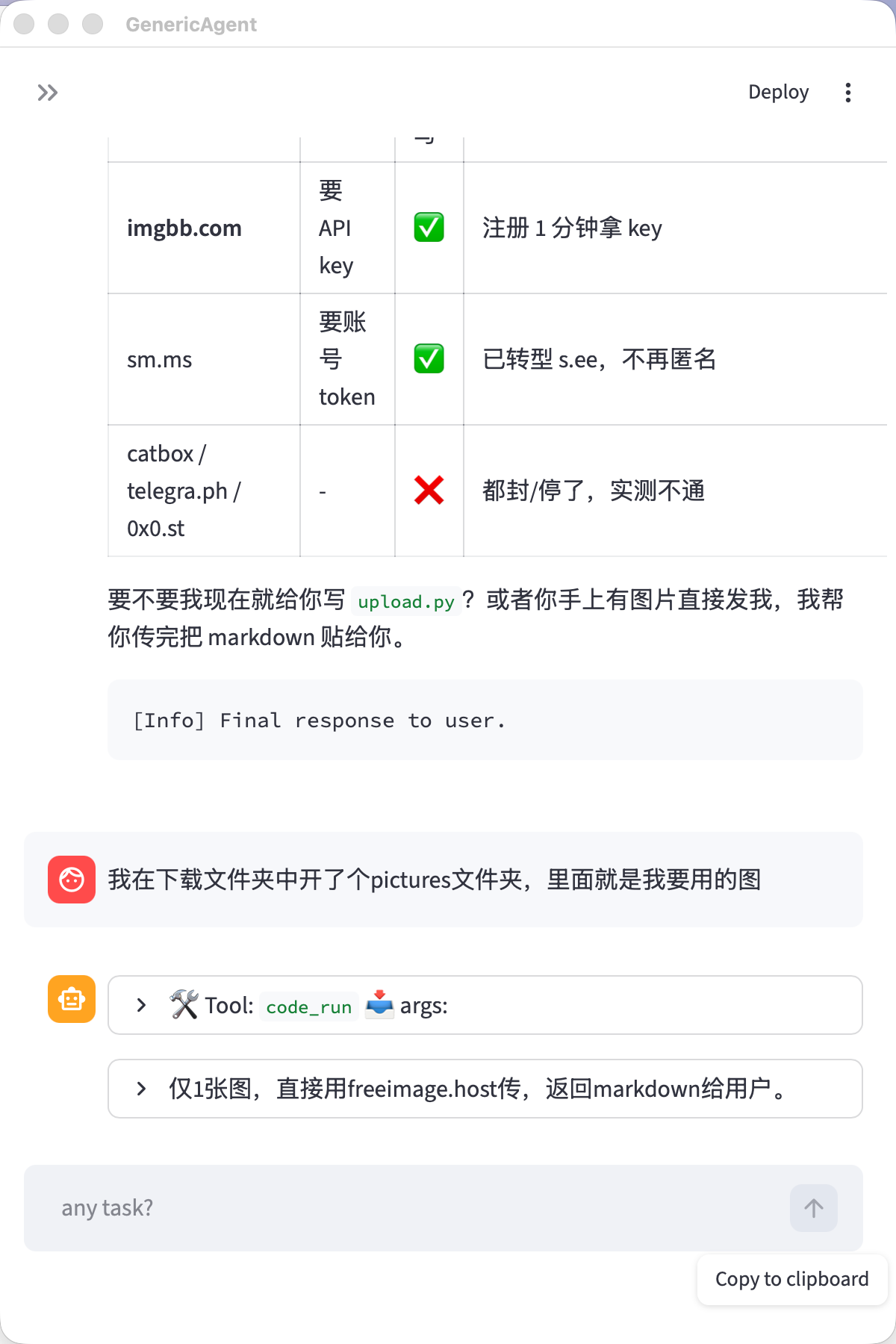
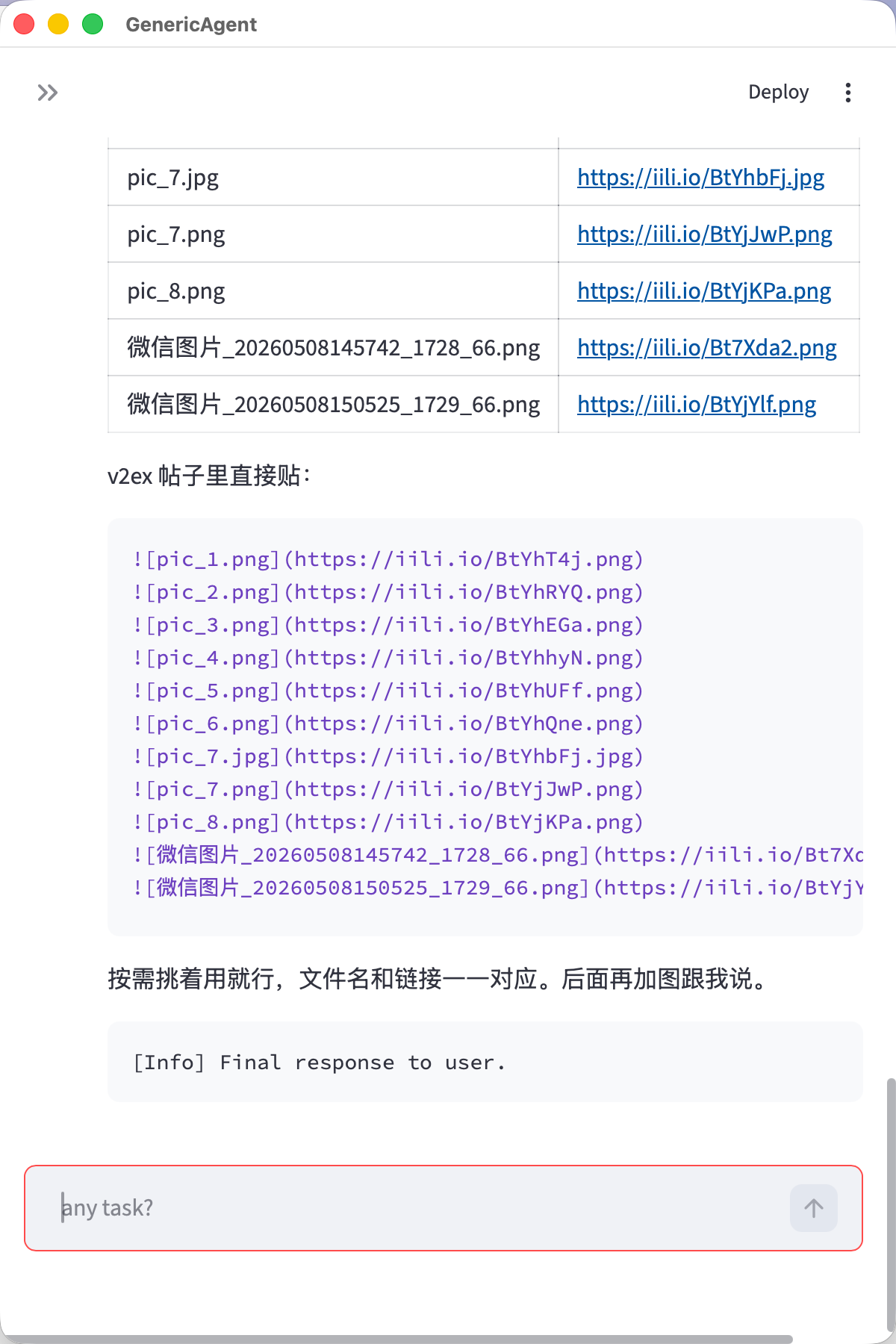
嘿嘿。。最后放一张 GA 自己的 skillhub 里的截图,懂的人自然知道干啥用的。
写在最后
还有很多没提到的,大家自己尝试就好了。当然 GA 也有很多让我不爽的地方,比如极其简陋的前端,然后我就在 GA 的群里潜水,最后发现了,大概是开发者的个人风格就是毛坯房的风格。。问他能不能给整好看点,他回答也简单:
他说 "你让 GA 给你做"。。真的无敌了。。
我不允许还有人不知道 GA !!!!
如果这个帖子有点热度,大家有要求的话,我可能会从专业的角度展开讲讲 GA 的技术实现方法,太 tm 优雅了。。