- 我的帖子已经打上 开源推广 标签: 是
- 我的开源项目完整开源,无未开源部分: 是
- 我的开源项目已链接认可 LINUX DO 社区: 是
- 我帖子内的项目介绍,AI生成、润色内容部分已截图发出: 是
- 以上选择我承诺是永久有效的,接受社区和佬友监督: 是
以下为项目介绍正文内容,AI生成、润色内容已使用截图方式发出
仓库地址
github.com
GitHub - Nasan-Duodushu/GateAPI: LLM API Aggregation Gateway with Model Functional...
LLM API Aggregation Gateway with Model Functional Detection Engine
介绍一下这个项目
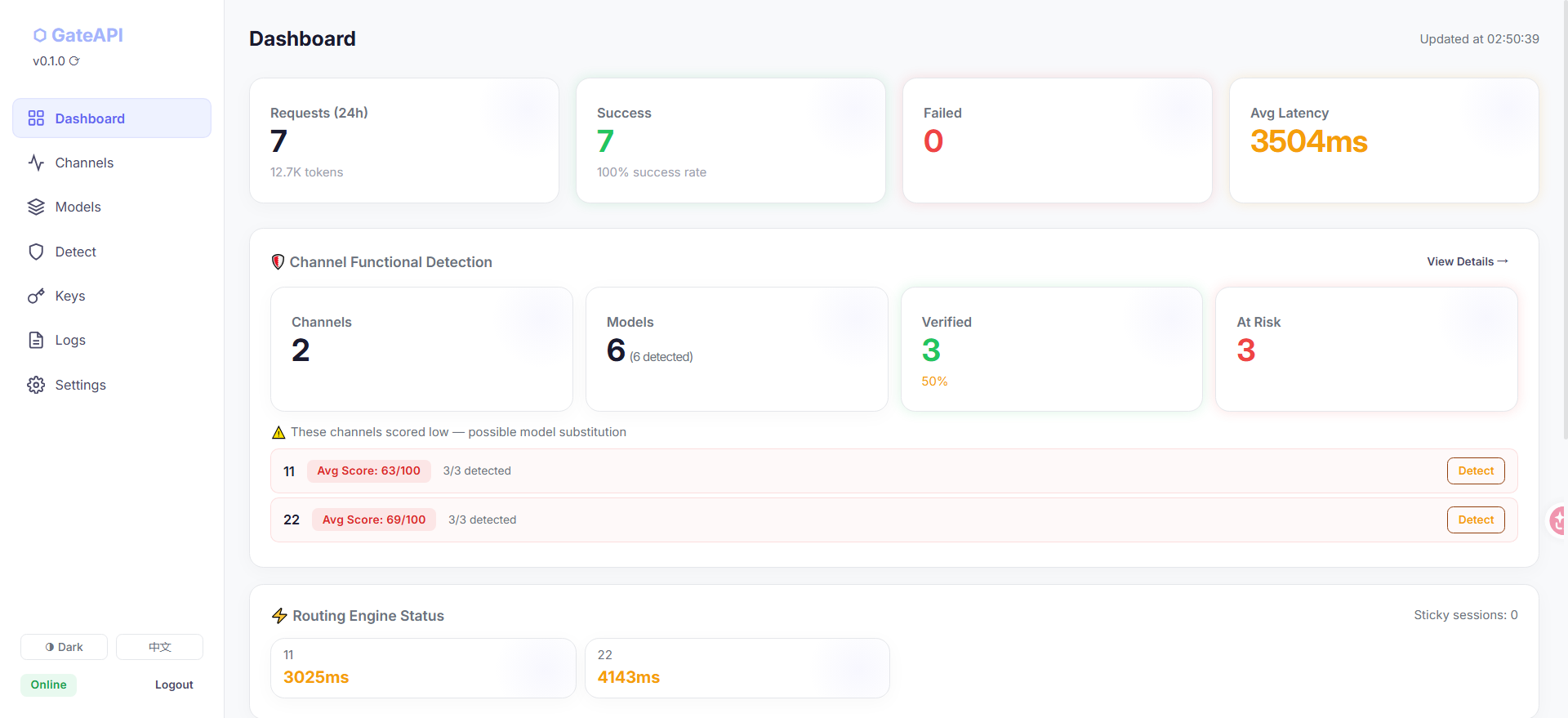
之所以做这个项目是因为最近手里面攒了一堆公益站然后以及一些之前手里的中转站,然后一大堆钥匙,每次都要换来换去,虽然之前也用sub2api以及newapi来进行相关的聚合中转,但是感觉有点太重了,然后这个项目的功能大概就是,聚合所有中转站的API以及检测这些中转站的连通性和模型的质量。把各个中转站不同的接口转化成一个统一的接口,然后进行相关的数据传输。
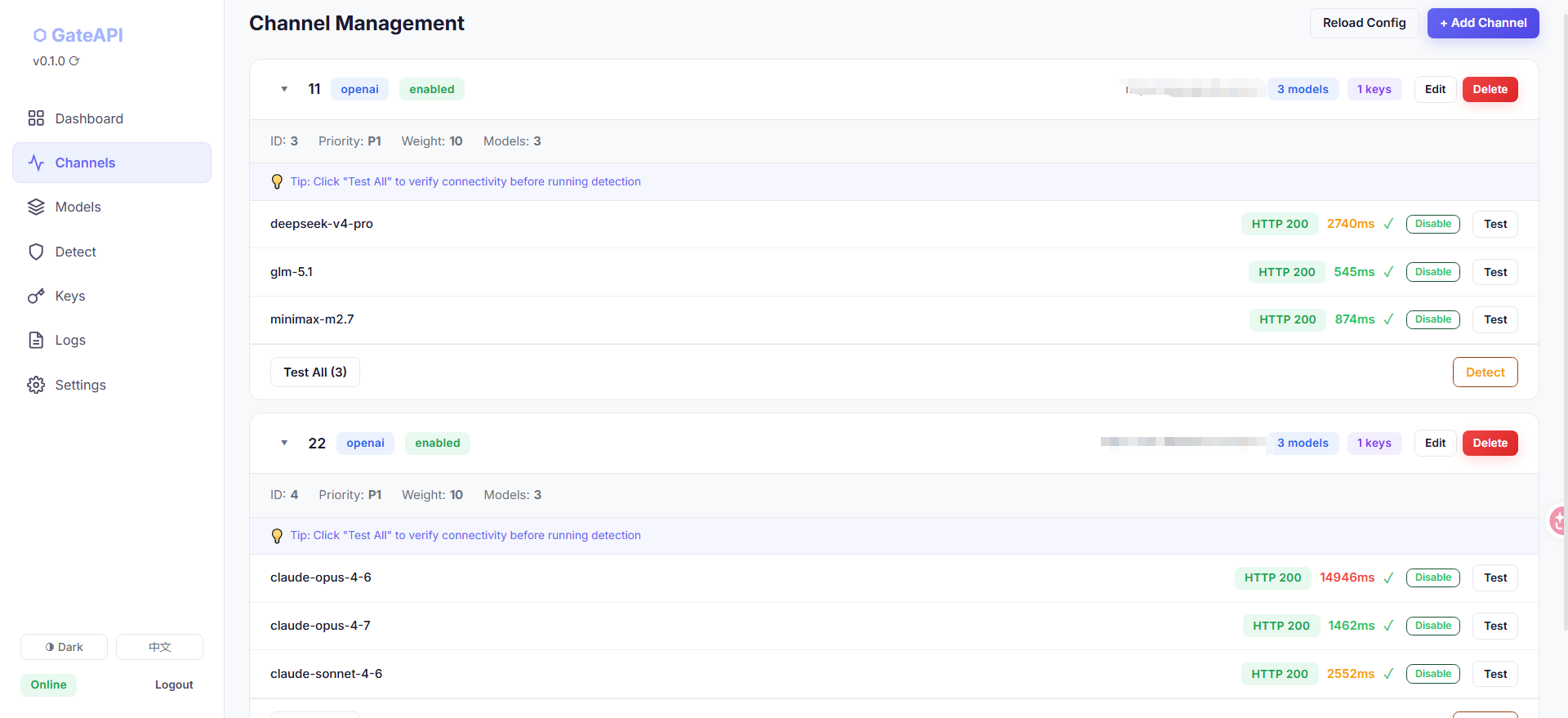
简单讲就是把你所有中转站的API接口key填进去,它会读取你中转站key上面的所有模型,然后以及连通性,顺便还可以测试一下模型的质量。然后合成一个统一的接口,如果有相同模型的中转站可以设置权重然后轮询+粘性的使用,你也自定义权重。
也就是相当于中转A 中转B 中转C 包括你自己的渠道keys OPENAI CLAUDE 这些接口的keys 聚合在一起,做成一个排序似的轮询接口(根据自定义权重调用)
整体原理:
flowchart TB
subgraph 上游["🔑 你手里的中转站 Keys"]
A["中转站A<br/>OpenAI 协议<br/>GPT-4o / Claude Opus"]
B["中转站B<br/>Anthropic 协议<br/>Claude Opus / Sonnet"]
C["中转站C<br/>OpenAI 协议<br/>DeepSeek / GPT-4o"]
end
subgraph GateAPI["⬡ GateAPI 聚合网关"]
R["🔀 智能路由<br/>优先级 + 权重 + 自动切换"]
P["🔄 协议转换<br/>Anthropic ↔ OpenAI 自动互转"]
D["🔍 检测引擎<br/>13项探针 · 功能性检测 · 自动打分"]
K["🔐 密钥管理<br/>生成 Key · 限速 · 限额"]
end
subgraph 下游["📱 你的应用"]
APP["统一调用<br/>/v1/chat/completions<br/>一个地址搞定"]
end
A --> R
B --> R
C --> R
R --> P
P --> APP
D -.->|检测上游质量| R
K -.->|鉴权| APP
请求处理流程:
flowchart LR
用户请求 --> 认证["① 认证<br/>验证 API Key"]
认证 --> 路由["② 路由<br/>按优先级+权重<br/>选最优渠道"]
路由 --> 转发["③ 转发<br/>协议转换<br/>HTTP/SSE"]
转发 --> 判断{成功?}
判断 -->|✅| 返回响应
判断 -->|❌ 429/500| 重试["重试<br/>换下一个渠道"]
重试 --> 转发
检测引擎原理:
flowchart TB
触发["触发检测"] --> B1
subgraph B1["第1轮:基础探针"]
数学 & 逻辑 & 代码 & 知识 & 身份识别 & Token用量 & TTFT
end
subgraph B2["第2轮:一致性"]
温度一致性 & 长上下文记忆
end
subgraph B3["第3轮:指纹"]
Logprobs熵分析 & Tokenizer指纹["Tokenizer 指纹<br/>52模型实测数据库"]
end
B1 --> B2 --> B3 --> 评分["加权评分 0-100<br/>S/A/B/C 等级"]
上面大概就是运行原理,很多细节就不补充了,可以看一下仓库的README。
第一次发开源项目,肯定还有不少粗糙的地方。大家随便提意见,Issue 和 PR 都欢迎。
部署
技术栈很轻量:Node.js 18+,三个依赖(Express + better-sqlite3 + cors),SQLite 存储,不需要装 MySQL。
附带几个项目截图,项目比较小,运行内存30M左右


5 个帖子 - 2 位参与者
来源: LinuxDo 最新话题查看原文