之前用ds做了一些demo
比如单页html:
这个帖子
https://linux.do/t/topic/2100192
iOS的玩具项目(emmm..总体还行 就是有个特效死活写不出来)
今天刚好有个完整的后端小需求,需要改历史代码,想着就让ds试试,使用的依旧是claude code + ds。
项目里放着项目技术栈,大体结构的AGENTS.md(CLAUDE.md 用at引用他)。
我用AI辅助的流程是告诉AI要读哪几些相关文件(就不让他们像无头苍蝇一样到处找了),接着直接说需求,让他们自己调研一下给个方案,我看过觉得ok就让他们自己发挥,这次一共修改了5个现有文件,增加2个新文件。需要新接一个api,然后是一系列crud和业务逻辑。改动不多就几百行。
之前类似的需求用codex+5.4high做都挺流畅的。
调研后给的方案挺好,合理+满足需求。
过程中最直观的感觉就是好慢啊…比5.4high慢好多,读文件之后思考要半分钟起步,claude code显示的still thinking,thinking more之类的有点让人烦躁。
编辑次数比较多,一点点改,这个我记得之前用cc好像也是,他似乎更倾向于小步快跑,会有很多编辑。而codex倾向于一次性改很多。这个可能是工具问题?不确定。
代码写的过程中出现了神奇的幻觉,改出了不存在的变量,变量名还和需求相关,但是不存在,但是立即被他自己发现改正了。
写完之后有一处编译错误,泛型处理错了,第二次改到这段的时候还是没发现,手动自己改了。
代码风格有一点点偏离之前的代码,比如让他看的代码都是用的setter注入,他自己写的构造器注入,这个无伤大雅了。
写完之后让codex看了下,得出:
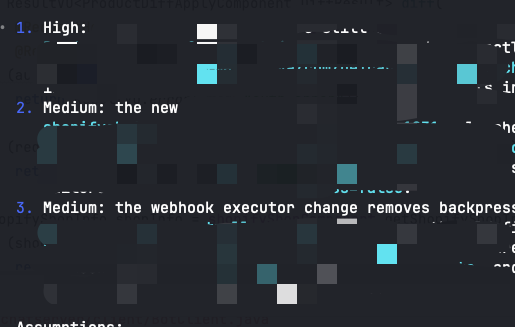
这码打的也看不出来了。。。
第一个high是我自己上手改的时候给改炸了
两个medium的确是写的有点不太严谨了。
整体的逻辑是ok的,没有很严重的漏洞和问题,不过毕竟这个需求也不大。
的确是不如用GPT5.4来的省心,GPT5.4做这类需求的时候我基本就是个看客,也可能是用了几个月codex有点习惯了。
总体会有种去年用sonnet 4.5的感觉,就是看他写总是忍不住提醒几句或者干脆自己上手。但是大致写的都是没问题的。
用的时候已经提前调整好心态这是个平替,直接去对标肯定不合理。心里会有点小疙瘩但也还好。
感觉从御三家切换到国模的时候,这个心态真的挺重要的,如果一开始内心预设就是国模不行,他出点小错很容易就让人失去耐心了。 ![]()
花费:
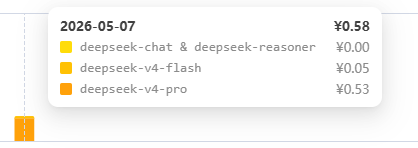
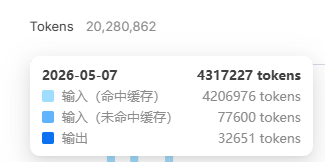
Pro:
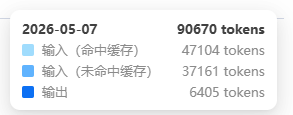
flash:
2 个帖子 - 2 位参与者