又来了,上次的 Open Computer Use:Codex Computer Use开源版本 收到不少佬友的反馈,也得到不少关注。这次继续做了 Browser Use ,分享给各位佬。
BTW,这个文章的草稿就是我用codex cli+OBU自动写的,因为之前每次我从notion拷贝过来图片过不来,要一张一张拷贝贴进来上传,现在直接全自动在后台做完了,直接可以发了,太舒适了
缘起
一切的源头还是源于前面我们开源的Open-Computer-Use,背后的故事可以看这篇解决问题的原始冲动。
这次是因为OpenAI的Codex.app上有release出了Browser Use的能力

分析了一下,又有很多收获,也补齐了一些之前未曾主动去了解的认知缺失部分。收获很大,我觉得值得写一篇文章聊一下。行文依然是关注过程重于结果,方法论或者思维的跃迁才是最重要的。
探索
整个探索过程依然和之前在解决问题的原始冲动里分析的是类似的,我们首先依然是拉Harness Template(PS:现在我会用更加便捷的方式harness-cli :
➜ harness-cli open-browser-use
Select template language:
1. English
2. Chinese
Choice [1]: 2
Using Chinese template from https://github.com/iFurySt/harness-template-cn.git
copy 53 file(s)
Initialized git repository
然后开始分析官方的,这样可以把整个探索的过程不断留存下来,未来需要的时候可以不断查询和溯源。
这次的起手是:
➜ cd ~/.codex/plugins/cache/openai-bundled/browser-use
➜ browser-use tree -I 'node_modules'
.
└── 0.1.0-alpha2
├── assets
│ ├── browser.png
│ └── composer-icon.png
├── docs
│ └── capabilities
│ ├── browser
│ │ ├── viewport.md
│ │ └── visibility.md
│ └── tab
├── scripts
│ └── browser-client.mjs
└── skills
└── browser
├── agents
│ └── openai.yaml
└── SKILL.md
11 directories, 7 files
可以看到,主要是一个skill+browser-client.mjs这个client。所以我们可以快速从这里分析切入。话不多说,我直接丢一个架构图
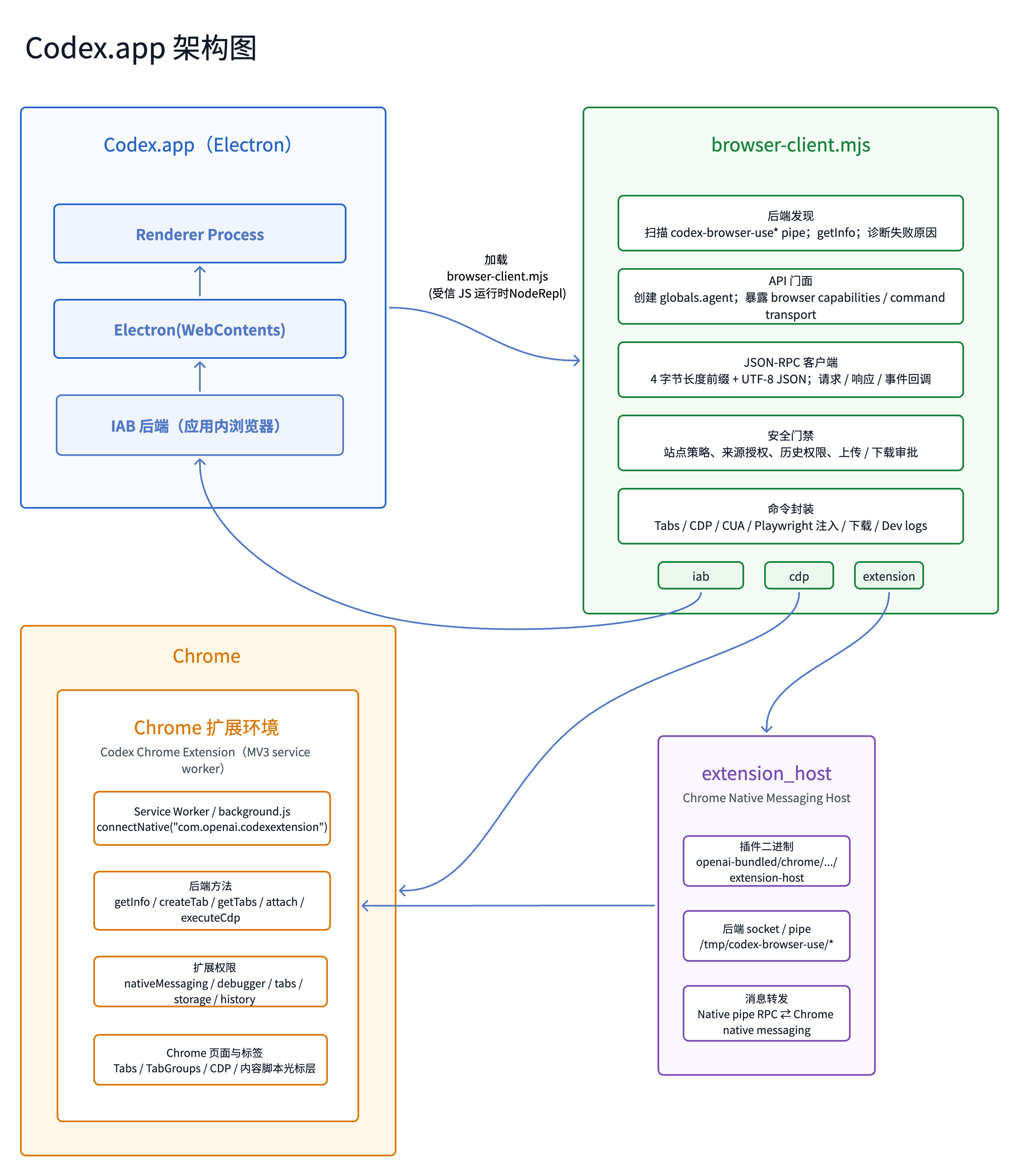
总体而言iab(in-app browser)是Codex.app自己抽象的一个浏览器,用windowId+sessionId作唯一id,整体表现为单窗口单会话只有一个浏览器窗口。
展开之前,先聊一点浏览器相关的
Chrome
我们从下往上看,首先是Chromium,是一个开源的浏览器内核项目,Chrome就是基于这个项目构建的商业浏览器,现在市面上很多(AI)浏览器都是基于此二开的。后续我们都统一看待,表述为Chrome。理解好Chrome对于我们在上层构建Browser Use事半功倍,也能很清晰的知道现在各种操作浏览器的手法有什么差异
先丢一张全局的架构图:
里面细节比较多,感兴趣可以扫一眼,这个主要关注点事外围大框。有个大概概念,现在我们一路走下来看看:
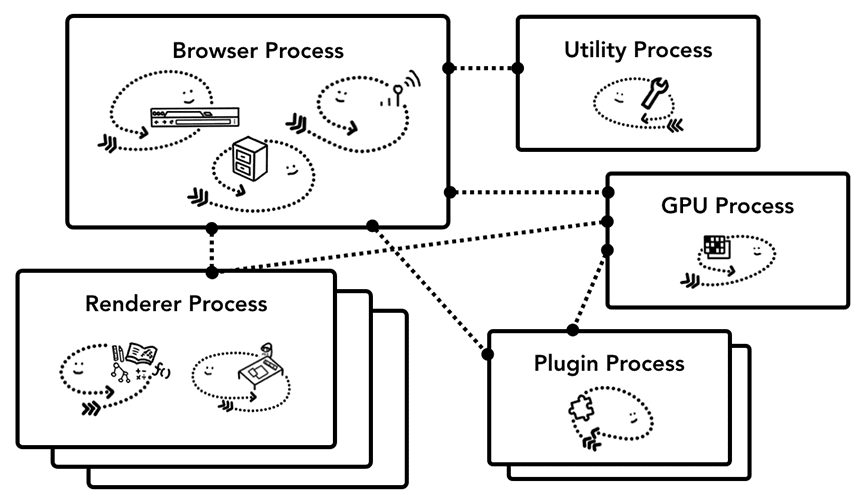
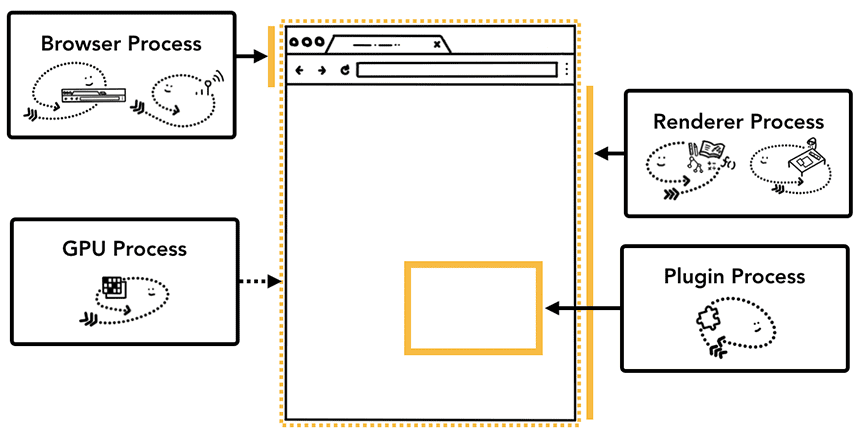
首先Chrome是多进程架构的,按照不同的类型用不同的进程来承载。比如浏览器打开一个页面会涉及到诸如以下这些进程
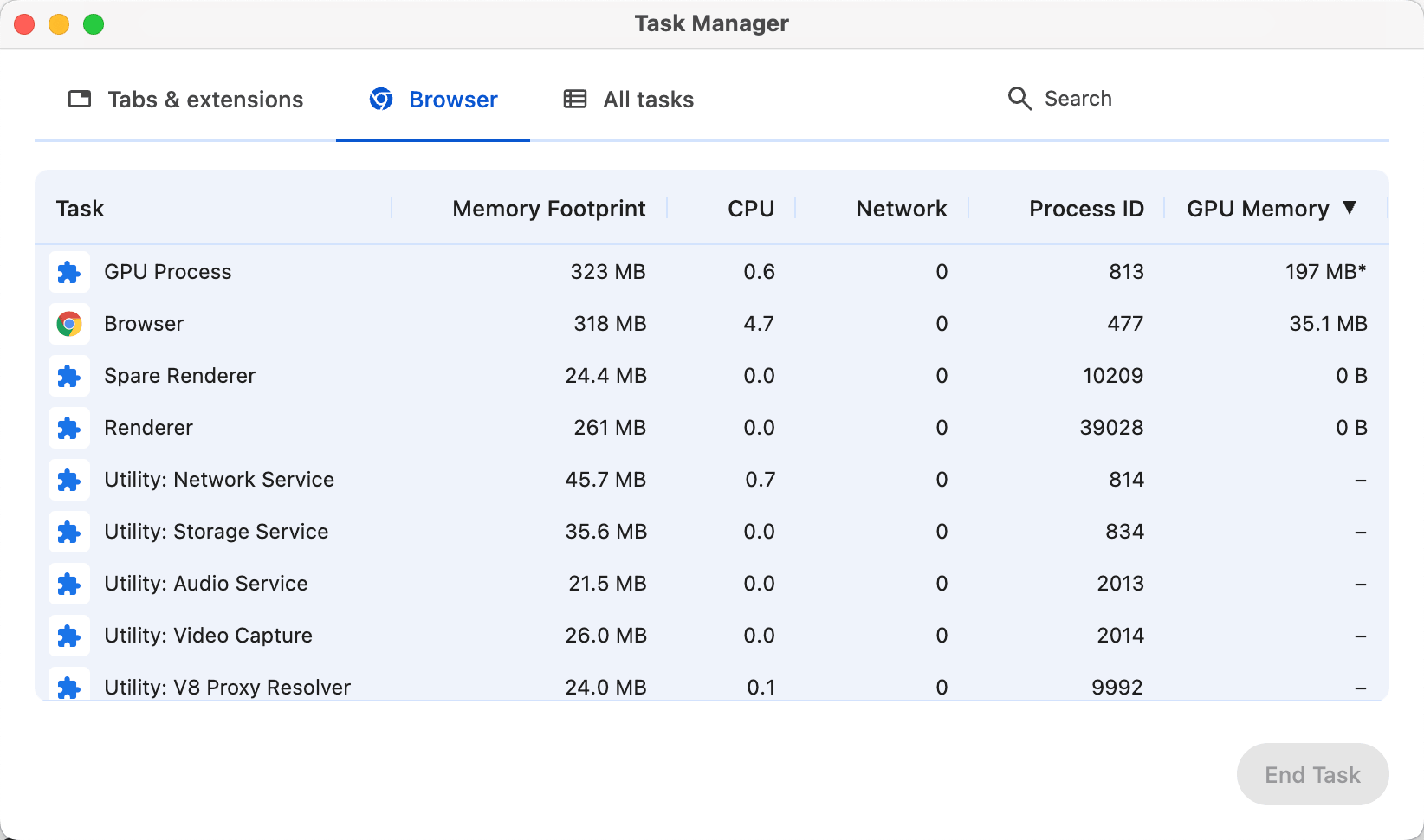
这个我们在Chrome自带的任务管理器里可以看到对应的进程
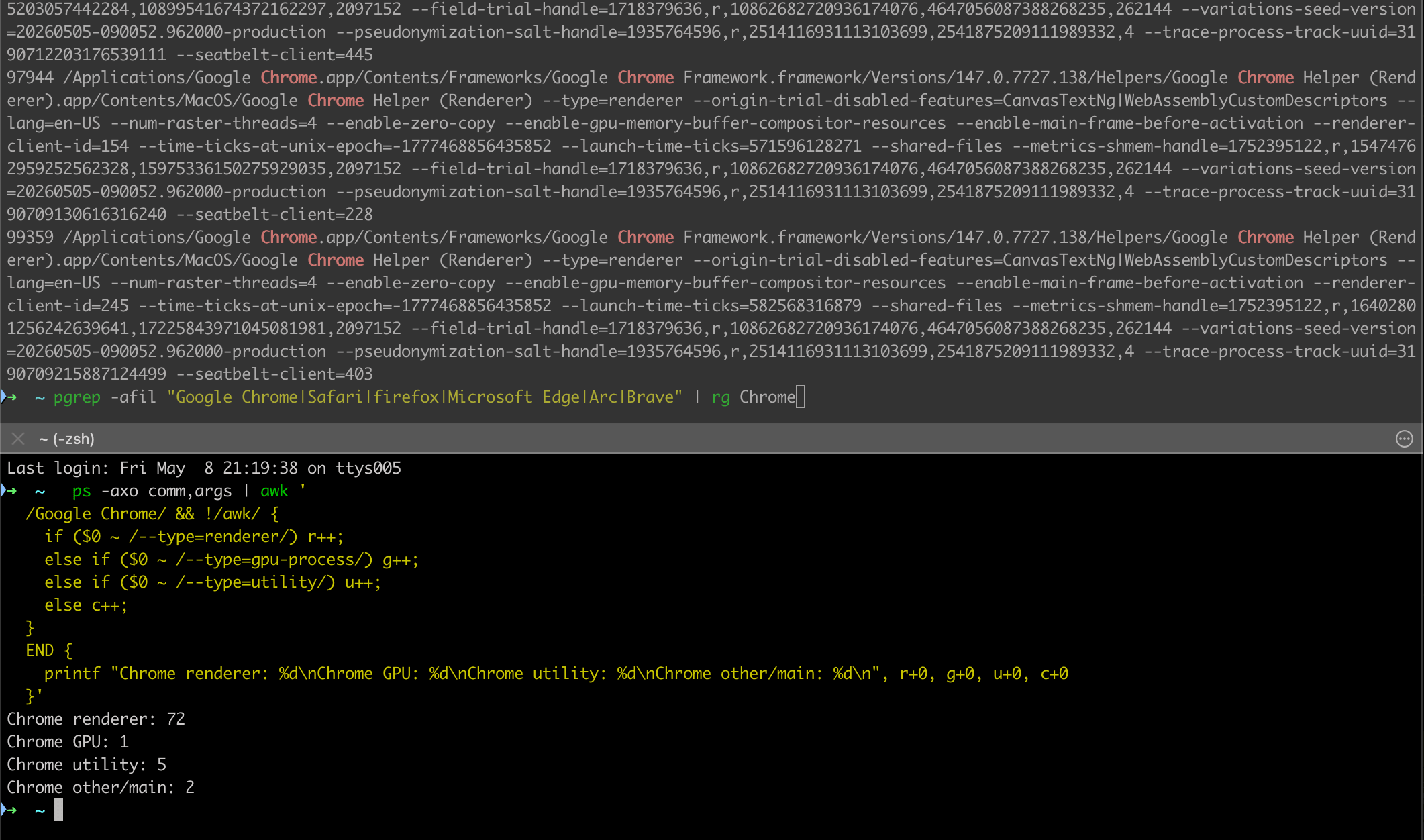
我们也可以直接命令行统计一下现在的进程情况
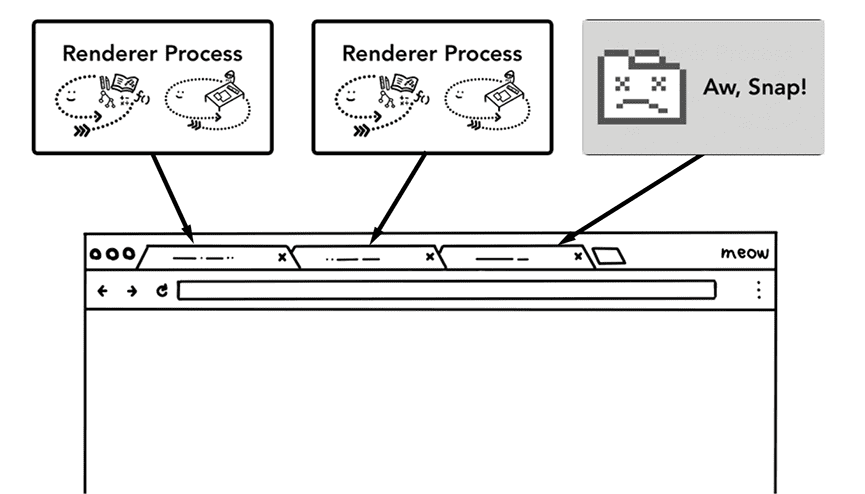
这样做的好处是隔离和安全,比如一个tab爆炸对应的进程挂了,也不会影响别的tab页面
安全方面借助进程来实现沙盒隔离的能力,比如Renderer Process着重处理用户输入的进程会限制针对系统文件的访问,这样有助于提高安全性
其中我们最主要关心的还是Browser Process和Renderer Process了。Browser负责全局(进程)调度的大脑,能管理所有的进程。而Renderer Process是负责渲染的,通常情况下每个tab/iframe都是一个独立的进程,也就是所谓的站点隔离(Site Isolation)。因此平时最重要也是进程最多的就是Renderer ,比如一个tab有一个main frame,这个tab里还有2个iframe,这个情况下就会有3个Renderer Process(实际是会受same site影响的)
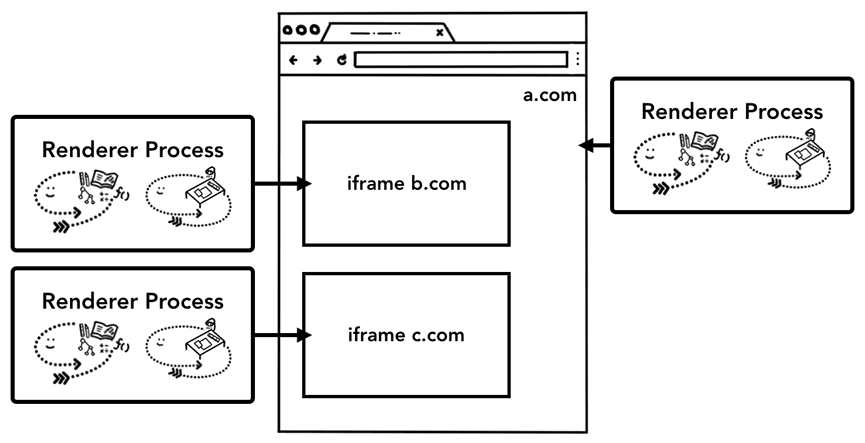
在此之外,我们需要了解的一个东西是Service Worker,普通的页面都会对应到tab,但是Service Worker是独立在页面之外的,现在的v3浏览器插件基于Service Worker的机制之上了,简单表示为:
Browser Process
├── Renderer Process (网页)
│ ├── DOM
│ ├── JS
│ └── 页面逻辑
│
└── Service Worker Process
├── fetch 拦截
├── cache
├── push
├── background sync
└── extension background logic
这个后续我们讲浏览器插件里会重点提到。
到这里我们对于Chrome的整体机制有个初步的认知了,我不打算完全讲到透,内容量比较多,对大部分人来说也不一定有价值,有兴趣的可以自己看我最后贴的一些链接自行深入去了解
Codex Browser Use
回归到Codex APP本身的Browser Use能力,主要由Browser Use(iab,应用内部浏览器页面)和Chrome(浏览器插件)组成,还是这张架构图:
两者各有优缺点。Codex通过抽象封装好的browser-client.mjs 去调用,等于对使用方屏蔽了,通过Skill的差异来控制。
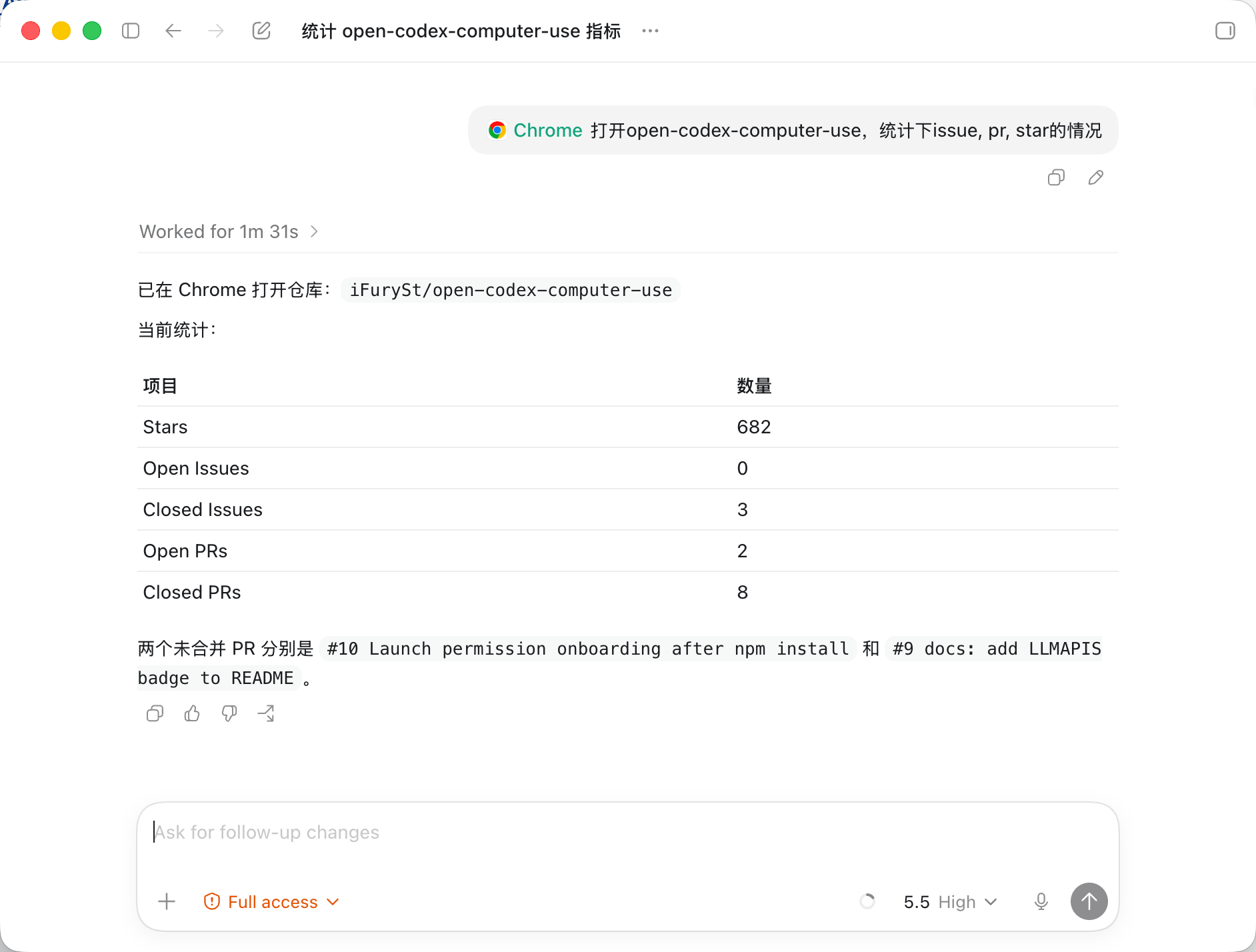
这里值得注意的是,Codex内置了node runtime,因此实际使用中可以编排出类似这样的命令去调用:
await tab.goto('https://github.com/iFurySt/open-codex-computer-use/issues');
await tab.playwright.waitForLoadState({ state: 'domcontentloaded', timeoutMs: 15000 });
const snap3 = await tab.playwright.domSnapshot();
const relevant3 = snap3.split('\n').filter(l => /Open|Closed|Issues|issue|No results|open-codex-computer-use|Pull requests|Starred/.test(l));
nodeRepl.write(relevant3.slice(0, 160).join('\n'));
这样可以让使用方进入一种有状态的上下文中,可以不断操作,而不需要反复去获取和定位一些诸如tab和元素等
接下去分别看看两者
IAB(In-App Browser)
这个在Codex.app里表现为Browser Use插件
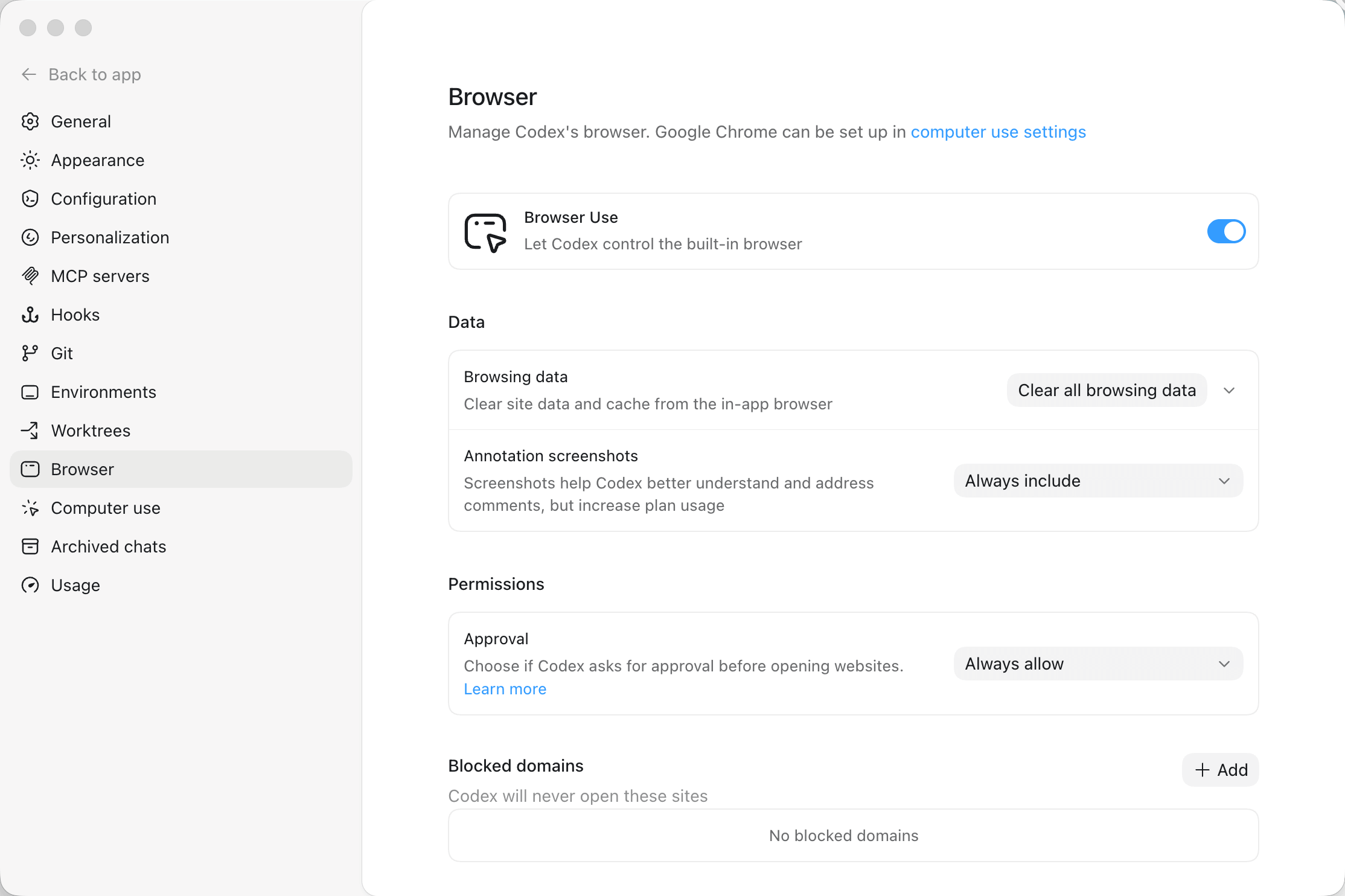
就是右侧边栏那个内置的网页
这个方案是因为Codex.app本身就是Electron写的,内置的就已经有浏览器的能力了,他的做法是在中间自己抽象了一层业务层,以单个codex.app的窗口(window)+会话(session)唯一对应到一个浏览器页面,这个页面对应到Electron的WebContents,细节对上层屏蔽了。
这里就对应到我们前面聊Chrome里提到的部分,这个对于本身已经有类似产品的,是有不错的参考意义的。不过我不打算展开聊,有需要的人自行深入,有需要或问题也可以email我,我可以分享一些DeepDive时候的一些见解。
iab的一个优点是相对简单,且对于用户来说丝滑一些,直接在APP里就可以预览正在操作的浏览器
但是弊端也很明显:
- 目前设计只能打开一个页面,打开其他页面会顶掉前面的页面
- 内置的无法安装一些浏览器插件,尤其是针对某些操作依赖某些浏览器插件时
- 无法无缝接入用户的浏览器
Chrome Extension
在Codex.app里放在了Computer Use里的Google Chrome(不知道为什么放在这里![]() )
)
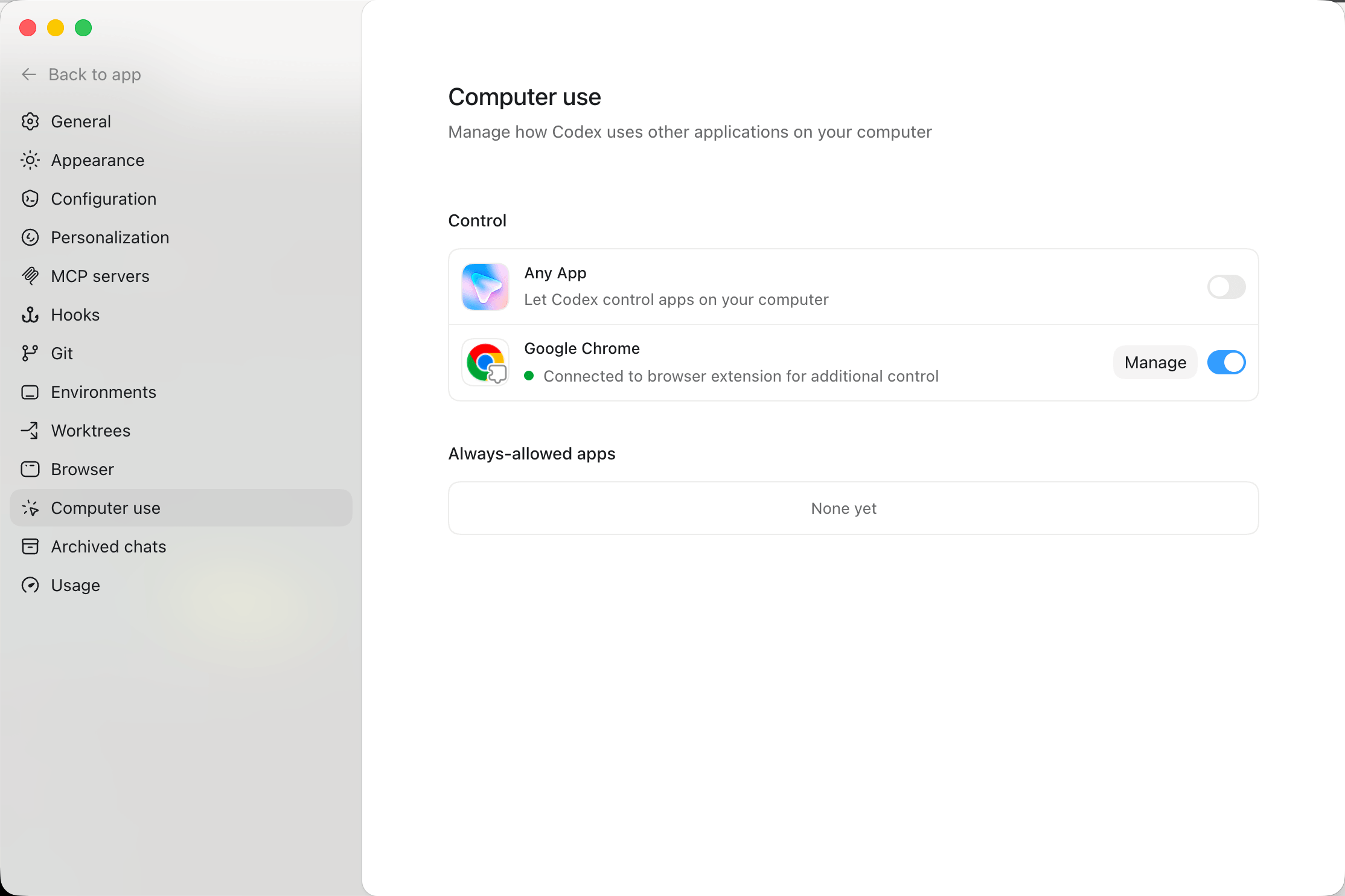
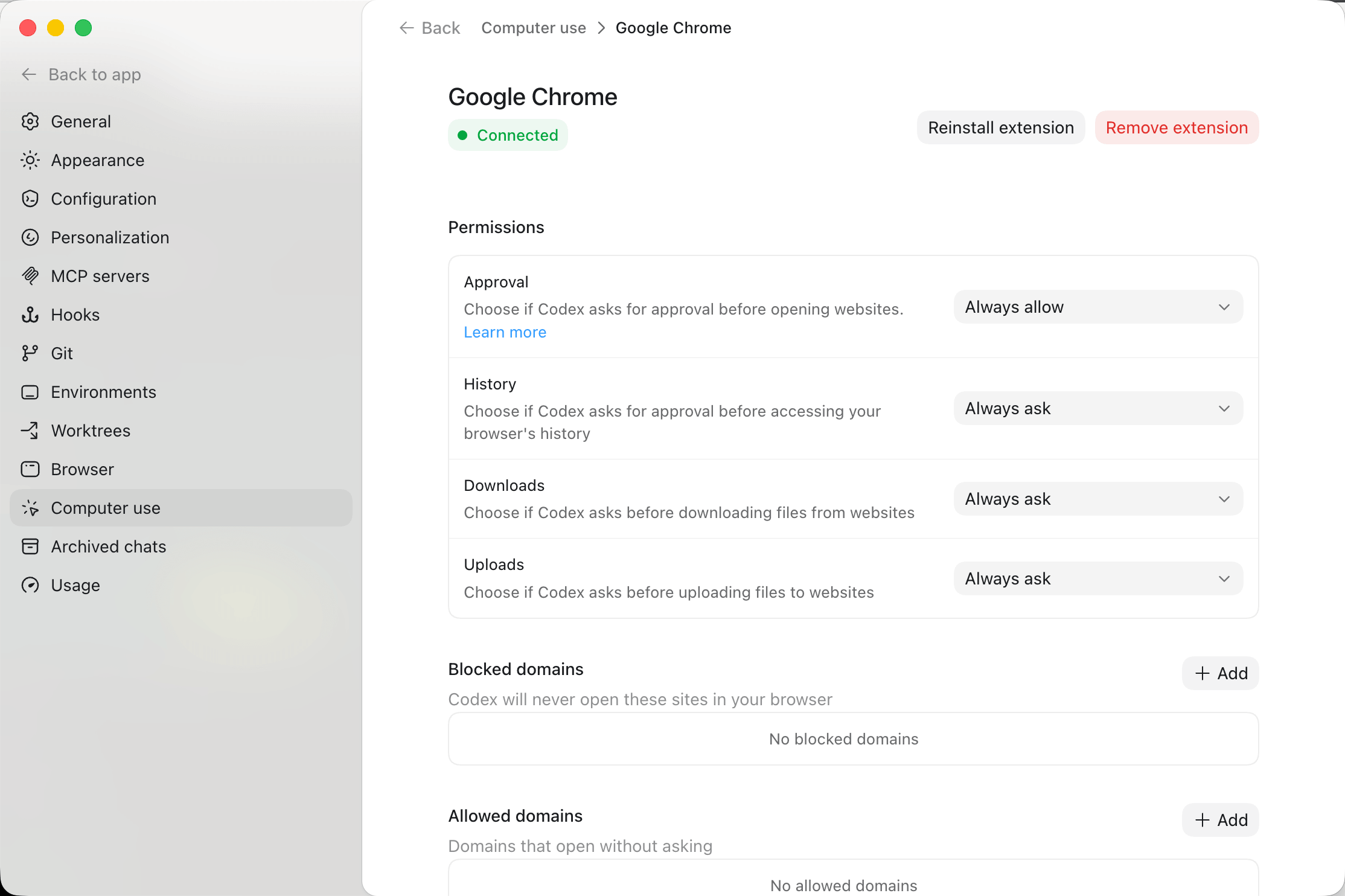
搭配Chrome插件使用
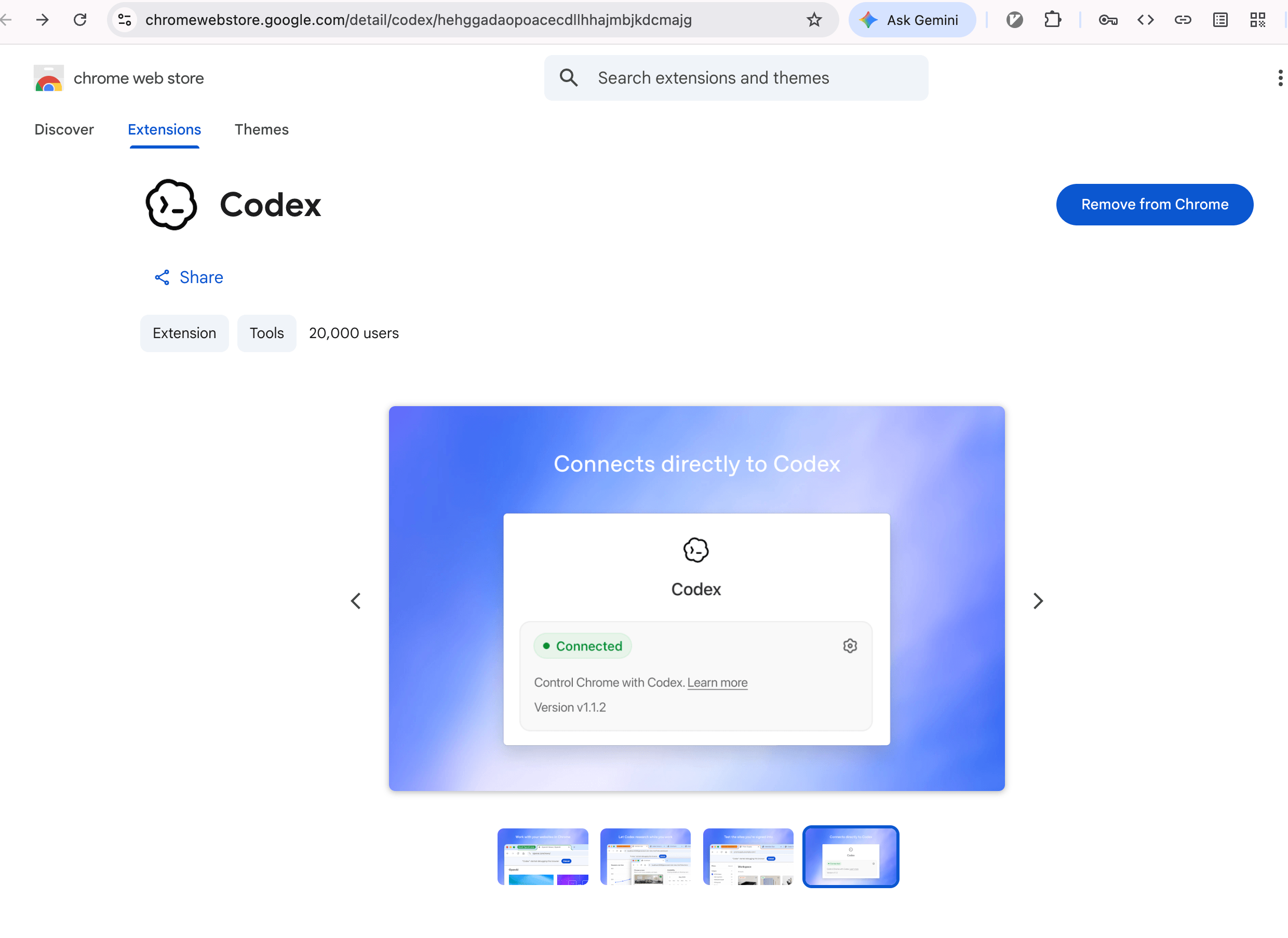
浏览器插件的形态会更加通用,适应力更强。一些Chrome内核的浏览器也都可以用,而且可以做到在浏览器里模拟cursor的操作。
这里不得不提一下OpenAI的巧思,或者说产品力
任务会以分组Group来聚合,这点就非常妙,这个任务下的tab都集中在这个分组,这样任务结束的时候直接整个分组关了就不会污染用户的tab。
在此期间,这些tab都是非激活状态的,也就是这个浏览器插件是具备后台操作能力的,和Computer Use的Background能力一致,非常丝滑的产品体验!
操作过程如果去查看tab,也能看到和Computer Use类似的鼠标悬浮和移动,让人可以直观感受到在做什么
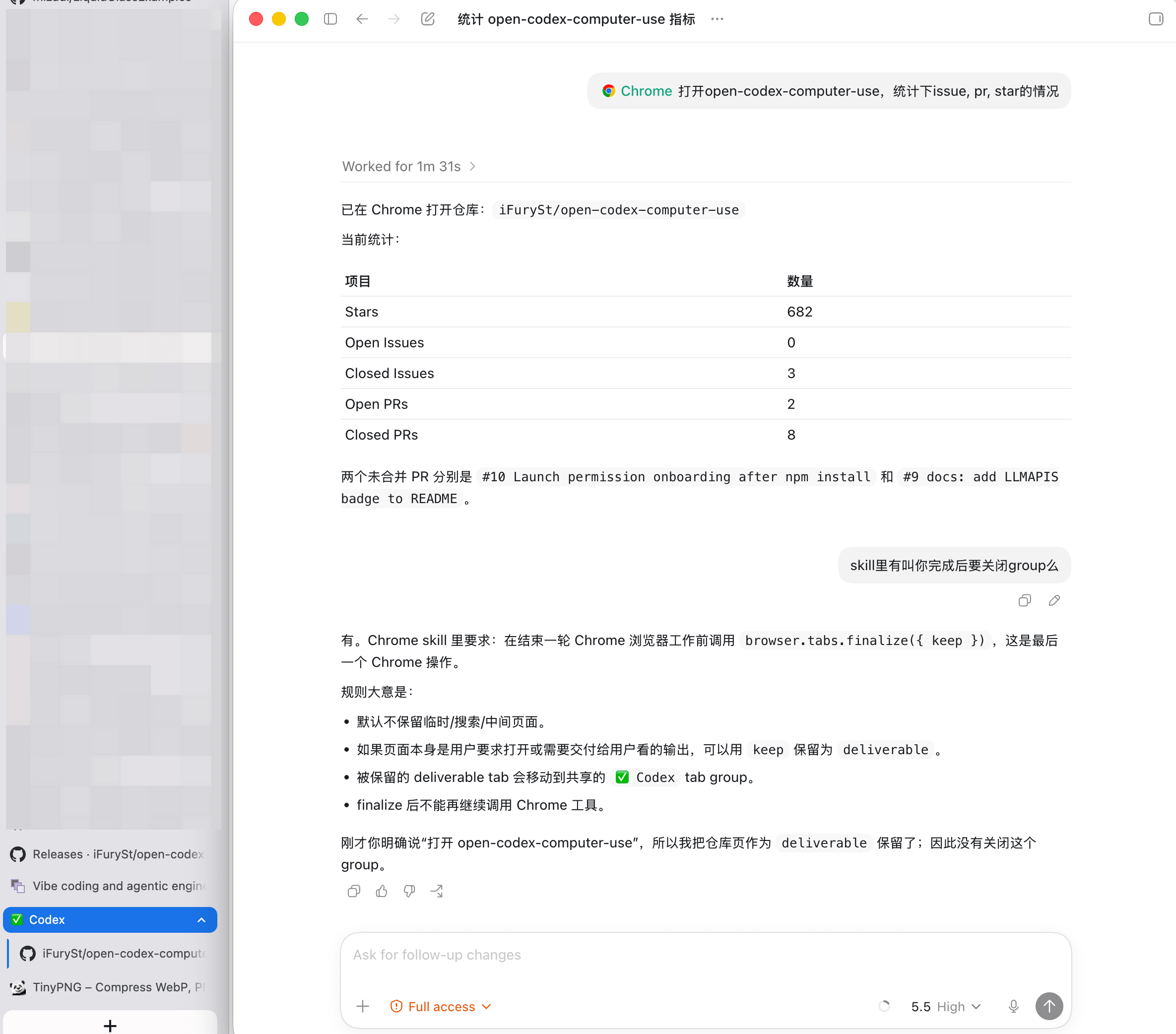
结束后除了收掉Group和内部的tab以外,还有可能出现移交tab到Codex这个通用分组下。这些都是写在skill里的指导。
CDP(Chrome DevTools Protocol)
这个是第三种方式,我不详细展开了,本质上是通过CDP协议去连到Chrome,是最技术的方案,需要Chrome以Remote Debugging / CDP监听的方式去启动的,对于普通用户几乎不可能,对于研发人员接触的比较多。
现在Chrome官方也提供了MCP,以及配套的chrome-devtool-cli。类似Playwright、Selenium、puppeteer本质上都是基于CDP做的。也是最根源的方式,包括很多云端Sandbox里包装了Chrome的也都是通过CDP去交互的
至此我们对于codex拥有的整个浏览器操作已经有了全局的认知了,很多技术细节没有再额外展开,有兴趣的可以按需找AI一点通一下。
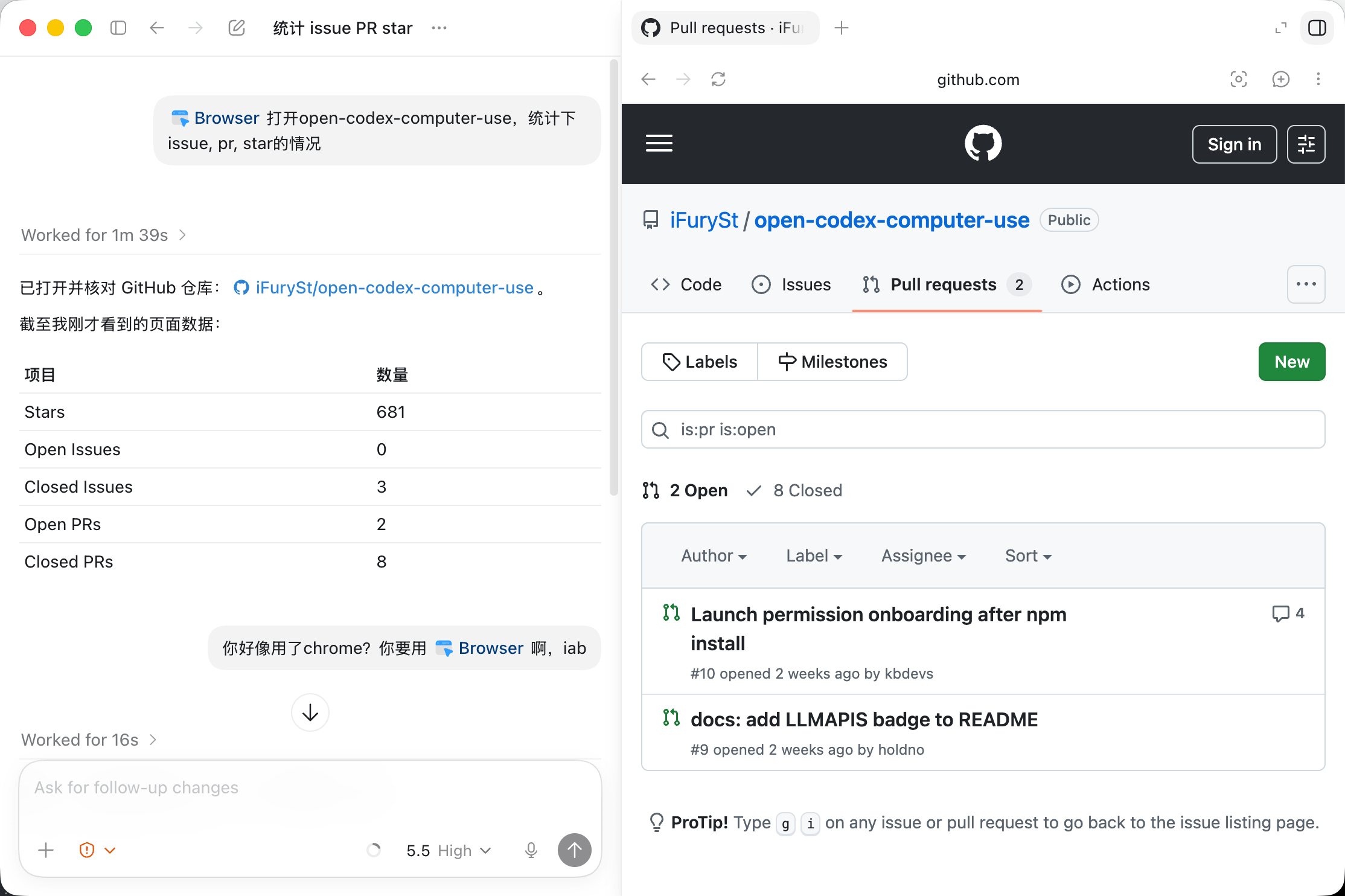
Open Browser Use
为什么我们需要一个开源替代方案呢?
- 因为甚至连Codex CLI都无法用Codex.app的这两个Browser Use的能力,我们需要一个平台中立的方案,可以让所有的AI Agent轻易使用,可以让所有的AI应用轻易集成
- 技术实现不等于产品实现。我会尽量用产品的角度来推进这个开源项目,因为技术方案前面CDP一节里提到了好几个,但是他们对于AI开箱即用的能力太弱了,或者他们天然的定位就不是面向AI的。Chrome MCP好一点点,但是也有很多痛点在里面。
Open Browser Use的实现方案和Codex.app的extension路线是一致的,我希望的定位是打造成超集的存在,就是在满足原有的一切能力以外还能有一些额外的能力可以赋能上层业务的开箱即用
https://github.com/iFurySt/open-codex-browser-use
目前是以浏览器插件的形式存在(插件商店版本还在审核,目前直接通过zip/crx安装)
具体使用方式参见GitHub里,这边就不展开赘述了。
尾声
其实这篇文章我愿称之为半成品,因为很多原来我预想和规划的内容我没有完整的展现出来,最近的时间精力也不够完全支撑我写完这篇文章到我满意的程度,但是又不希望因为不完美而不完成,因此还是决定发出来,因为我相信哪怕它不完美,依然可以触达很多的人。做人和做事都是如此,追求完成应是第一要务,在此之上,能追求完美的人,才有机会成为传奇。
回到Codex和OAI本身,OpenAI虽然人才流失了很多,但是依然妨碍不了继续牛逼,或许是组织足够厉害,也可能是现在还在的人里充满了人才,不管怎样,最近这段时间持续给大家递送更好的产品,喜闻乐见。在这背后,也不断激发我对于产品力的思考。
Coding≠Engineering, Technology≠Product.
AI带给我们的很多,但是还有很多东西其(暂时)无法带给我们。我依然相信持续保持好奇心、敢于尝试的勇气,以及立刻行动的执行力,是支撑着我们探索无尽未知的原始动力
References
想了解现代浏览器的可以看Chrome这四篇Post文章,简单易懂:
- Inside look at modern web browser (part 1)
- Inside look at modern web browser (part 2)
- Inside look at modern web browser (part 3)
- Inside look at modern web browser (part 4)
2 个帖子 - 2 位参与者