本人手头有两张4060,一直很想跑稍大一些(相比9B 4B)的模型,基于最近llama.cpp支持的一些新功能运行35B A3B模型测试。
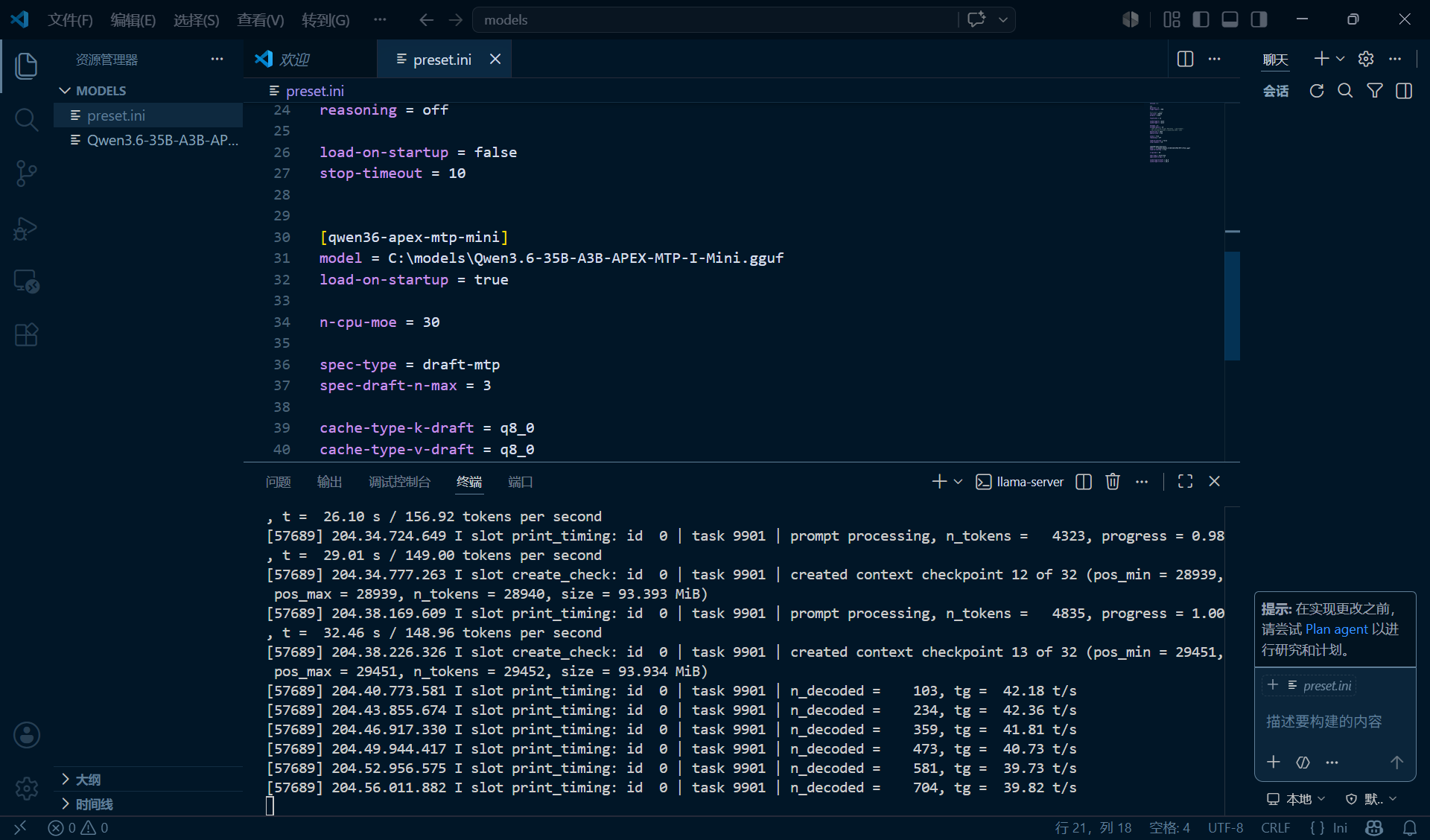
模型Qwen3.6 35B A3B APEX-MTP
Qwen3.6-35B-A3B-APEX-MTP-I-Mini.gguf -》13.7 GB

省流:
- 台式机和USB4拓展坞都可以跑在8g显存的显卡上,MTP的速度挺快的,30+tokens/s,代码能跑到45-50
- 因为显存不够,上下文prompt太多了以后处理起来很慢,拓展坞情况比我的台式机慢3-4倍
补充:
- 台式机后续尝试了I-Compact和I-Quality,发现速度有下降,但是不明显
- 4060还是玩9B吧…跑起来还快点,当然不嫌慢,等这个慢慢跑也行(我记得特总视频也提过这一点)
8 个帖子 - 4 位参与者
来源: LinuxDo 最新话题查看原文