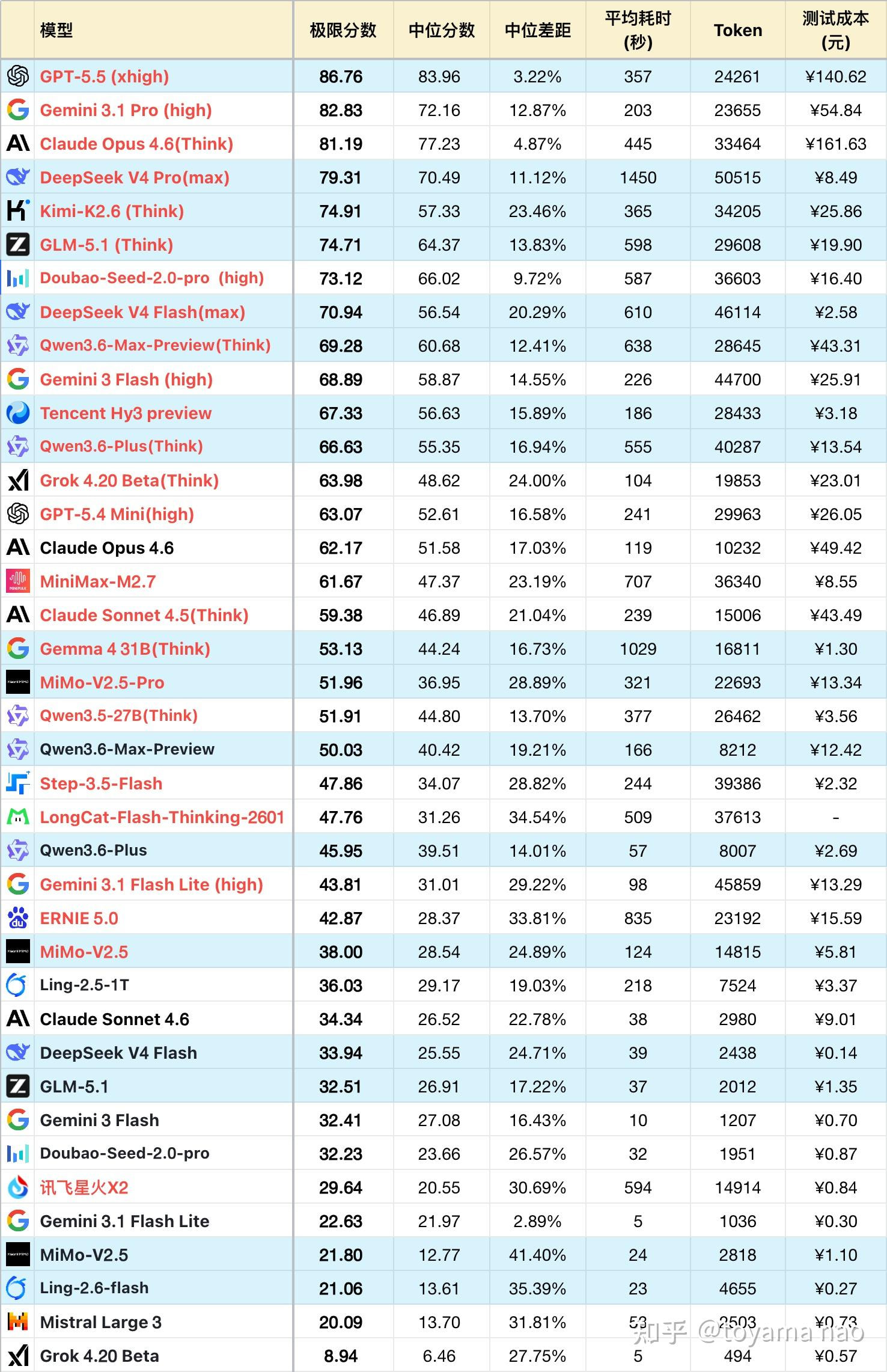
看到过太多人把这个榜单奉为圭臬,说下我的看法,理性交流。
1. 只有60道题目的逻辑测试
相比较humanity’s last exam(HLE)等前沿benchmark,差距巨大。
2. 极度反常的think参数差异
同样的grok4.20,开启think前后是8.94 vs 63.98,一个说胡话的倒数第一模型,开启think模式后立刻暴涨, gemini3-flash 前后是32 vs 68。
3. 测能力变成了“掷硬币”——离谱的得分方差
总共就 60 道题的盘子,模型答题居然能出现 30% 到 40% 的巨大震荡!这说明模型做这套题的表现,等同于抛硬币闭眼瞎蒙 。稍微运气好蒙对几题,或者运气差错几题,分数就会产生剧烈跳水。
4. 有两个mimo-v2.5
可能是没有正确标注 think模式,mimo默认开启thinking参数
5. 极度反常的mimo得分
真的稍微用过mimov2.5pro和qwen3.6-27B本地版的,都不会觉得这俩模型是一个逻辑水平。在humanity’s last exam(HLE)榜单上,gemma4-31B 和qwen3.6-27B的得分如下

6. 前排模型没有拉开差距
在复杂的数学逻辑题目上,gemini,gpt,claude相对于国产模型都有巨大优势,但是主打逻辑的榜单看不出这种差距。
7.思考时间和输出token长度
排名靠后的模型普遍输出token少,思考时间短,对于逻辑题目来说,目前的大模型会普遍产生很长的思维链,这个榜单的数据非常异常。这里给一个例子各位参考下
在离营地100公里的沙漠中有一个宝贝,中间无人烟,开汽车去取。汽车每公里要消耗1升的油,汽车最多可以装100升的油。怎样才能把宝贝取回来? 如何数学建模找到最优解
其他的小问题还有,gemma4 31b的速度非常慢,很奇怪。
总结
虽然主流benchmark会被llm过拟合刷分,但是参考性还是比这种图一乐的榜单强。
3 个帖子 - 2 位参与者
来源: LinuxDo 最新话题查看原文