
MLS-Bench: A Holistic and Rigorous Assessment of AI Systems on Building...
Modern AI progress has been driven by ML methods that are generalizable across settings and scalable to larger regimes. As large language models demonstrate advanced capabilities in reasoning, coding, and engineering tasks, it is increasingly...
[!abstract]+
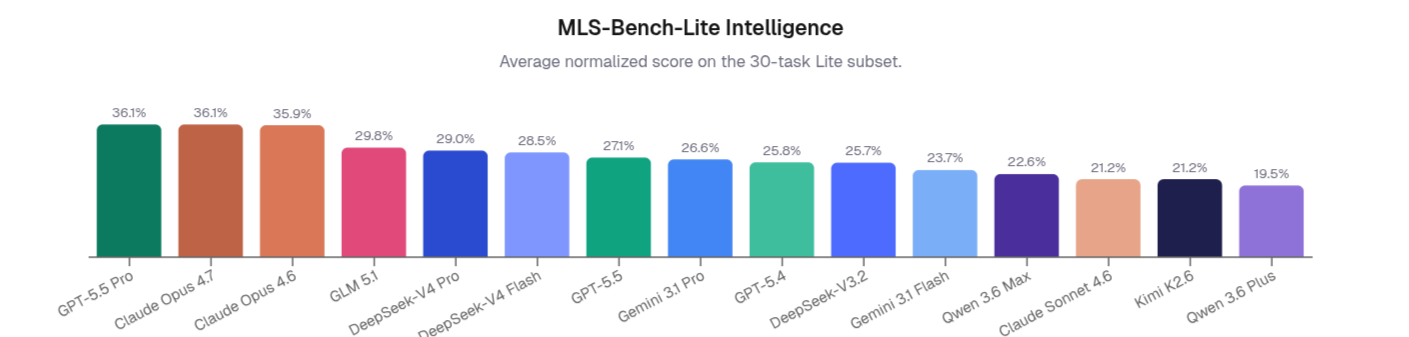
现代人工智能的进步是由可跨环境通用并可扩展到更大体系的人工智能方法推动的。随着大型语言模型在推理、编码和工程任务中展现出先进的能力,了解它们是否能够发现这些方法而不仅仅是应用现有方法变得越来越重要。我们介绍了 MLS-Bench,这是一个用于评估人工智能系统是否能够发明可推广和可扩展的 ML 方法的基准。MLS-Bench 包含横跨 12 个领域的 140 项任务,每项任务都要求代理改进 ML 系统或算法的一个目标组件,并证明这种改进可在受控环境和规模中推广。我们发现,当前的代理仍远未可靠地超越人类设计的方法,而且工程式的调整对它们来说比真正的方法发明更容易。我们进一步研究了测试时间缩放、自适应计算分配和上下文提供对代理发现性能的影响,并对其行为进行了案例研究。我们的分析表明,瓶颈不仅在于提出新方法,还在于规划、验证和扩展新方法所需的科学洞察力。仅靠更多的搜索、计算或上下文并不能消除这一瓶颈。我们建立并维护了一个社区平台,用于累积和比较迭代,并在此 https://mls-bench.com/ 上发布数据和代码。
1 个帖子 - 1 位参与者
来源: LinuxDo 最新话题查看原文