解读一下上面的图:
右侧的曲线图显示,在复杂工程的具体实现上,Opus4.6强于4.7
左侧的数据显示,在整个项目的完整把控上,Opus4.7略微强于4.6,但不多。
参考内容:
最近,Meta FAIR 联合斯坦福、哈佛等机构发布了一项很有意思的新 benchmark,本质上是在重新定义 AI Coding 的评估方式:
ProgramBench: Can Language Models Rebuild Programs From Scratch?

过去的大模型编程 benchmark,大多测的是局部能力:补全函数、修复 bug、实现 feature…本质上,仍然是在已有代码结构里做局部修改。
而 ProgramBench 第一次把问题推进到了真正的软件工程层面:如果只给 AI 一个程序的功能描述和 usage docs,它能不能像真正的工程师一样,从零开始,重新构建一个真实、可执行的软件系统?比如 ffmpeg、SQLite、ripgrep。
而且------不能联网。
换句话说:模型到底有没有工程智能?
为了测试这一点,研究团队直接删除了原始源码和测试,只保留 executable 和 usage docs,模型需要自己决定语言、架构、模块拆分、数据结构乃至整个 repo 的组织方式。
更关键的是,ProgramBench 不再按照源码相似度打分。它采用的是 behavioral equivalence,行为等价。也就是说,你可以用完全不同的语言、算法、架构,甚至完全不同的工程实现。只要最终输入输出行为与原程序一致,就算通过。
研究团队甚至使用了 agent-driven fuzzing,自动生成大量端到端行为测试。
这是第一次,一个 benchmark 真正开始逼近现实世界的软件工程,而不再只是代码做题。结果出来之后,整个 AI 圈都沉默了。
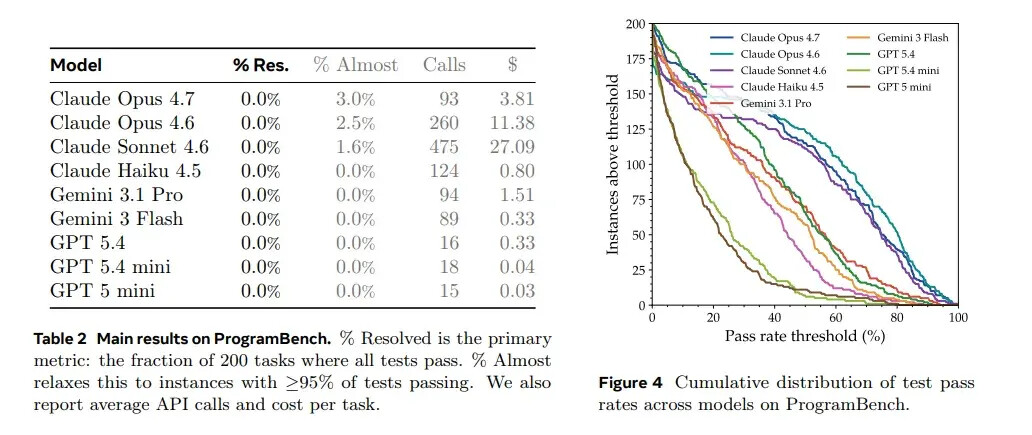
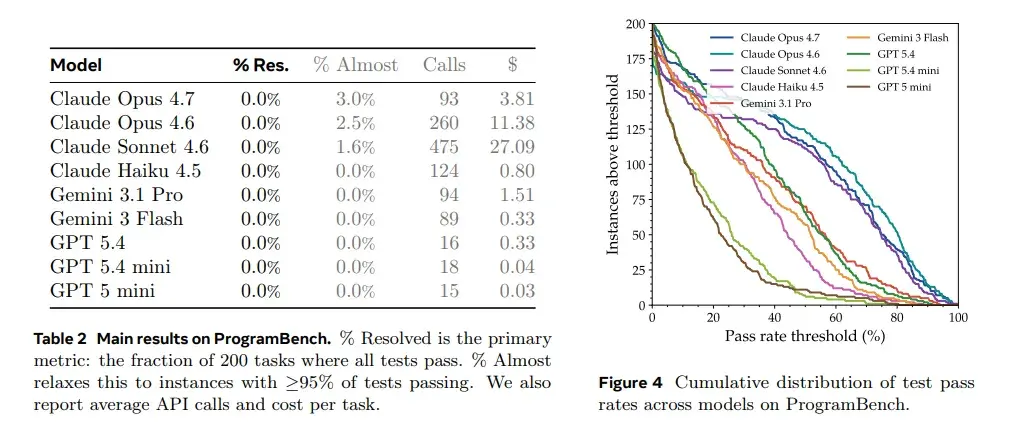
所有模型:0% 完成率。
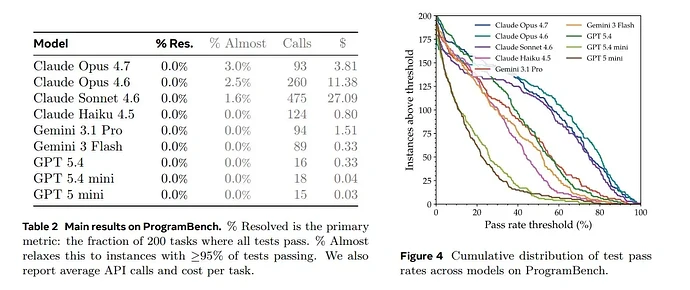
Table 2 负责制造震撼,那么 Figure 4 负责解释震撼背后的细节。它告诉我们,模型并不是完全不会做,而是经常能做出一部分,甚至在少数任务上接近完成;但只要要求 100% 行为等价,所有模型都会倒下。但这最后一公里,正是软件工程和普通代码生成最大的区别。另外,如果矮子里面拔将军,Claude 系列(尤其是 Opus 4.7 和 4.6)表现相对最好。
即便论文专门增加了一个 Almost 指标------统计那些完成度超过 95% 的任务。目前表现最强的 Claude Opus 4.7,也只有 3% 的任务接近完成。
论文里,有一句特别关键的话:
Models favor monolithic, single-file implementations that diverge sharply from human-written code.
翻译过来就是:模型极度倾向于生成单体化代码。大量逻辑被塞进单文件;目录结构极浅;模块拆分极少;函数超长;整个 repo 看起来像一坨巨型脚本。
1 个帖子 - 1 位参与者