在 2026 年的 A 股市场,我们不仅在与人博弈,更是在与‘时间序列’背后的幽灵共舞。站在 2026 年这个节点,老派的技术分析正面临前所未有的生存危机。随着全面注册制的深化和超高频量化算法的普及,传统的 MACD 、KDJ 甚至曾经被奉为神谕的“仙人指路”形态,似乎都在被某种无形的力量精准收割。当市场陷入“量价迷雾”,散户与大户的博弈已不再仅仅体现在盘口的挂单上,而变成了算力与逻辑的终极赛跑。最近看到 Kronos 金融模型,我决定尝试将 Kronos 接入我的 A 股量化工作流。
首先介绍一下 Kronos 。Kronos 是一个专为金融市场"语言"——K 线序列预训练的 decoder-only 基础模型系列。与通用时间序列预测模型( TSFM )不同,Kronos 专门设计用于处理金融数据独特的高噪声特性。它采用创新的两阶段框架:专用分词器首先将连续的多维 K 线数据( OHLCV )量化为分层离散令牌。随后基于这些令牌预训练大型自回归 Transformer ,使其成为适用于多种量化任务的统一模型。
 我花了半天的时间在本地使用 Kronos 模型和 qlib 数据,在 CPU 上预测未来交易日的 K 线走势,并输出:K 线图(单图,上预测下真实)。
脚本支持两类模型输入:Kronos 官方模型目录和普通 PyTorch 模型文件
我花了半天的时间在本地使用 Kronos 模型和 qlib 数据,在 CPU 上预测未来交易日的 K 线走势,并输出:K 线图(单图,上预测下真实)。
脚本支持两类模型输入:Kronos 官方模型目录和普通 PyTorch 模型文件
项目目录格式:
├── kronos_qlib_predict.py
├── README.md
├── qlib_data/
├── model/
├── tokenizer/
└── Kronos/
目录说明:
model/:本地 Kronos 模型目录
tokenizer/:本地 Kronos tokenizer 目录
Kronos/:官方源码仓库,用于提供 model.py
本地环境要求:
CPU 环境即可
已安装本地 qlib 数据
下载模型和 tokenizer
下载 Kronos 模型,推荐使用 Hugging Face Hub 的整仓下载,而不是手动拷贝单个文件:
python -c "from huggingface_hub import snapshot_download; snapshot_download(repo_id='NeoQuasar/Kronos-base', local_dir='/Users/fighteryu/Downloads/kronos_demo/model', local_dir_use_symlinks=False)"
下载 tokenizer
模型目录中至少应包含:
model.safetensors 或其他*.safetensors
tokenizer 目录中应包含 tokenizer 所需配置和词表文件。
下载官方 Kronos 源码
当前脚本在加载 Kronos 官方模型时,会使用:
from model import Kronos, KronosTokenizer, KronosPredictor
因此需要本地存在官方代码仓库:
git clone https://github.com/shiyu-coder/Kronos.git
运行脚本时,需要把 Kronos 仓库加入 PYTHONPATH:
标准运行方法
--provider-uri ~/Downloads/kronos_demo/qlib_data \
--instrument sh600519 \
--start 2023-01-01 \
--end 2024-12-31 \
--model-path ~/Downloads/kronos_demo/model \
--tokenizer-path ~/Downloads/kronos_demo/tokenizer \
--window 64 \
--horizon 5 \
--seed 40 \
--out ~/Downloads/kronos_demo/kronos_pred.csv \
--chart-out ~/Downloads/kronos_demo/kronos_pred.png
执行预测 K 线结果输出 K 线图
 股票价格参数会输出到表格中,终端输出如下图
股票价格参数会输出到表格中,终端输出如下图
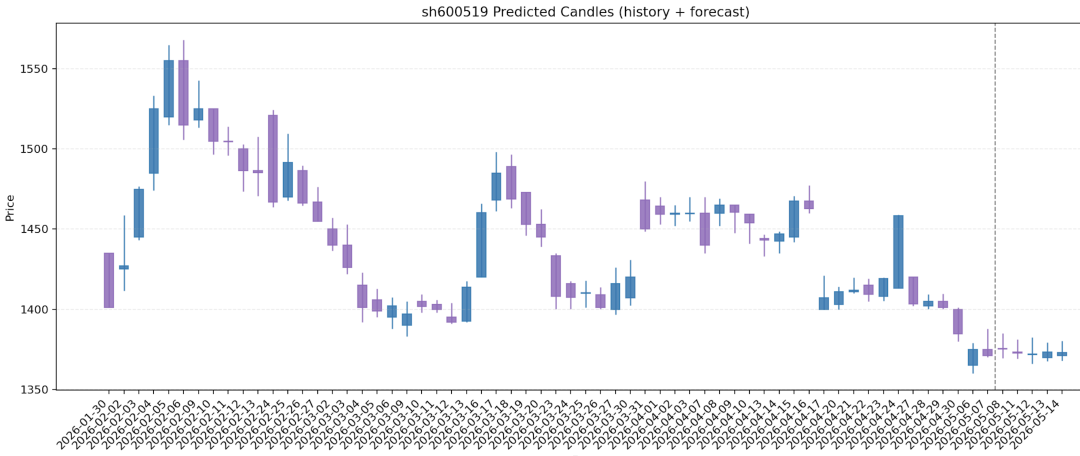
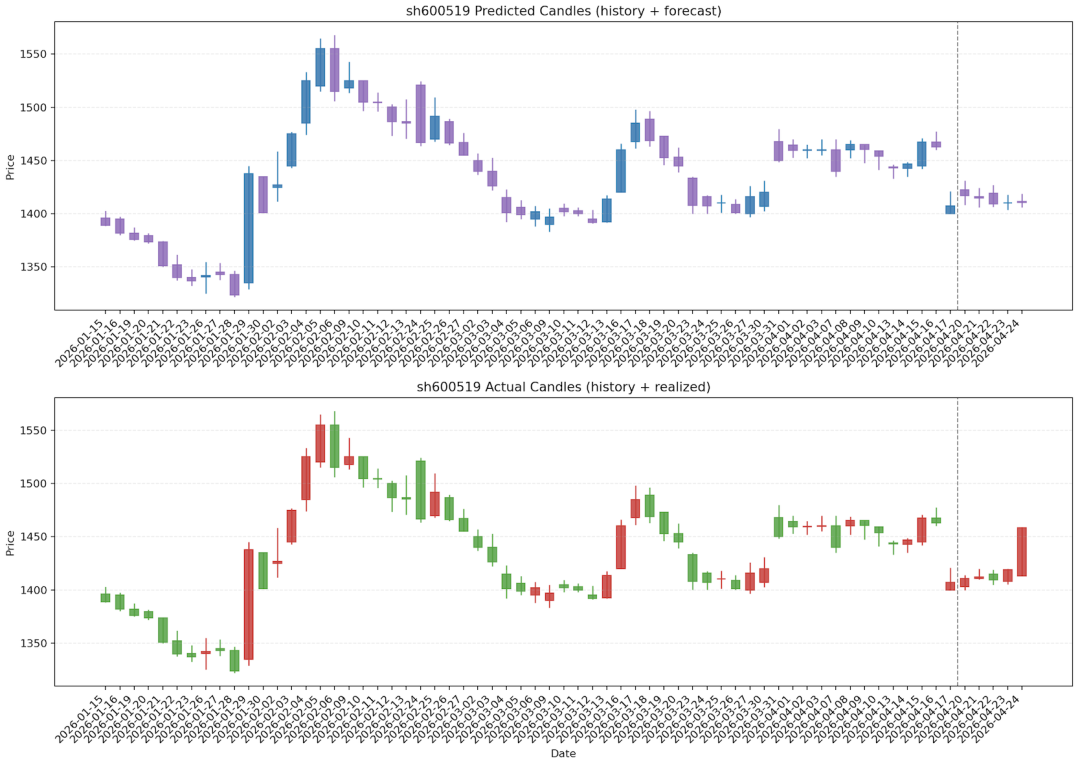
 如果是预测的历史的交易数据,生成的图片会展示预测 K 线和实际 K 线,我们可以从图上直观的看到预测和实际 K 线的差别
如果是预测的历史的交易数据,生成的图片会展示预测 K 线和实际 K 线,我们可以从图上直观的看到预测和实际 K 线的差别
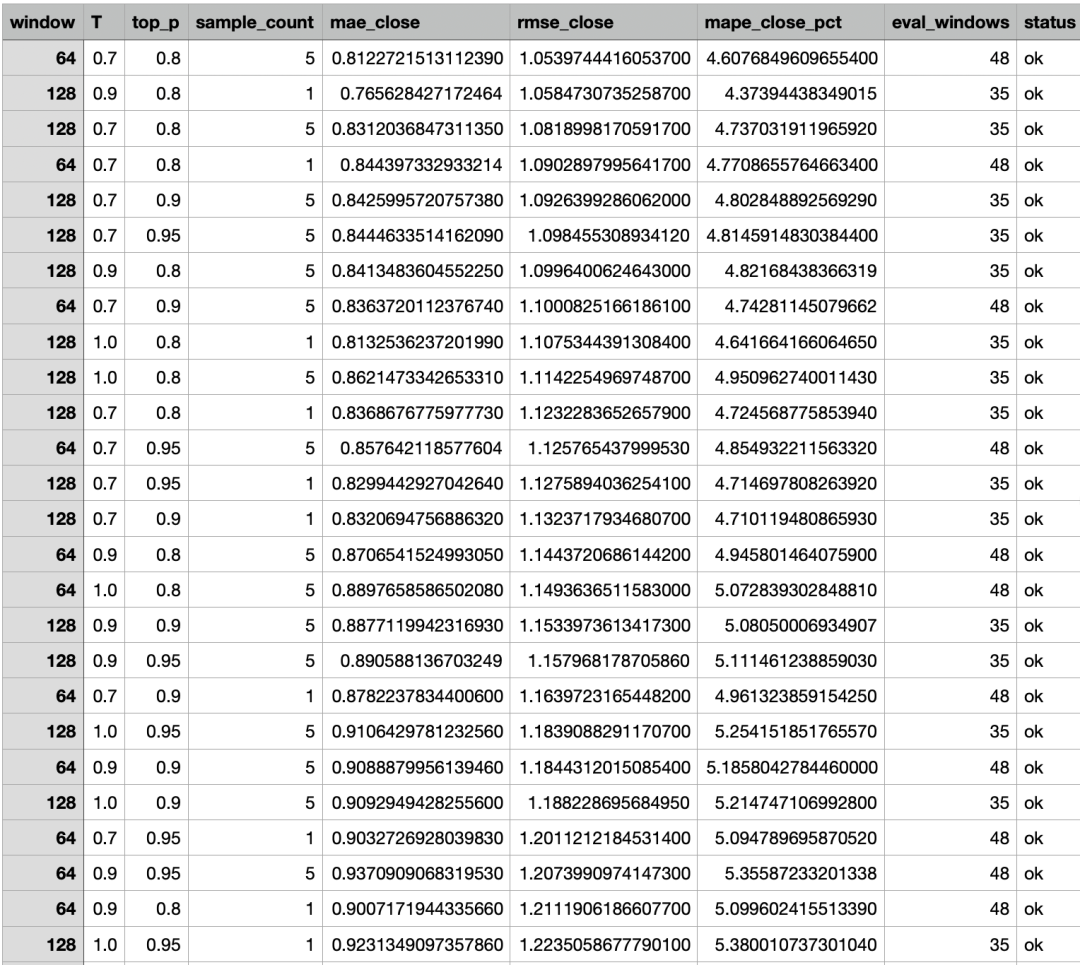
 参数搜索(自动回测)
参数搜索(自动回测)
如果你要自动找更优参数( window / T / top_p / sample_count ),可以使用--tune:
--provider-uri ~/Downloads/kronos_demo/qlib_data \
--instrument sh600519 \
--start 2021-01-01 \
--end 2024-12-31 \
--model-path ~/Downloads/kronos_demo/model \
--tokenizer-path ~/Downloads/kronos_demo/tokenizer \
--horizon 5 \
--seed 40 \
--tune \
--grid-window 64,128,256,384 \
--grid-temp 1.0,0.9,0.7 \
--grid-top-p 0.95,0.9,0.8 \
--grid-sample-count 1,5,10 \
--tune-stride 5 \
--tune-max-windows 120 \
--tune-out ~/Downloads/kronos_demo/kronos_tune_scores.csv
说明:
会在历史区间做滚动回测
评分指标为 close 的 MAE / RMSE / MAPE
结果会保存到--tune-out
程序会打印 RMSE(close)最优参数组合
如何提高预测的数据准确率?提升准确率最有效的是这几件事(按优先级):
先做可复现评估再调参:固定--seed ,固定回测区间,按滚动窗口评估 MAE/RMSE/MAPE ,先建立 baseline 。
调 window (最关键):别只用 64 ,建议网格 64/128/256/384/512 ; Kronos-base 上下文上限通常 512 。
调采样参数,随机性较强。要更稳可试:
按标的做独立最优参数:不同股票波动结构差异大,参数不应一套通吃。
数据质量优先:确认 qlib 数据无缺失/异常点,factor 处理一致,避免未来数据泄漏。
分市场/分周期建模:A 股、港股、美股混在一起直接推理常会降精度;不同频率(日线/5min )也要分开调。
引入真实交易日历:你现在未来日期用 B ,与真实交易日可能不完全一致,建议用交易所日历生成预测日期,减少时间错位误差。
如果允许训练:做微调(提升最大):用你的目标标的/行业数据做轻量 finetune ,通常比纯 zero-shot 提升明显。
给你一个最实用的执行顺序( 1 天内可做):
固定 seed + 固定评估集
跑 window 网格
在最佳 window 上调 T/top_p/sample_count
输出每组参数的 MAE/RMSE 表,选最优
再考虑是否 finetune
如果大家对我的话题感兴趣的话可以👍➕关注哦!
