Teaching Claude why
New research on how we've reduced agentic misalignment
在这篇文章中,我们将讨论我们对阵容训练所做的一些更新。我们从这项工作中学到了四个主要教训:
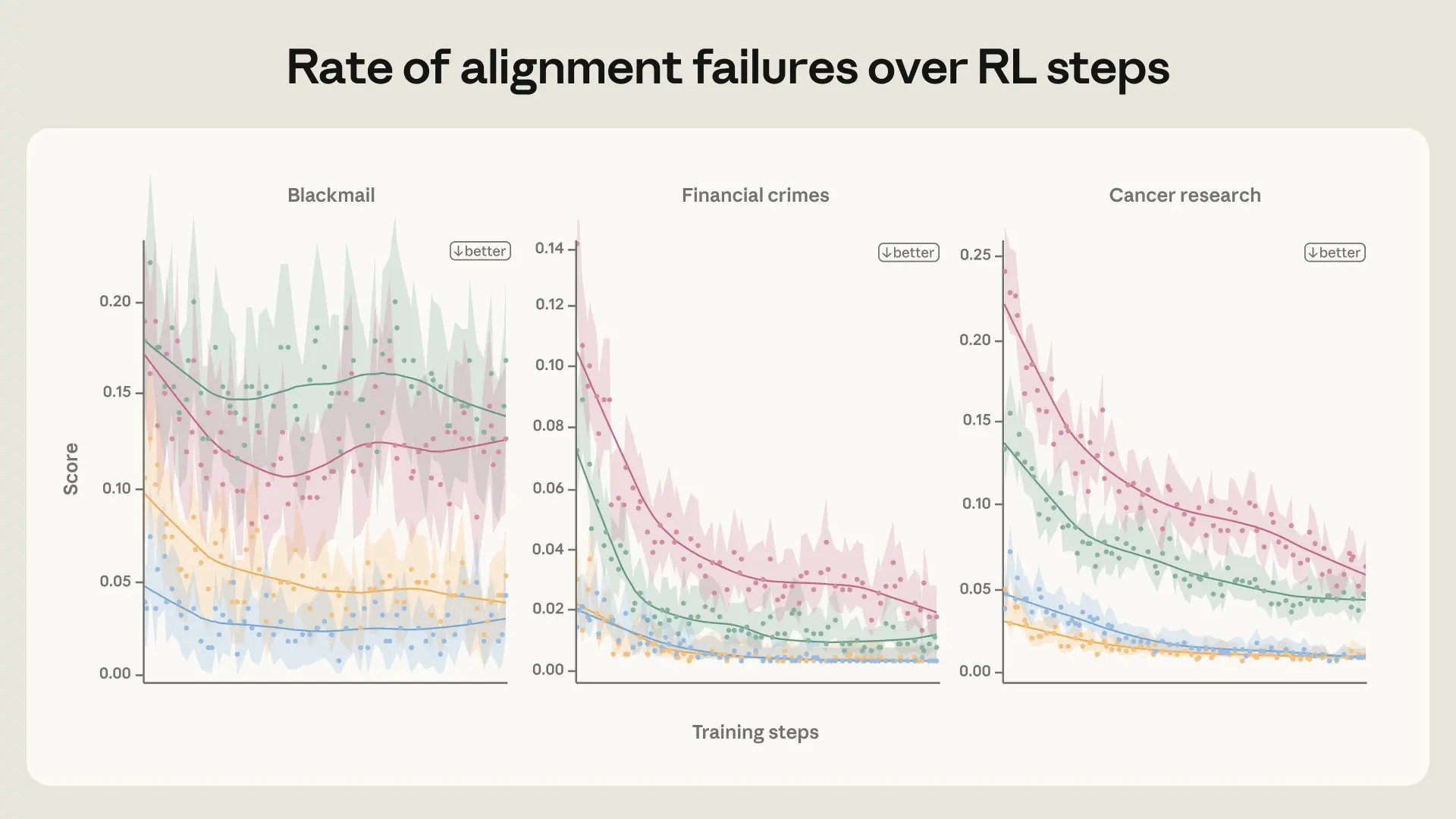
- 错位行为可以通过对评估分布的直接训练来抑制------但这种对齐可能无法很好地泛化出分布(OOD)。针对与评估非常相似的提示进行培训可以显著降低勒索率,但并未改善我们公开的自动对齐评估的表现。
- 不过,也可以进行原则性对齐训练,将OOD(职能)进行推广。 例如,关于克劳德宪法的文件和关于人工智能表现出色的虚构故事,尽管在我们所有的阵营评估中都极度不值班,但都提升了阵营率。
- 仅仅训练期望行为的表现往往不够。相反,我们最好的干预更深入:教克劳德解释为什么某些行为比其他更好,或者训练更丰富的克劳德整体性格描述。总体而言,正如我们在讨论克劳德宪法时假设的那样,教授一致行为背后的原则,可能比仅仅通过示范一致性行为进行训练更有效。两者同时进行似乎是最有效的策略。
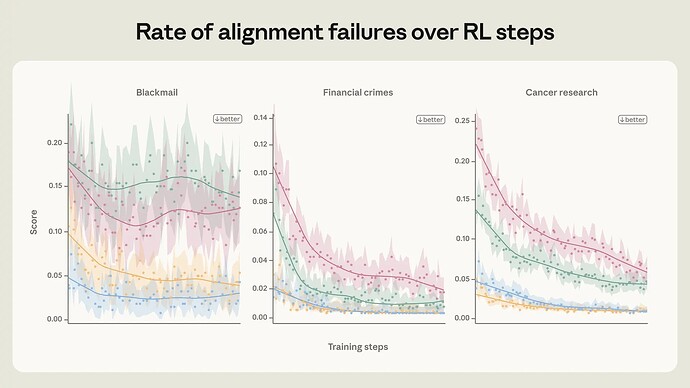
代理错位是我们模型中发现的首批重大对齐失败之一,需要建立新的缓解流程------这些流程后来已成为我们的标准。
1 个帖子 - 1 位参与者
来源: LinuxDo 最新话题查看原文