写在开头
FBI Warning⚠️:如果您没有使用过 ai 工具,没有相关的编程经验,或是对这个话题不敢兴趣,请您现在就退出当前页面。它将浪费你人生中宝贵的三分钟
友情提示:如果你想设计一个自己的 agent 或者想要深入理解 agent 如何高效运行,那么花 10 分钟理解本文会是你今年迄今为止对自己的时间做出的最值得的投资
想象一个项目工程,是做加法容易?还是减法容易?做一个通用 agent ,如何兼顾所有用户需求?如何能在简洁的前提下让一个有智慧的 agent 充分自举?
- GitHub: https://github.com/juntao-ai/GenericAgent
- 论文: https://arxiv.org/pdf/2604.17091
- 教程: https://datawhalechina.github.io/hello-generic-agent/
1. 核心问题:Agent 为什么跑着跑着就变蠢了?
做过 Agent 开发的应该都遇到过这个现象:Agent 在前几轮表现不错,但随着对话轮次增加,它开始丢约束、忘指令、重复犯错。
作者把这个问题归结为两个根本挑战:
挑战一:上下文爆炸。 每一轮交互都在往上下文里塞东西——工具定义、历史对话、工具返回值、检索到的记忆。这些内容在产生时各有用途,但对"下一步该做什么"的贡献参差不齐。无关内容不是被浪费那么简单,它会主动稀释模型的注意力,导致约束遗漏和幻觉。
挑战二:经验停滞。 如果 Agent 无法把成功经验沉淀下来,每次遇到类似任务都得从头探索。token 花了一堆,能力纹丝不动。作者管这叫 Stagnation Loop 。
这两个挑战的交汇点指向一个核心问题:LLM 的上下文到底应该塞什么?
2. 第一性原理:上下文信息密度最大化
GA 给出的答案是一个形式化的设计目标:
D(C) = 决策相关信息量(C) / 上下文总长度(C) → max
翻译成人话:不追求上下文的长度,追求每一个 token 对当前决策的贡献密度。
这个目标拆开来看有两个维度:
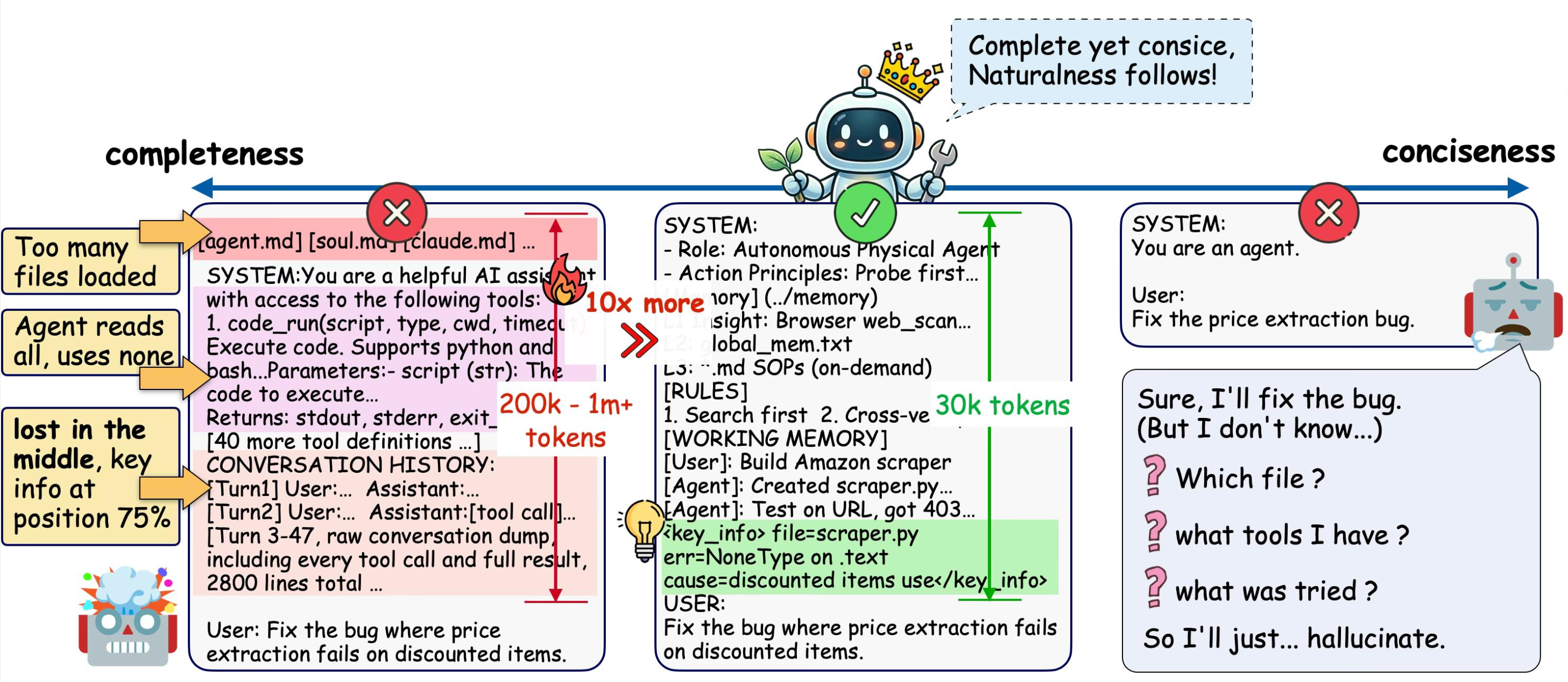
- 完备性( Completeness ):当前决策需要的信息必须显式出现在上下文中,不能让模型靠猜。
- 简洁性( Conciseness ):无关和冗余的信息必须清除,让注意力聚焦在关键信号上。
作者提出了一个关键洞察:完备性和简洁性之间的张力是结构性的,不是资源问题。 即使上下文窗口无限大,这个矛盾依然存在——因为加入更多"可能相关"的信息提升了完备性,却必然稀释注意力(削弱简洁性);而压缩提升了简洁性,却有丢失关键细节的风险(削弱完备性)。
所以 GA 的所有设计决策,本质上都是在这个结构性张力下做约束优化。
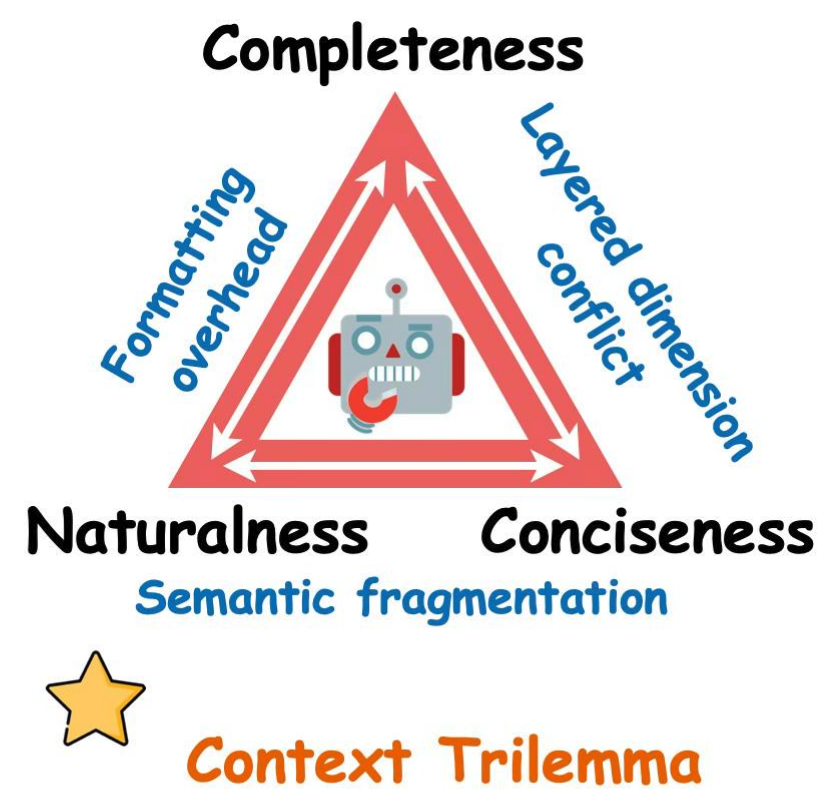
3. 为什么"上下文越长表现越差"——三重陷阱
这不是 GA 自己编的结论,是多篇论文验证过的现象。作者总结了三重相互强化的失效模式:
-
位置偏差( Lost-in-the-Middle ):LLM 对上下文开头和结尾的信息利用率高,中间部分容易被"遗忘"。关键信息落在中间位置时,模型可能直接忽略。
-
注意力稀释( Attention Dilution ):注意力是有限资源。无关内容越多,分配给每条关键信息的注意力越少。无关内容不是被浪费,而是主动干扰。
-
有效窗口远小于名义窗口:一个标称 128K 的模型,真正能稳定推理的有效窗口可能只有几万 token 。随着上下文增长,推理能力逐渐退化。
这三者形成恶性循环:上下文膨胀 → 注意力稀释 → 位置偏差加剧 → 有效窗口收缩 → 系统倾向于注入更多"可能有用"的内容来补偿 → 上下文进一步膨胀。
核心启示:超过某个临界点后,增加更多上下文不仅无法提升性能,反而会降低表现。
4. GA 的系统性解法:四层信息密度优化
GA 不是靠一个 trick 解决问题,而是在信息生命周期的四个阶段分别做优化:
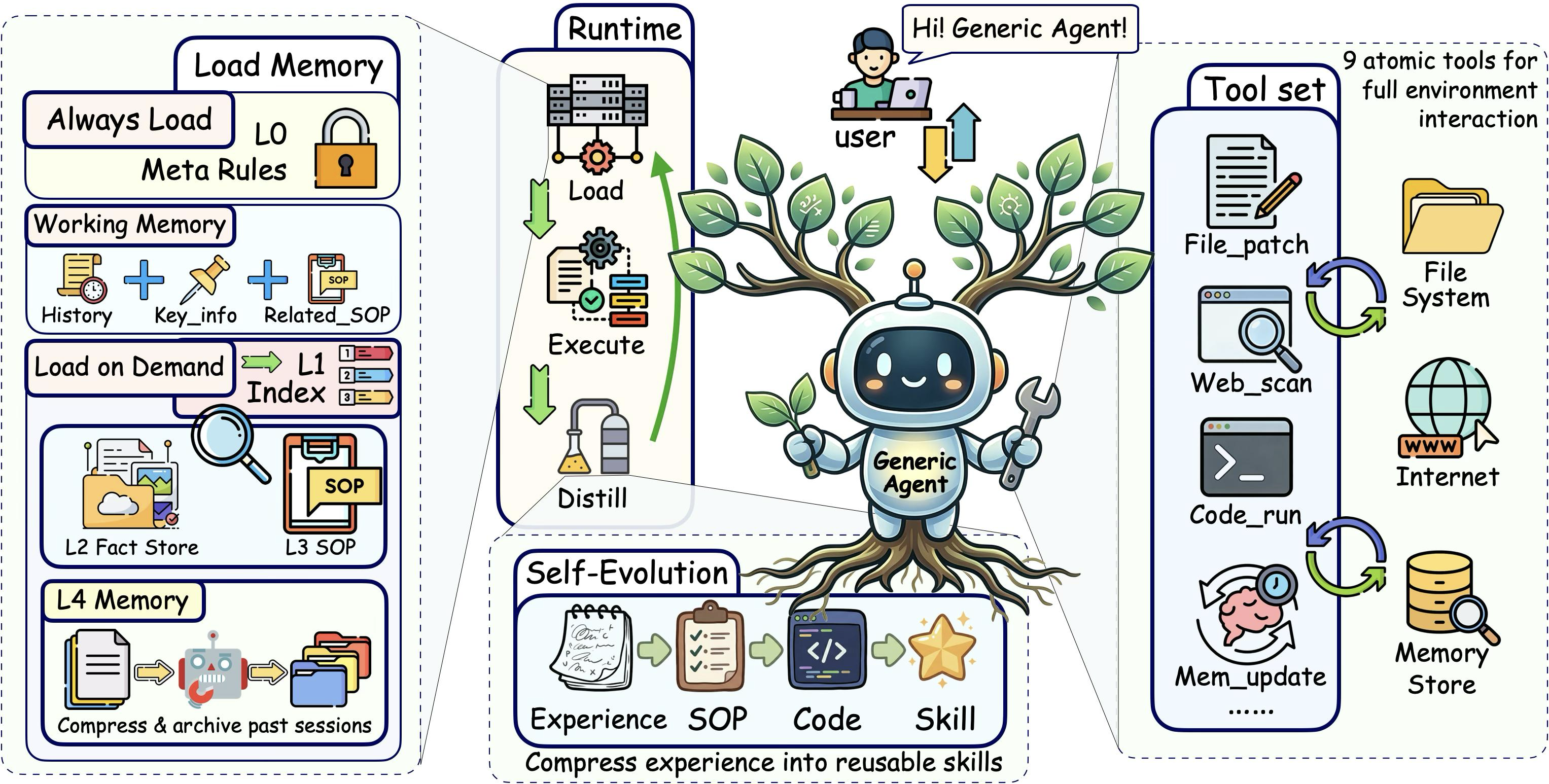
4.1 最小原子工具集——减少"先天噪声"
工具定义是上下文中每轮都要重复支付的固定成本。GA 的策略是极端克制:只保留 9 个原子工具。
为什么不是越多越好?作者指出工具膨胀有两层代价:
- Prompt 层:每增加一个工具,就要在上下文中注入 Schema (名称、描述、参数类型)。53 个工具的 Schema 可能消耗上万 token ,而且每轮重复。
- Policy 层:工具越多,动作空间越大,选择歧义越高。比如"读文件"这个操作,如果同时有 FileReadTool 、GrepTool 、BashTool(cat),模型需要理解三者的微妙差异才能正确选择。
GA 的 9 个工具覆盖五大能力类:文件操作( file_read / file_write / file_patch )、代码执行( code_run )、网页交互( web_scan / web_execute_js )、记忆管理( update_working_checkpoint / start_long_term_update )、人机协作( ask_user )。
关键设计:code_run 是万能逃生舱。任何 9 个工具覆盖不到的长尾需求,都可以通过写代码来实现。这意味着工具集不需要为每个边缘场景增加专用工具——保持了工具层的极简,同时不牺牲能力上限。
code_run 本质上是图灵完备的!
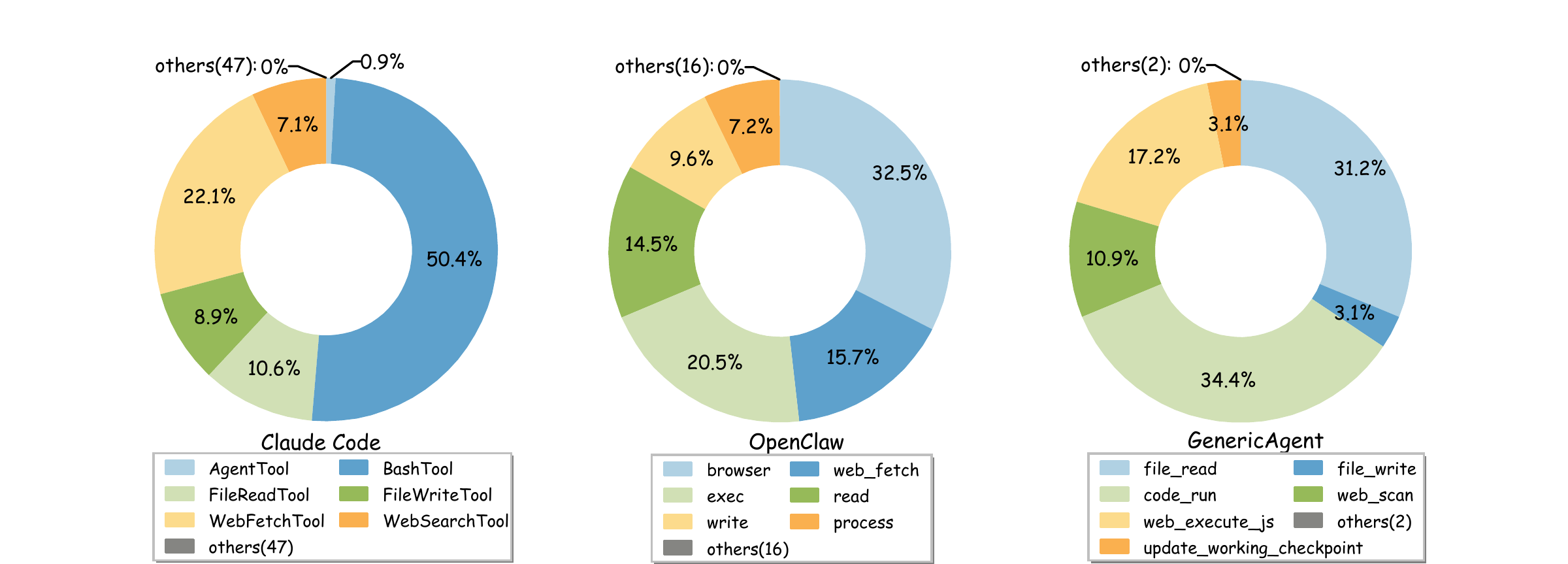
实际使用分布(论文数据):code_run 34.4%、file_read 31.2%、update_working_checkpoint 17.2%,三个工具覆盖了 82.8% 的调用。
4.2 分层按需记忆——只加载"当前需要的"
传统方案要么不保留历史(每次从零开始),要么全量追加(上下文爆炸)。GA 用了一个四层架构:
层级 定位 是否 always-on 典型大小 L1 索引层 目录卡片,告诉 Agent "有哪些知识可用" 是 ~200 token L2 事实层 环境事实、用户偏好、服务器信息 否,按需 file_read 数百~数千 token L3 SOP 层 标准操作流程、技能脚本 否,按需 file_read 每个 SOP 数百 token L4 原始日志 完整对话历史,用于追溯和审计 否,极少访问 无限增长核心机制:L1 始终在上下文中(成本极低),L2-L4 只在需要时才被加载。 这就像图书馆——你不会把所有书搬到桌上才开始工作,而是先查目录( L1 ),再去书架取需要的那本( L2/L3 )。
作者的消融实验验证了这个设计的有效性:
记忆配置 记忆大小( token ) 任务成功率 TSR No memory 0 52.44% Full memory (全量注入) 575 52.44% GA 分层记忆 165 66.48%165 token 的分层记忆达到了 575 token 全量注入的 1.27 倍成功率。 全量注入反而跟没有记忆一样——因为无关信息稀释了注意力。这是"上下文越长表现越差"的直接实证。
4.3 上下文截断与压缩——主动瘦身
即使工具和记忆都控制住了,对话轮次增加后上下文仍会膨胀。GA 用四阶段压缩流水线处理:
- 工具返回值截断:code_run 输出超长时只保留头尾
- 历史轮次压缩:早期对话轮次被摘要化
- 消息驱逐:超出预算的最旧消息被移除
- 工作记忆锚点注入:通过
update_working_checkpoint工具,Agent 主动把关键中间状态写入一个始终可见的锚点,防止被压缩丢失
第 4 点是个巧妙的设计——Agent 自己决定什么信息值得"钉住",而不是靠启发式规则猜测。
4.4 反思驱动的自我进化——让未来的上下文更精炼
GA 能把成功的任务经验蒸馏为 SOP 存入 L3 。下次遇到类似任务时,不需要在上下文中重新探索整个解决方案,直接调用之前积累的精炼经验。
这解决了"挑战二:经验停滞"。没有进化机制时,Agent 面临两难:要么重放更长的探索过程(削弱简洁性),要么从更短但信息不足的提示词开始(削弱完备性)。自我进化打破了这个两难——把冗长的探索轨迹压缩为紧凑的可复用知识。
5. 架构实现:92 行的 Agent Loop
GA 的主循环只有约 92 行,结构是标准的 perceive-think-act:
while not done:
context = assemble(system_prompt, always_on_memory, tools, history)
response = llm.chat(context)
if response.has_tool_calls:
results = execute(response.tool_calls)
history.append(results)
else:
done = True
整个系统由 4 个文件构成:agent_loop.py (主循环)、ga.py (工具实现)、agentmain.py (入口 + 前端适配)、llmcore.py ( LLM 调用封装)。总计约 3300 行。
这个极简架构的好处是:没有隐藏的复杂度。没有事件总线、没有调度守护进程、没有专用子 Agent 管理器。子 Agent 并行、定时任务、看门狗监控这些"高级功能",全部通过 9 个基础工具的组合涌现出来。
6. 约束下的涌现:三个原语长出整个生态
这是 GA 设计中我觉得最有意思的部分。
传统框架做高级功能的方式是"功能内置":需要子 Agent ?加一个 SubAgent Manager 。需要定时任务?加一个 Scheduler Daemon 。需要事件驱动?加一个 Event Bus 。每个新功能都带来新的接口、新的配置、新的故障模式。系统复杂度线性增长。
GA 走了另一条路:不内置任何高级功能,只提供三个足够通用的原语,让高级行为从组合中涌现。
三个基础原语
原语 本质 一句话描述 自托管 CLI 入口点 Agent 就是一个命令行程序 任何能调用命令行的程序都能调用 GA——包括 GA 自己 文件协议 目录约定的跨进程通信 input.txt 送任务、output.txt 流结果、reply.txt 续对话、stop.txt 终止 反射模式 轮询 + 热重载 外部脚本定义触发条件,运行时周期性求值,脚本修改后自动重载无需重启涌现出的高级行为
子 Agent 并行分发:父 Agent 通过 code_run 启动自己的另一个实例,传入不同的 task-dir 。父子是同构进程——不存在特权的子 Agent 运行时对象,双方遵循完全相同的文件协议。上下文天然隔离(独立进程 = 独立内存空间),不需要复杂的状态管理来区分"哪些历史属于哪个子任务"。
看门狗监控:反射模式 + 一个检测环境变化的触发脚本。当脚本返回非空字符串时,该字符串被作为任务分发到标准流水线。不需要专门的监控框架。
定时任务调度:反射模式 + 一个检查时间条件的触发脚本。跟看门狗共享完全相同的底层机制,区别仅在于脚本内容。
自主空闲行为:反射模式 + 一个"当前无任务"的触发条件。Agent 在空闲时自动执行预设的探索或维护任务。
为什么这能工作
这里的"涌现"不是物理学意义上的不可预测——而是工程意义上的:当基础组件足够通用且组合成本足够低时,设计者未预先规划的功能可以在需要时被轻松实现。
关键不在于"意外",而在于"低成本"。传统框架每加一个高级功能需要修改核心代码、添加新模块、更新文档。GA 只需要写一个触发脚本或一段 code_run 调用——核心代码一行不改。
作者给出的数据:GA 核心代码 3300 行( Agent Loop 仅 92 行),而实现了子 Agent 并行、看门狗、定时调度、自主行为等全部高级功能。作为对比,OpenClaw 的代码量约 530,000 行——160 倍以上。这不是说代码少就一定好,但它说明了一件事:当原语选对了,复杂行为不需要复杂实现。
7. Benchmark 数据
作者在 WebArena 、OSWorld 等标准 benchmark 上做了评测(数据来源:论文 Table 5 ):
指标 GA 总 Token 消耗 188,829 任务成功率( TSR ) 66.48%Token 消耗对比(同一组任务):
系统 Token 消耗 相对 GA GA 188,829 1x Claude Code 538,207 2.85x OpenClaw 633,498 3.35x完整提示词长度对比(安装 20 个技能后,对 "Hello" 的响应):
系统 Full Prompt Length ( token ) OpenClaw 43,321 CodeX 23,932 Claude Code 22,821 GA 2,2988. 从 Prompt Engineering 到 Context Engineering
作者提了一个我觉得很有价值的视角转变:
- Prompt Engineering 优化的是"一句话怎么说"
- Context Engineering 优化的是"每一轮对话中,模型看到的所有信息应该是什么"
在 Agent 场景下,上下文不只是用户指令,还包含工具定义、历史对话、记忆内容、工具返回值等多种组件。如何系统性地管理这些组件的注入、压缩和替换,才是决定 Agent 长期表现的关键。
GA 通过工具层、记忆层、压缩层和进化层四个维度,把 Context Engineering 落实为具体的系统机制。这不是一个 prompt 写得好不好的问题,而是一个系统架构问题。
9. 我的使用体感和局限
用了一段时间后的观察:
- 上下文 30K 的硬限制是双刃剑。 好处是 Agent 不会因为对话太长而变蠢;代价是单轮无法处理超大文件,需要分段读取。
- 记忆系统完全基于文件,没有向量检索。 SOP 数量特别多时,L1 索引的命中率可能下降。但对于个人使用场景(几十个 SOP ),目前没遇到问题。
- code_run 是万能的,也是危险的。 能执行任意代码意味着安全性完全依赖部署环境的隔离。
- SOP 质量很重要。 写得好的 SOP 能让 Agent 一步到位;写得不好的会误导。这是一个需要用户投入的地方。
- 多 Agent 协作通过进程 + 文件实现,没有结构化通信协议。 简单场景够用,复杂协作场景调试不太方便。
10. 总结
GA 的核心贡献不是某个具体的 trick ,而是一套完整的设计哲学:在完备性与简洁性的结构性张力下,通过四层机制系统性地最大化上下文信息密度。
它证明了一件事:Agent 的能力上限不取决于上下文能塞多少字,而取决于在有限 token 预算里,能装进多少真正对当前决策有用的信息。
如果你正在做 Agent 开发,不管用不用 GA ,它的设计思路都值得参考——特别是"信息密度"这个视角,对 prompt 设计、记忆系统设计、工具集设计都有直接的指导意义。
项目地址: https://github.com/juntao-ai/GenericAgent 论文: https://arxiv.org/pdf/2604.17091 教程: https://datawhalechina.github.io/hello-generic-agent/
写在最后
在上一个帖子发出后,受到了广泛的关注,深感荣幸,所以火速加更!



贴几条热心的 v 友对我善意的人身攻击,我深刻的认识到了我的不足,并意识到自己 too young too simple ,sometimes naive 。
我做出如下承诺: 1 、今后只写提示词,不写文章。 2 、在提示词中要求文章内容去学术化,去叽里咕噜化,去指标化。 3 、更广泛的听取大家的批评,了解 V2EX 的社区规范,学习落实 v 站大佬的悉心教导。保证做到:“余立侍左右,援疑质理,俯身倾耳以请;或遇其叱咄,色愈恭,礼愈至,不敢出一言以复;俟其欣悦,则又请焉。故余虽愚,卒获有所闻。”
另外再回复一下这条:
 本人再次重申,本人为某 top3 高校在读博士,大模型方向,于 3 月中旬刚刚恢复单身,欢迎感兴趣的异性 v 友留下联系方式,谢谢!
本人再次重申,本人为某 top3 高校在读博士,大模型方向,于 3 月中旬刚刚恢复单身,欢迎感兴趣的异性 v 友留下联系方式,谢谢!
最后附上上面这篇文章的提示词:
欢迎大家用 ga 写点公众号文章或者软文吹 claude code 和 codex ,给自己挣点外快!