首页
/
科技 / 究极花瓶:配上新的草稿模型,gemma-4-31B 可达 1…
究极花瓶:配上新的草稿模型,gemma-4-31B 可达 123 tokens/s,但上下文……
编辑部
2026-05-09T21:15:18.303214
18575 阅读 tech
使用了谷歌最新发布的草稿模型gemma-4-31B-it-assistant,加上gemma-4-31B-it-4bit-W4A16-AWQ部署在vllm上 draft tokens开到5,代码场景123tokens/s 知识问答类67tokens/s(可能文字类调低一些预测量会更好) 只恨我的40...
 究极花瓶:配上新的草稿模型,gemma-4-31B 可达 123 tokens/s,但上下文……
究极花瓶:配上新的草稿模型,gemma-4-31B 可达 123 tokens/s,但上下文……
使用了谷歌最新发布的草稿模型gemma-4-31B-it-assistant,加上gemma-4-31B-it-4bit-W4A16-AWQ部署在vllm上
draft tokens开到5,代码场景123tokens/s

知识问答类67tokens/s(可能文字类调低一些预测量会更好)

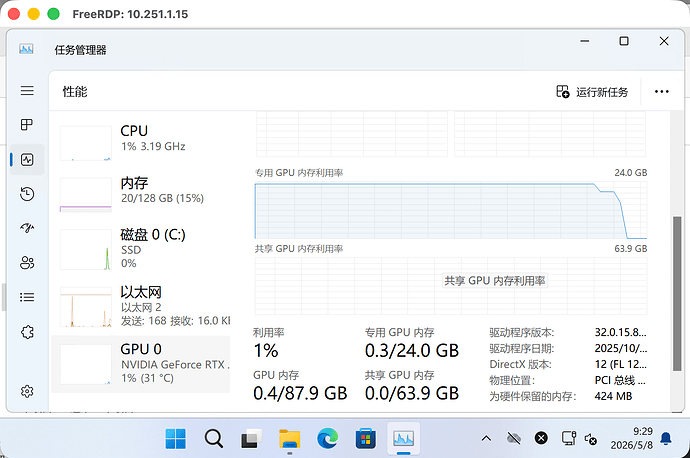
只恨我的4090显存不够啊~上下文只能开到2816,没错就是2k
如果有5090就可以爽玩了
1 个帖子 - 1 位参与者
阅读完整话题