相信不少佬都遇到过如下图所示问题:

Selected model is at capacity. Please try a different model.
我在站内检索了一下,发现这个问题似乎从 5 月 6 日起开始较大范围出现。一般情况下,手动发一句“继续”之后,模型又能继续正常工作。
所以想发帖和各位佬友们讨论一下,有没有更好的解决方案,或者至少能降低被频繁打断的影响。
目前观察下来,这个错误对应的上游返回大概是:
upstream response failed
Our servers are currently overloaded
问题在于,客户端收到这个错误后通常不会自动重试,导致 vibe coding 过程中经常被中断。
我尝试在 sub2api 里配置错误透传规则,把这个错误改成 upstream failed。这样客户端就会触发自动重试机制,最多重试 5 次。实际体验下来,被频繁中断的情况确实明显减少了。
配置如下图:
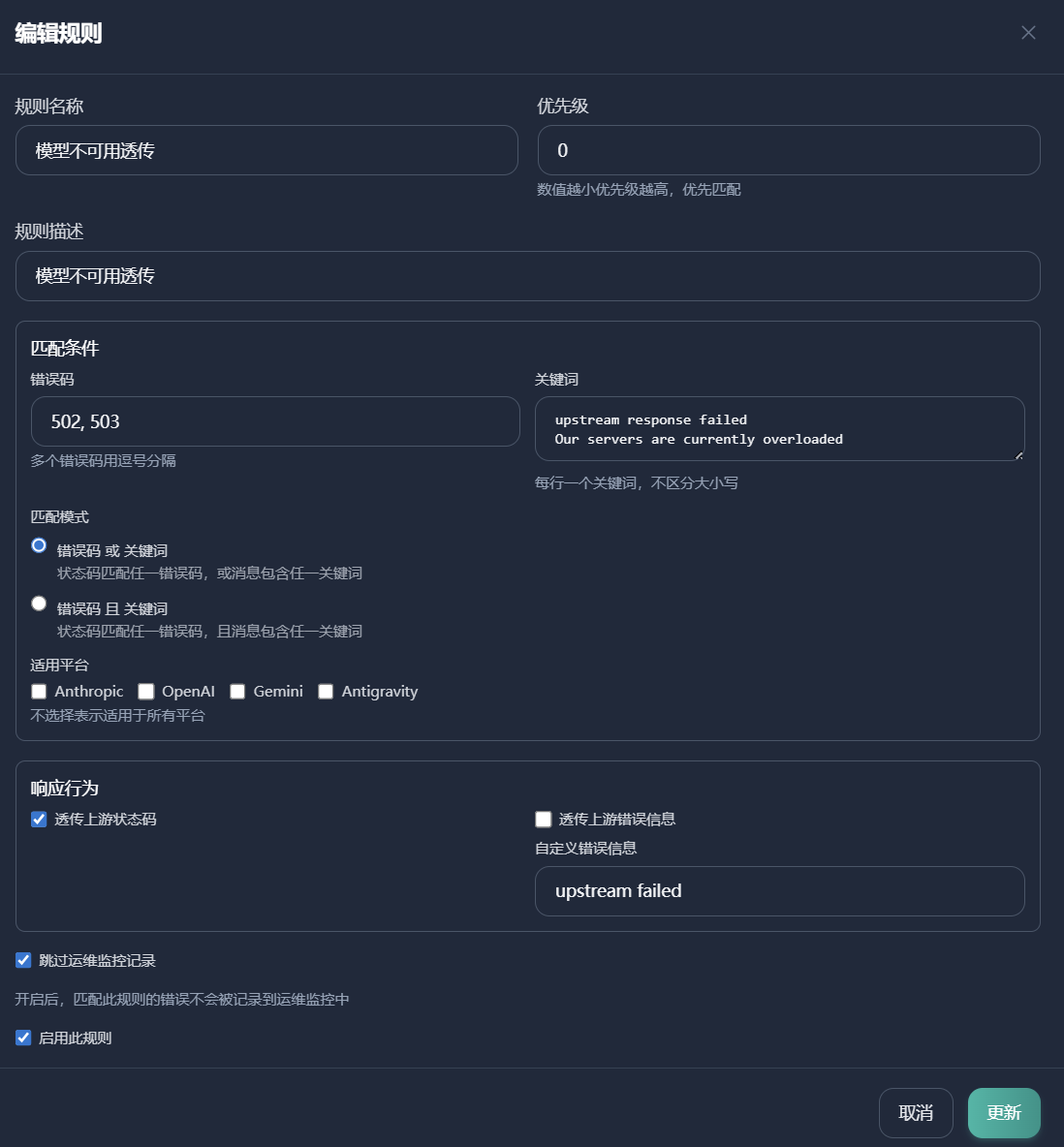
而 newapi 似乎只有状态码覆写,暂时不知道如何解决。
旧标题:GPT/Codex中“Selected model is at capacity”导致频繁中断的缓解方案讨论(以sub2api为例)
然后被同学锐评:“标题改成《三秒钟解决Selected model is at capacity.问题》,你这标题一眼就没有点进来的欲望。”
6 个帖子 - 6 位参与者
来源: LinuxDo 最新话题查看原文