
三句话概括我们做了什么
-
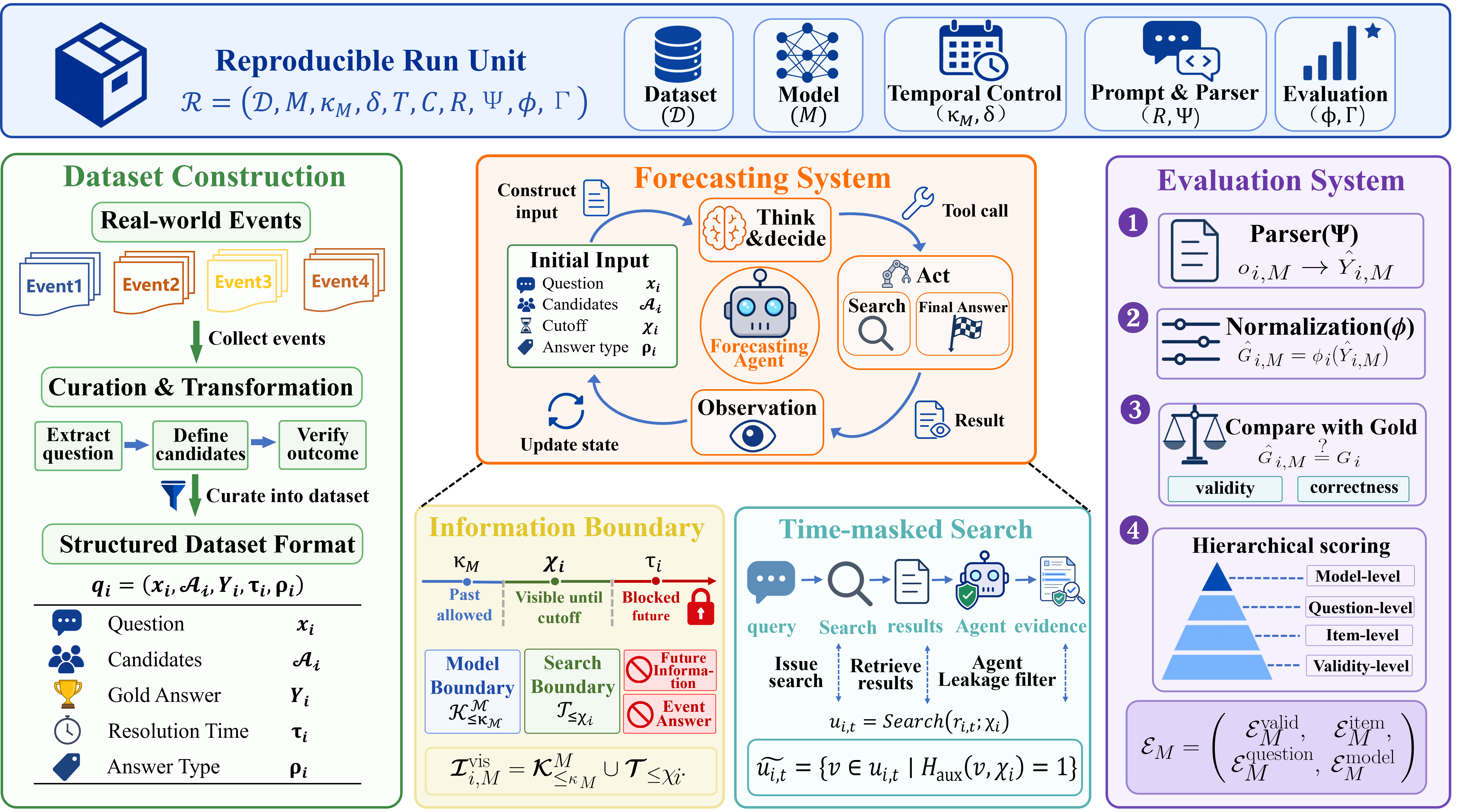
背景与挑战: LLM预测评估面临两难:实时测试易失效,回顾测试存在数据泄露。提示词无法建立真实的知识边界。
-
架构和方法: OracleProto 框架结合模型知识截止与时间遮蔽,将历史事件严谨重构为具有时间边界的可复现的预测样本。
-
实验的效果: 测试 9 个主流LLM 表明,OracleProto能有效区分了模型的预测质量、稳定性与成本效益,将泄露率降至 1\%,为模型对比、监督微调和强化学习提供了受控的信号源。
开源仓库及论文
详细介绍
Deepseek、GPT、Claude、Gemini 这些头部大模型拥有搜索、整合、推理和给出建议的能力,它们在各种 Benchmark 上反复打榜较量。
但如果你去问“下周英伟达财报能不能超预期”或者“某场冲突走向如何”,它们给出的回答却总是避重就轻、含糊其辞。
毕竟,预测从来就不是这些模型被专项训练过的技能。
可是,凭什么大模型就不能做预测?
预测本质上就是:
\text{信息搜集} \times \text{证据整合} \times \text{情势研判} \times \text{行动决策}这四个环节,拆开来看全都是 LLM 的原生能力。
明明拼在一起就是“预测”,怎么就突然变成没法训练、无法评估、也不能比较的黑盒了?
症结在于评测手段。而这一切的核心变量,是时间。 谁能把控模型获取信息的截止时间点,谁就能真正定义什么是“预测”。
“实时基准”直接拿未发生的事情出题,这就相当于纯实盘,数据绝对干净,但事件一落地题目就废了; “历史回放”拿已经发生的事去考 AI,但这些事早就躺在它的训练语料里了,这根本不叫样本外回测,叫看着答案抄试卷。
这正是我们要搞 OracleProto 的初衷。
一个基于知识截止与时间掩码的、用于评测 LLM 原生预测能力的可复现框架。
卡着模型的知识截止日期,给它出一道理论上绝对拿不到答案的考题。
考题事件发生在训练语料截止之后、现实的今天之前,把搜索工具的时间范围也硬性锁死,最后再上内容级防泄漏检测兜底。这样才能把模型按在一个干净的信息边界里,像跑严格的量化回测一样,逼它做真正的预测。
拿 80 道题跑了 9 个 LLM,发现准确率最多只差了 10.1 个百分点,但做出单次正确预测的调用成本居然差了 82 倍,花钱多不代表预测得准。
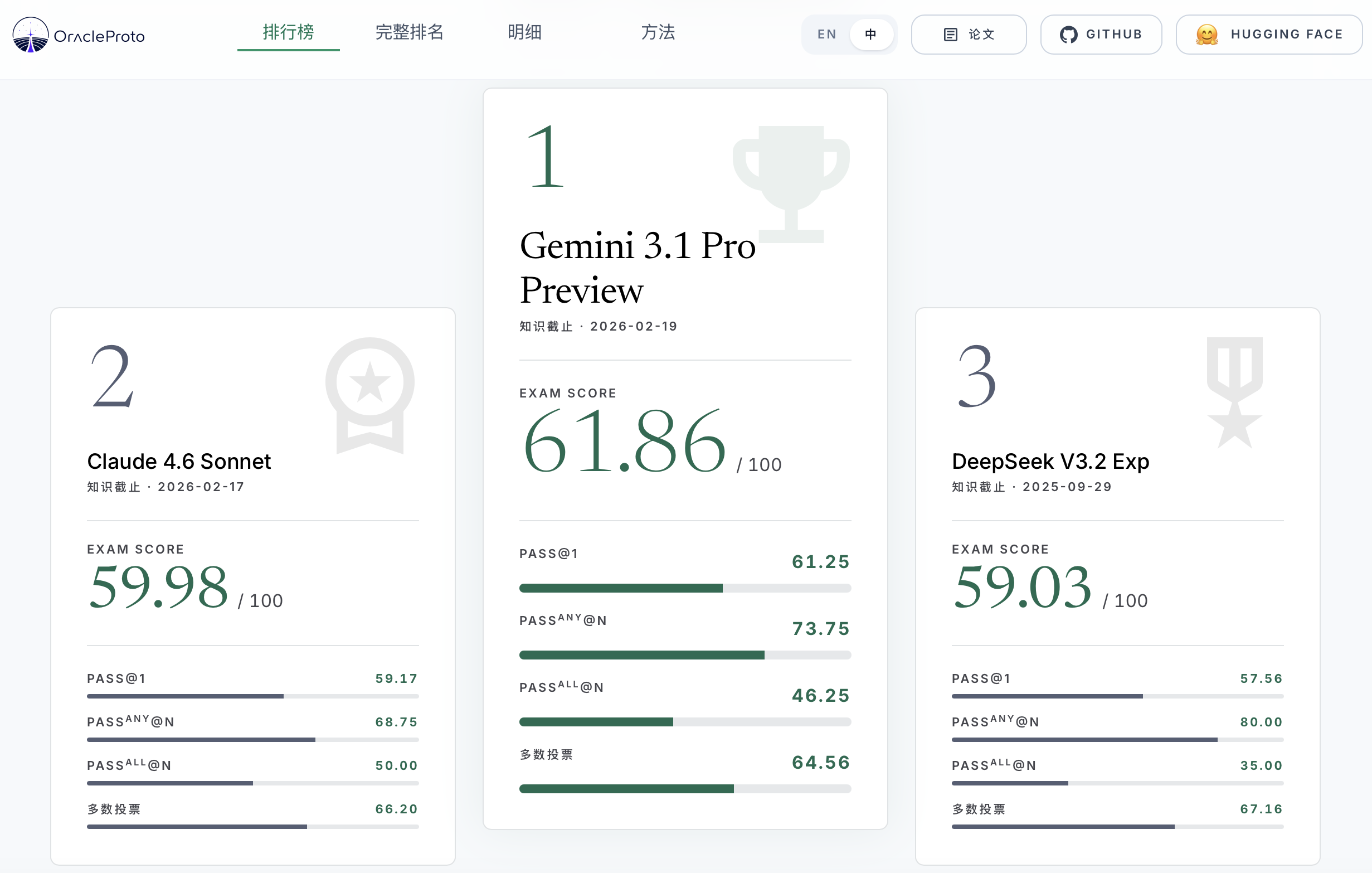
不过,这还不是最核心的价值。
在我们的框架里,全世界那些已经“过期”的预测数据集全都能变废为宝,转化为可以持续沉淀的、零污染的预测训练语料。
预测绝不应该仅仅是一种偶然的涌现现象,它理应成为一种可被训练、可被量化评估的大模型原生能力。
但坦白讲,我们目前挖得还很浅。评测只覆盖了 3 个海外模型 + 6 个国产模型,用的是现成的数据集,标注面也很窄。骨架虽然搭起来了,血肉还远远填不满。
因此,我们把代码、数据集和排行榜毫无保留地全部开源,希望有更多开发者能一起来完善它。
靠个人堆不出一个完整的预测基准,但开源社区的群智可以。
感谢各位的 Star,欢迎提 Issue 和 Discussion。
感谢学长的灵感及指导和实验室诸位的支持,联系方式请见 GitHub。
感谢 L 站,感谢各位大佬,新人展示,有任何不完美的地方,请赐教,不胜感激。
1 个帖子 - 1 位参与者