- 我的帖子已经打上 开源推广 标签: 是
- 我的开源项目完整开源,无未开源部分: 是
- 我的开源项目已链接认可 LINUX DO 社区: 是
- 我帖子内的项目介绍,AI生成、润色内容部分已截图发出: 是
- 以上选择我承诺是永久有效的,接受社区和佬友监督: 是
以下为项目介绍正文内容,AI生成、润色内容已使用截图方式发出
昨天在linux.do发布新开源项目:【开源】又一个好东西:基于多模态 Embedding + Zilliz + Qwen 视觉理解的多模态 RAG 系统
佬友有意见,我觉得加上展示效果,实战案例,可能更好的表达效果:
视觉理解和视觉回答 - 乐高积木AI拼搭
基于多模态 Embedding + Zilliz + Qwen 视觉理解的多模态 RAG 系统。支持 **Cohere / DashScope Embedding** 和 **DashScope / OpenRouter LLM** 双引擎切换。上传 PDF,用自然语言提问,系统自动检索最相关的页面并由 AI 生成回答。与传统 RAG 不同,本系统**不做文本提取和 OCR**,而是直接将 PDF 页面当作图片处理,通过视觉 Embedding 模型编码,完整保留表格、图表、排版、手写批注等所有视觉信息。
以下为测试和演示效果:
怎样搭建窗户

怎样搭建各种墙壁

怎样搭建一个桥

帮忙搭建一个法拉利跑车


怎样搭建一个屋顶

各种屋顶


怎样搭建一个飞机


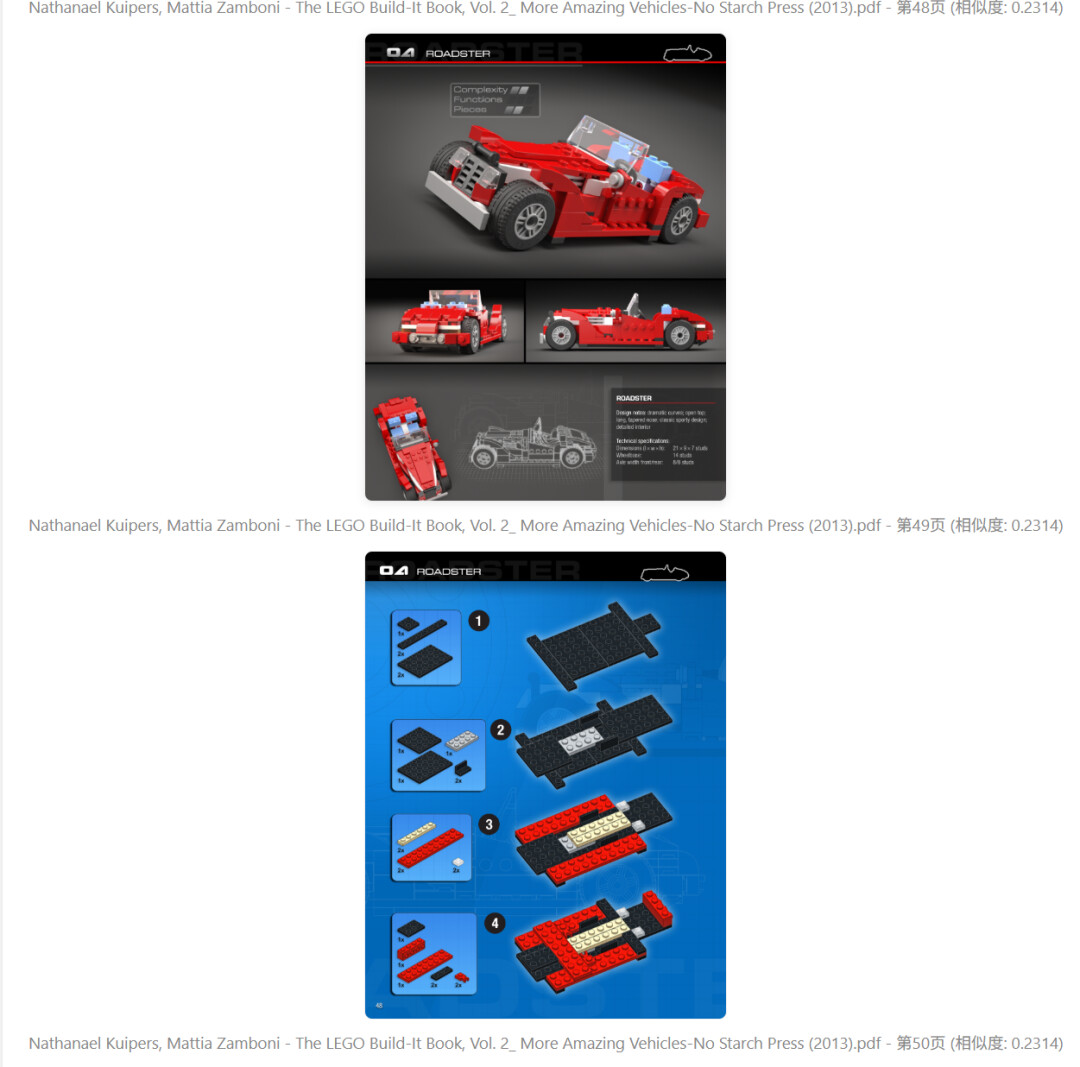
查找红色 的跑车

搭建直升飞机



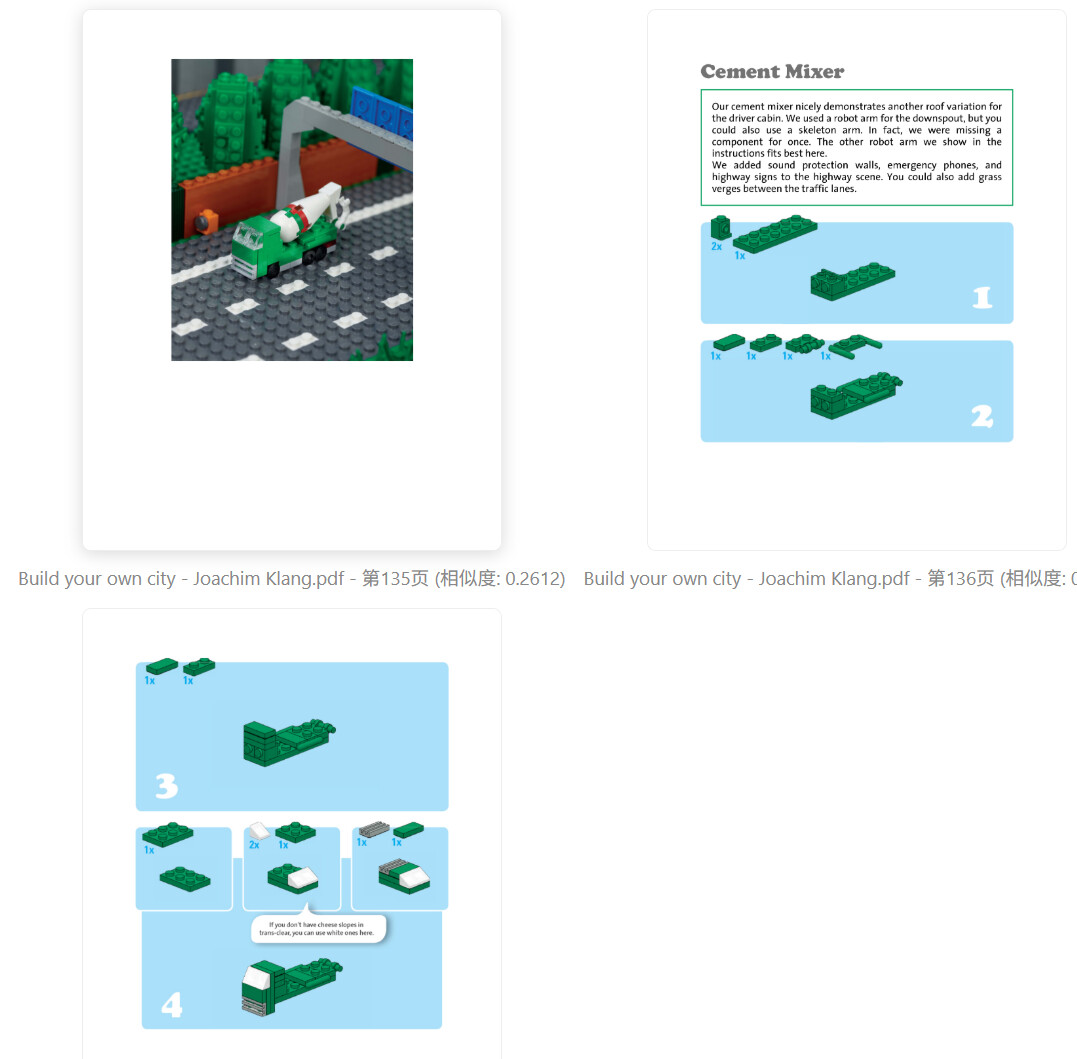
搭建 微型城市小车


搭建模块化街景

搭建街景路灯

搭建英国风格建筑

搭建古典主义建筑


搭建中国风格建筑

搭建动物

各种snot技巧:

感谢佬友支持!
1 个帖子 - 1 位参与者
来源: linux.do查看原文