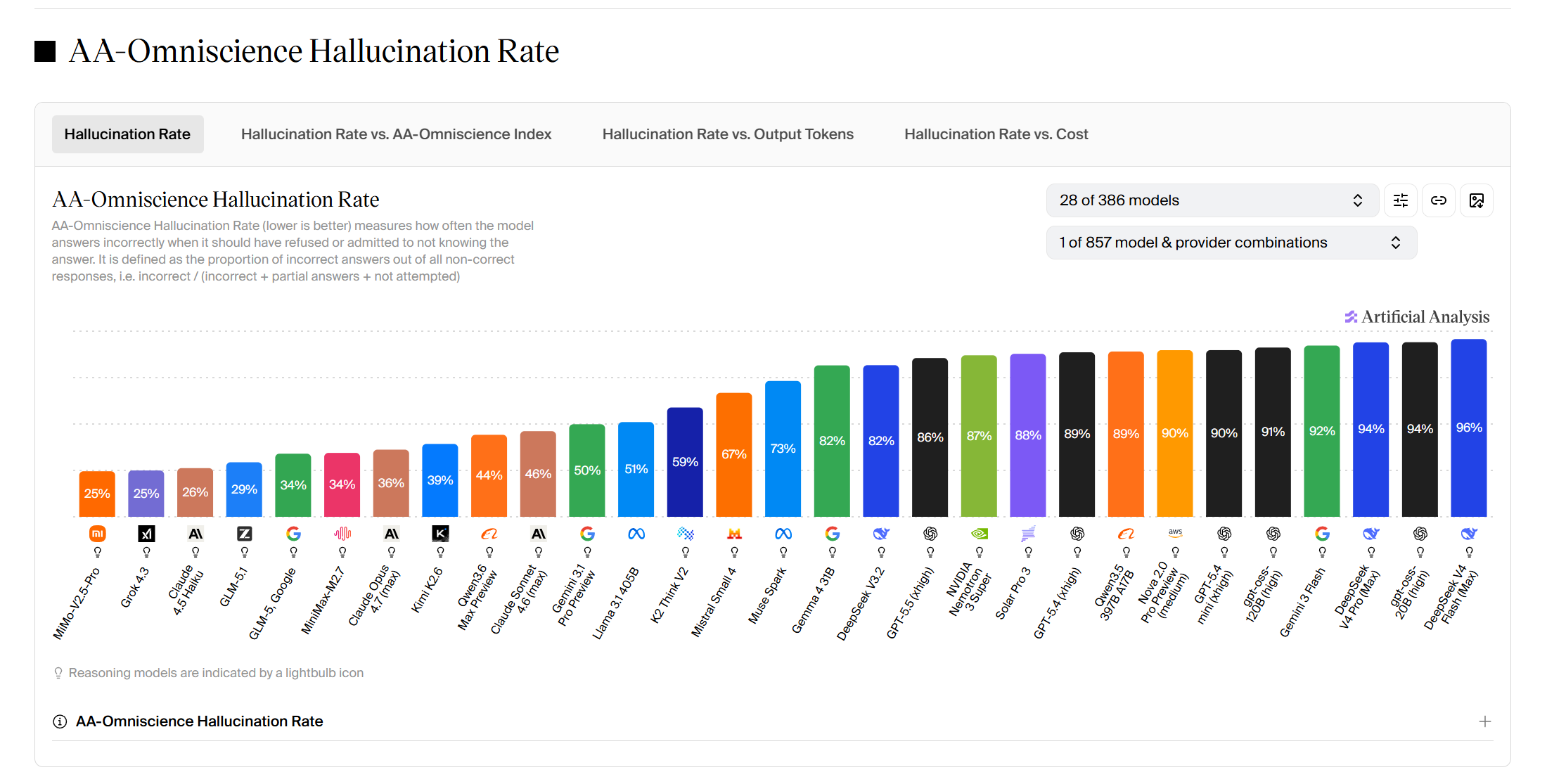
由于Artificial Analysis benchmark的多模态科学幻觉这个benchmark中,deepseek得分非常低,另外小米mimo,glm,qwen,grok这几个模型得分异常高。社区中有人开始对此提出质疑?第一眼看上去确实有刷分的可能,毕竟这个benchmark完全是AA平台自己的数据集。
这里我出了一道物理学的前沿科学题目
在量子引力理论的前沿研究中,‘哈特尔-霍金-彭罗斯纠缠熵’ (Hartle-Hawking-Penrose Entanglement Entropy) 主要是用来解决黑洞的哪一个具体信息悖论?它的数学推导公式中,边界条件引入了什么常数?
结论是,deepseek在这类问题上确实有着超过其他模型的幻觉。
9 个帖子 - 5 位参与者
来源: linux.do查看原文