本文分成两部分:
1. 用量证明和讲解
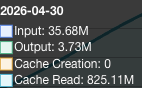
其实除了这部分还有大约200-300M没统计进来
用的是gpt-5.5,基本上如果换算成官方api价格基本上就是1M大约1刀多一点吧平均下来
主要就是基本上只要同时开5个codex窗口,然后让他一直不停的干活,大约持续12个小时,差不多就1000M了
虽然感觉没做出什么有用的东西出来 ![]()
2. 关于agent集群的思考
这个思考大概是在gpt-5.4得出的,就是假如说你进行一个比较大的重构,比如让codex plan了一下,然后让他去执行,完成之后还是有很多偷懒的地方的。
一个常见的方法就是让他完成的时候无论是通过hook还是通过skill/agent.md的方式让他开一个subagent自己审查,但会发现实际上审查并不能审查出所有的问题,甚至有的时候即便审查他说没问题实际上还是有很多问题。
那么出现这种现象的原因是什么呢?
我个人认为就是可能为了节省token(导致训练就是往这方面去训练的)所以从来不读全文,只进行搜索和邻近读取(我估计的,我没看过具体的,轻喷),所以导致看的不全面,看的不全面自然也就找不出所有的问题了。
另一方面导致这个问题的原因也是现在llm本身的问题,就说呢,由于注意力方面的问题,以及上下文的问题,以及上下文污染的问题,就算读了全文也没用,类似于,可能原本一件事情他可能能完成100%的努力,而现在变成了10件事,他总共花费的努力也才150%,结果分配到每一个上面就少了,差不多就是这么个比喻。
为了解决这个不读全文的问题,实际上很久以前在llm刚出来的时候就有过一个很火爆的项目,就是将你项目里的所有代码文件拼成一个文本,然后直接作为prompt交给llm,但结果证明效果不是很得劲。主要就是我刚刚提到的这个问题。
所以想法很简单,就是拆分任务嘛。
就直接要求他每一个subagent对于某1-3个文件必须读全文,但如果想要读其他的内容也随便,但主要就是针对于这几个文件来审查,然后让所有的subagent加起来覆盖所有的文件,效果上我感觉比前面说的单reviewer来审查全部的效果好上很多。只不过这样消耗量肯定是比正常的耗上很多的。
实际上大约一个月前我就看到有佬友开源过一个框架,就是类似是让1000个codex去干活,然后找出了chrome的很多漏洞好像,虽然目的和我这个有些不一样,但我觉得从一些大体的思考上是类似的。
我觉得吧,与其思考如何通过文档来减少上下文,如何通过harness来减少上下文,通过记忆来减少上下文,agent的重点就在于他可以很多个,可以去覆盖所有的内容,这对人类来说是很费时间的,但对ai来说就还好,并且效果上我觉得肯定比前面说的三种方式要好,当然,也可以在这个基础上用比如前三种或者其他的方式来更进一步提升速度提升效果,llm已经证明了scaling law,我们也要相信scaling law,除了可能对钱包可能不太友好,但这是我的问题 ![]()
11 个帖子 - 5 位参与者