导师搞了台DGX Spark,说要部署一个大模型进去,关于DGX的中文部署教程目前并不算多,和各位佬友分享一下这次部署过程完整,顺手写一篇教程。
这里计划部署的模型是AEON-7/Qwen3.6-27B-AEON-Ultimate-Uncensored-NVFP4 · Hugging Face
一、安装Conda环境
执行命令,下载ARM64 版本的 Miniforge
cd ~
wget -O Miniforge3-Linux-aarch64.sh \
https://mirrors.tuna.tsinghua.edu.cn/github-release/conda-forge/miniforge/LatestRelease/Miniforge3-Linux-aarch64.sh
为了避免国内网络问题这里使用了清华源
下载结束后安装:
bash Miniforge3-Linux-aarch64.sh
安装过程中出现许可协议,一直yes就行
安装完成后,让配置立即生效:
source ~/.bashrc
最后检查 Conda 是否安装成功:
conda --version
![]()
二、安装模型
1.准备conda环境
执行命令创建名为 ‘hf’ 的conda环境
conda create -n hf python=3.13 -y
conda activate hf
前面的括号是hf代表当前在hf这个环境当中
2.下载hfd.sh
由于国内网络问题,直接下载会很慢,这里使用hf-mirror提供的工具下载(如遇无法访问hf-mirror,挂个代理上去https://github.com/nelvko/clash-for-linux-install)
wget https://hf-mirror.com/hfd/hfd.sh
chmod +x hfd.sh
发现访问不了,走代理
source ~/clashctl/scripts/cmd/clashctl.sh
clashon
export http_proxy=http://127.0.0.1:7890
export https_proxy=http://127.0.0.1:7890
wget https://hf-mirror.com/hfd/hfd.sh
chmod +x hfd.sh

3.安装aria2
sudo apt-get install aria2
4.安装Hugging Face 相关依赖
pip install -U "huggingface_hub[cli]" hf_transfer
建议开启高速下载:
export HF_HUB_ENABLE_HF_TRANSFER=1
输入下载命令下载模型(具体细节需要根据你的用户名称等进行修改)
cd /home/cavin-dgx/models
mkdir -p AEON-7
cd AEON-7
export HF_ENDPOINT=https://hf-mirror.com
export HF_HUB_ENABLE_HF_TRANSFER=1
/home/cavin-dgx/hfd.sh AEON-7/Qwen3.6-27B-AEON-Ultimate-Uncensored-NVFP4 \
--tool aria2c \
-x 4
如遇权限问题请修改权限:
sudo chown -R cavin-dgx:cavin-dgx /home/cavin-dgx/models
开始下载:
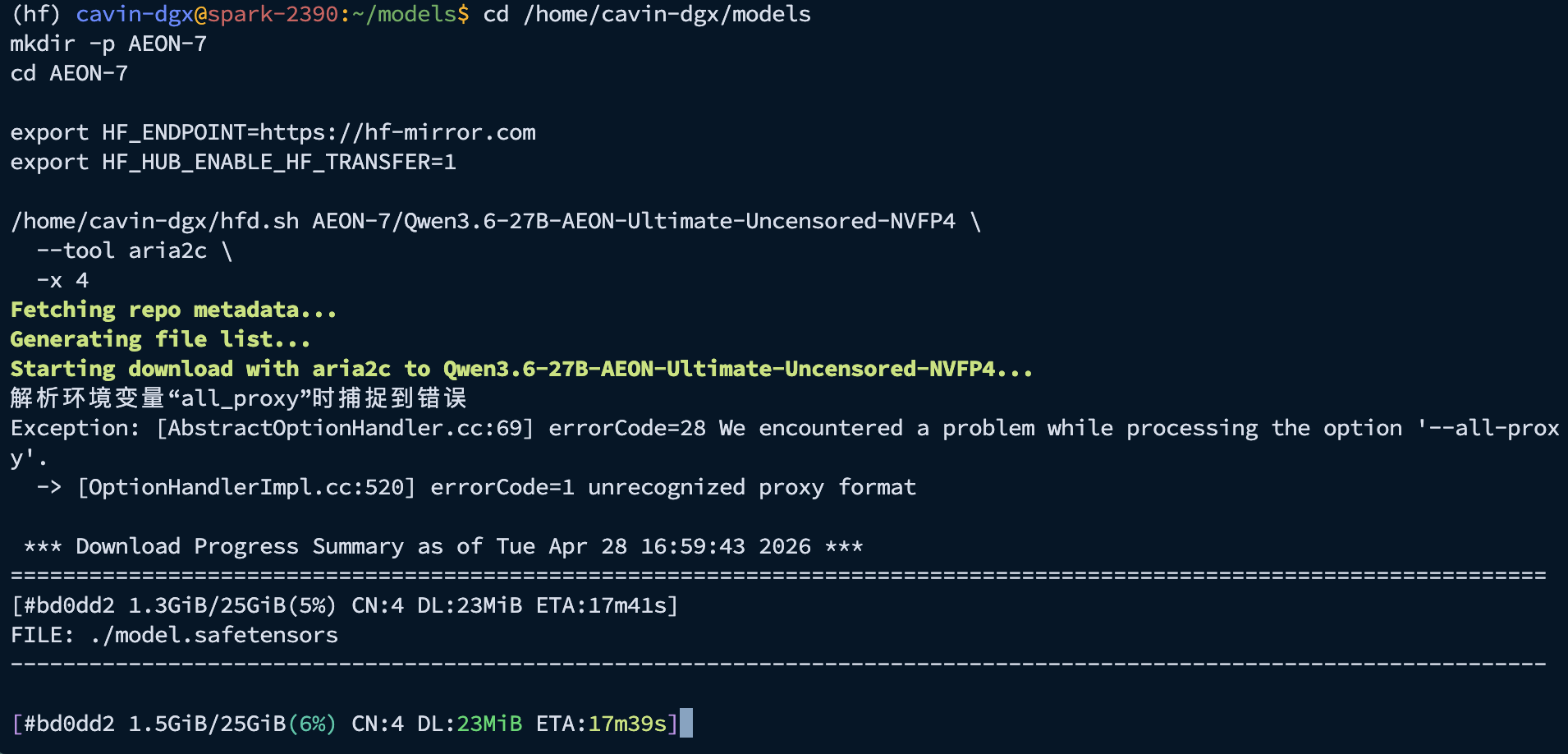

三、使用vllm运行模型
1. 拉取 AEON vLLM 镜像
sudo docker pull ghcr.io/aeon-7/vllm-aeon-ultimate-dflash:qwen36-v3
执行后发现这个镜像拉去太慢了,在1panel配置下加速https://github.com/1Panel-dev/1Panel:
{
"registry-mirrors": [
"https://docker.1panel.live",
"https://docker.1panel.dev",
"https://docker.1ms.run",
"https://docker.registry.cyou",
"https://docker-cf.registry.cyou",
"https://dockercf.jsdelivr.fyi",
"https://docker.jsdelivr.fyi",
"https://dockertest.jsdelivr.fyi",
"https://mirror.aliyuncs.com",
"https://dockerproxy.com",
"https://mirror.baidubce.com",
"https://docker.m.daocloud.io",
"https://docker.nju.edu.cn",
"https://docker.mirrors.sjtug.sjtu.edu.cn",
"https://docker.mirrors.ustc.edu.cn",
"https://mirror.iscas.ac.cn",
"https://docker.rainbond.cc",
"https://do.nark.eu.org",
"https://dc.j8.work",
"https://gst6rzl9.mirror.aliyuncs.com",
"https://registry.docker-cn.com",
"http://hub-mirror.c.163.com",
"http://mirrors.ustc.edu.cn/",
"https://mirrors.tuna.tsinghua.edu.cn/",
"http://mirrors.sohu.com/"
],
"insecure-registries": [
"registry.docker-cn.com",
"docker.mirrors.ustc.edu.cn"
],
"debug": true,
"experimental": false
}
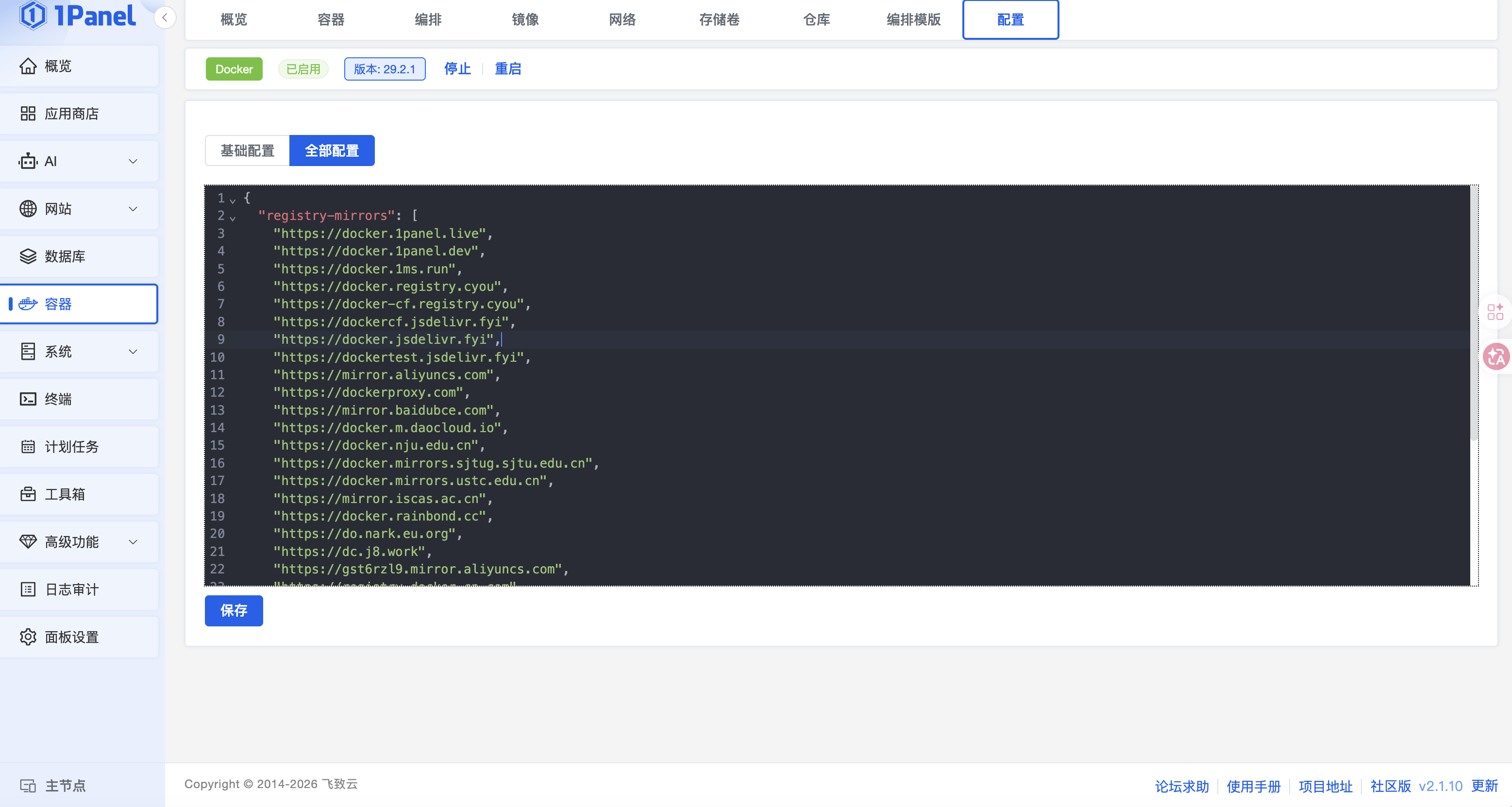
试试,发现还是很慢,问题不在docker上,在云上,换个镜像站的地址看看
sudo docker pull ghcr.milu.moe/aeon-7/vllm-aeon-ultimate-dflash:qwen36-v3
发现这个速度还是很抽象,挂后台让他慢慢下吧
下了一晚上终于下好啦
2.运行vllm
输入命令测试下:
sudo docker run --rm --gpus all \
--ipc=host \
--network=host \
-e TORCH_CUDA_ARCH_LIST="12.0+PTX" \
-e PYTORCH_CUDA_ALLOC_CONF=expandable_segments:True \
-e VLLM_USE_FLASHINFER_MOE_FP4=0 \
-v /home/cavin-dgx/models/AEON-7/Qwen3.6-27B-AEON-Ultimate-Uncensored-NVFP4:/models/aeon-ultimate \
ghcr.io/aeon-7/vllm-aeon-ultimate-dflash:qwen36-v3 \
vllm serve /models/aeon-ultimate \
--served-model-name aeon-ultimate \
--host 0.0.0.0 \
--port 8000 \
--tensor-parallel-size 1 \
--dtype auto \
--quantization compressed-tensors \
--max-model-len 65536 \
--max-num-seqs 16 \
--max-num-batched-tokens 32768 \
--gpu-memory-utilization 0.85 \
--enable-chunked-prefill \
--no-enable-prefix-caching \
--load-format safetensors \
--trust-remote-code \
--enable-auto-tool-choice \
--tool-call-parser qwen3_coder \
--reasoning-parser qwen3 \
--attention-backend flash_attn

接下来就是加载时间
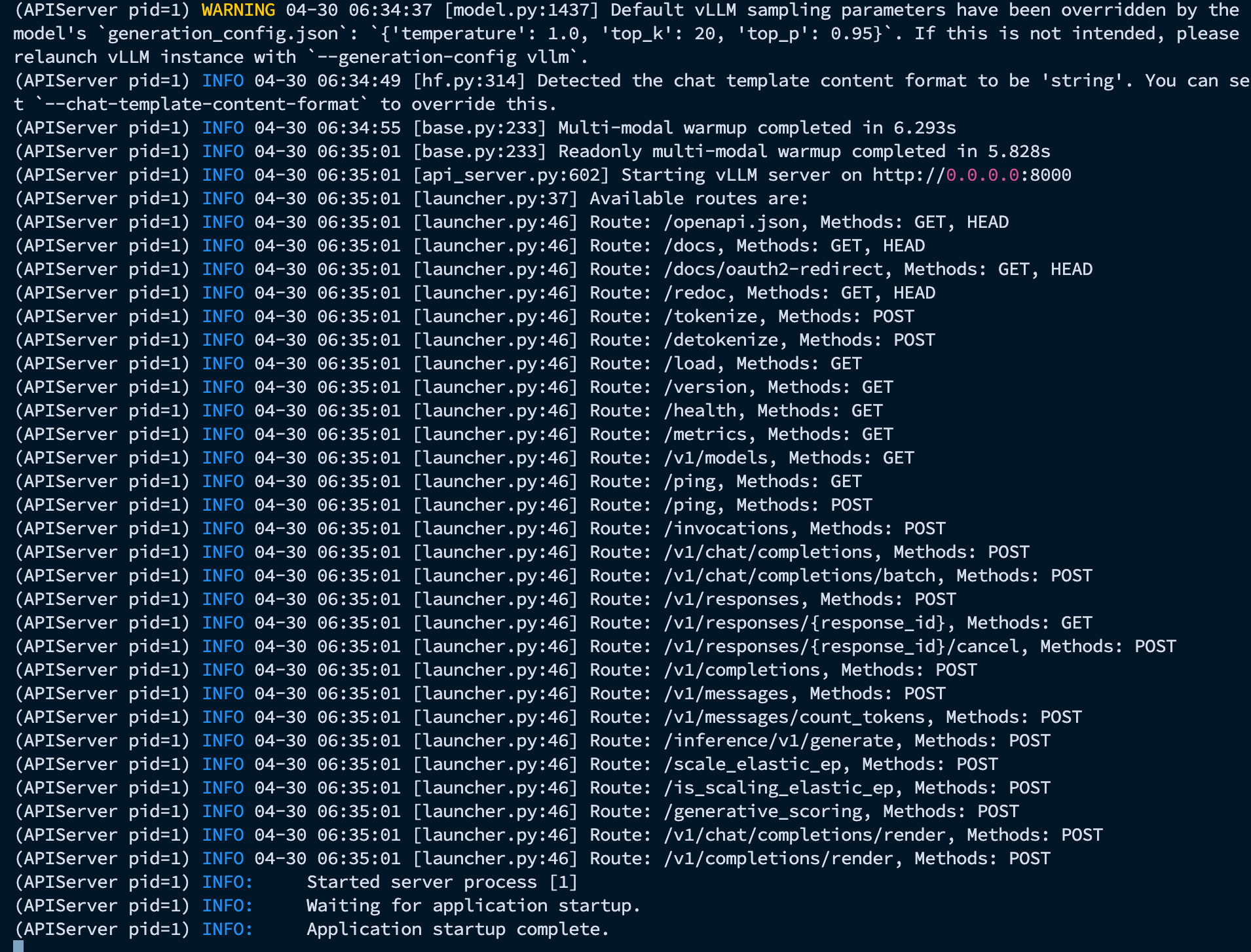
启动成功!测一下通不通


3.导入到new api
我的new api也部署到这个机子上了,需要docker内部的网络统一一下,这里使用1panel-network和8000端口,根据实际情况可以自己修改,这里使用nohup挂到后台
nohup sudo docker run --rm --name nervous_kirch --gpus all --ipc=host --network 1panel-network -p 8000:8000 -e TORCH_CUDA_ARCH_LIST="12.0+PTX" -e PYTORCH_CUDA_ALLOC_CONF=expandable_segments:True -e VLLM_USE_FLASHINFER_MOE_FP4=0 -v /home/cavin-dgx/models/AEON-7/Qwen3.6-27B-AEON-Ultimate-Uncensored-NVFP4:/models/aeon-ultimate ghcr.io/aeon-7/vllm-aeon-ultimate-dflash:qwen36-v3 vllm serve /models/aeon-ultimate --served-model-name aeon-ultimate --host 0.0.0.0 --port 8000 --tensor-parallel-size 1 --dtype auto --quantization compressed-tensors --max-model-len 65536 --max-num-seqs 16 --max-num-batched-tokens 32768 --gpu-memory-utilization 0.85 --enable-chunked-prefill --no-enable-prefix-caching --load-format safetensors --trust-remote-code --enable-auto-tool-choice --tool-call-parser qwen3_coder --reasoning-parser qwen3 --attention-backend flash_attn > /home/cavin-dgx/aeon_vllm.log 2>&1 &

注意这里填网关地址,不要填成设备地址,new api部署到vps不需要考虑这个
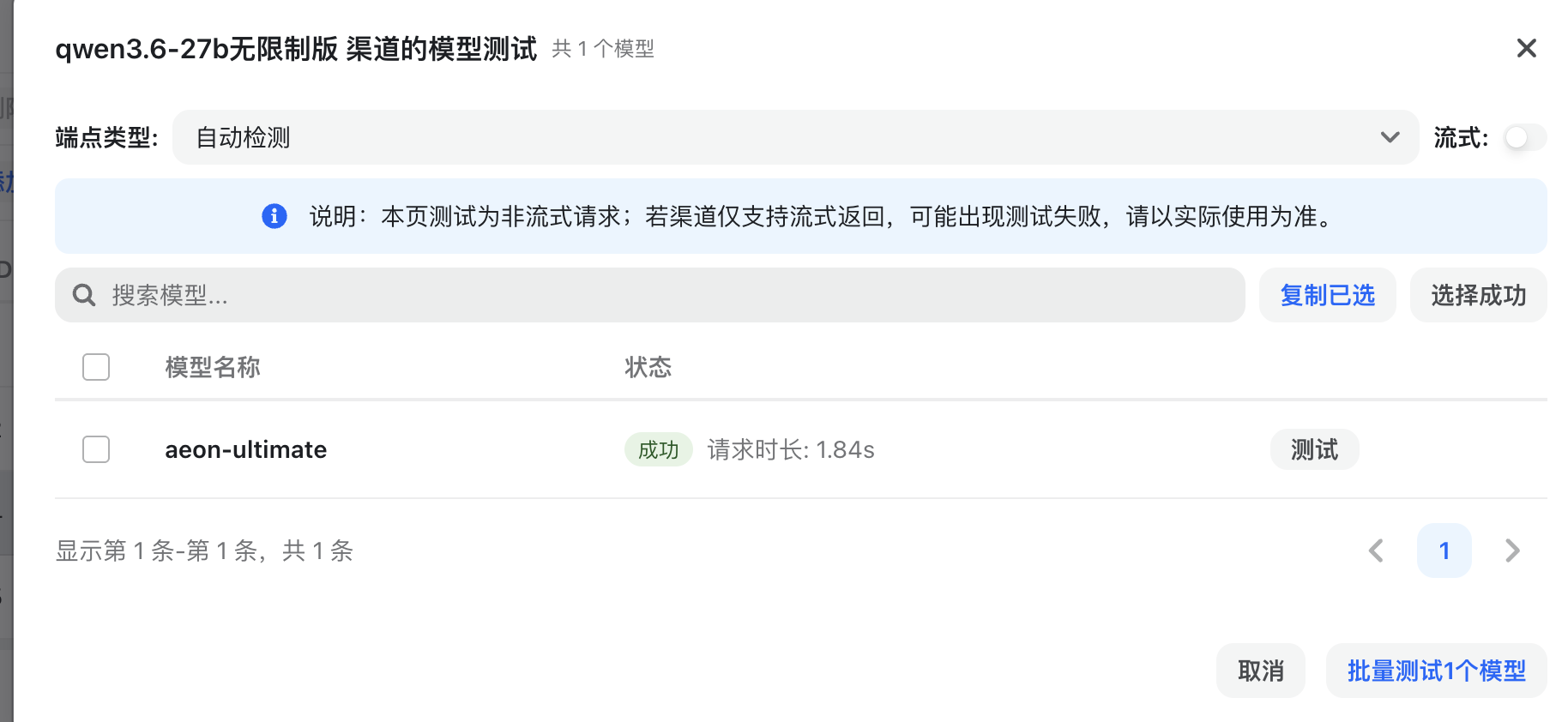
测试通过,搞定!
四、远程调用
直接丢到CC开蹬!
整体部署容易踩雷的地方主要还是模型和下载镜像的网络问题,还有docker网关的问题。
5 个帖子 - 3 位参与者
来源: linux.do查看原文