从 【Agent笔记】我们一起来学习Agent!(第1期) 继续讨论;我第一期的时候就是想记录一下,因为我在开发agent项目。没想到佬们那么欢迎,我真的诚惶诚恐。
然后这个月实在太忙了:上半月一直在做自己的项目,希望拿到一些投资。前两天刚郴州旅游回来,然后手上两个团队项目在做,而gpt plus眼看着过期了,我就想是时候提高自己的提示词技术和相关知识了————所以也很忙。
今天本来打算写多点的,但是我想还是留到下一期————**我保证这会很快的!就这个星期!**因为今晚有小姐姐叫我打游戏了,休息一波 ![]()
佬我准备买个coding plan了,50左右推荐一个呗,就那种玩具的,我经常需要写一个玩具项目,要求有GLM5左右的水平就可以,主要是周量够,业余开发。没有的话我打算买kimi那个80的了,老板还给我配了gpt plus就不用在自己项目了。
正文开始:
我们一起学Agent!(第二期)
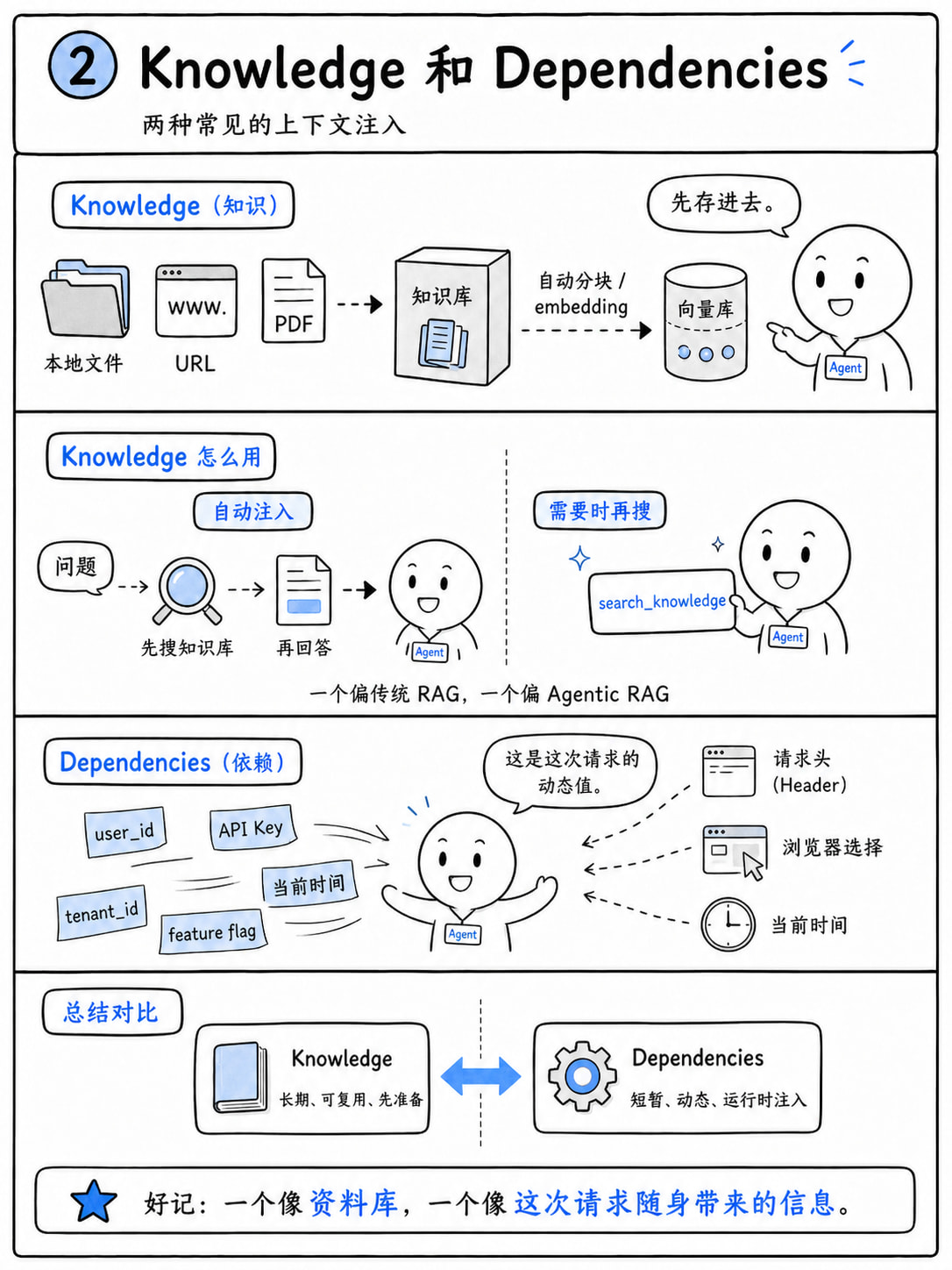
Context(上下文)
定义:Agent在每次执行任务时能够获得的外部信息。一个agent的质量很大程度上取决于它能访问到的上下文——即使系统提示写得再完美,缺少正确的上下文(背景,语境,解决问题需要的信息)也会导致结果不佳。

在agno中,提供了三种原生方式进行context的提供
Knowledge(知识库)
我们需要预先做两个事情,第一建立对象绑定数据库,第二建好知识库
-
创建一个
Knowledge对象,绑定一个向量数据库(如 PgVector)。 -
将内容从本地文件、URL 等添加到知识库中(自动分块、生成 embedding)。
调用方式如下:
from agno.agent import Agent
from agno.knowledge import Knowledge
from agno.vector_db.pgvector import PgVector
agent = Agent(
model=...,
knowledge=Knowledge(
vector_db=PgVector(table_name="my_kb", db_url="postgresql://...")
),
search_knowledge=True, # 提供工具
add_knowledge_to_context=True, # 自动注入
)
agent.knowledge.add_content_from_path("docs/")
可以看到,Agent 通过两种方式使用知识库:
-
add_knowledge_to_context=True:每次运行前自动搜索相关知识,并注入到提示词中(传统 RAG)。 -
search_knowledge=True:为 Agent 提供一个search_knowledge_base(query)工具,由 Agent 自主决定何时搜索(Agentic RAG)。
后者是目前我认为比较好的方向,前者是几年前流行的;因为模型的agent能力已经大幅上升,query的多,query的好。
Dependencies(依赖项)
看到这个词我双眼一黑,不过其实也还好;
定义:短暂、请求级别的动态值,不适合放在知识库中:如特性开关、租户 ID、每个请求的数据库连接、调用方专属的 API Key 等。
简单的说,就是“程序运行时动态捕捉的数据,主动注入给 Agent”。
你在写代码时,可以“捕捉”到很多东西:
-
Web 框架中,从请求头捕捉
user_id -
浏览器插件中,捕捉当前选中的文字
window.getSelection() -
调试工具中,捕捉你设置的
--debug命令行参数 -
定时任务中,捕捉当前时间
datetime.now()
比如说你写了一个浏览器插件agent,其中有程序可以捕捉用户在浏览器中的历史选中,程序发现用户在浏览中选中了`英伟达` `微软`这些词汇,那么当用户和你的agent对话时候,它们就会被注入;agent就会意识到用户似乎对这两个公司感兴趣;
同样的,那些用户的ip地址,ID,APIKEY,也是程序捕捉,注入到agent之中。
实现方式
-
在创建 Agent 时传入一个
dependencies字典,可包含任意结构的数据。 -
设置
add_dependencies_to_context=True后,这些依赖会被自动注入到系统提示词中。 -
工具函数如果需要访问依赖,可以声明一个
RunContext参数,通过run_context.dependencies读取。
代码如下:
from agno.agent import Agent
from agno.run import RunContext
from agno.tools import tool
@tool
def get_config(run_context: RunContext, key: str) -> str:
return str(run_context.dependencies["config"].get(key))
agent = Agent(
model=...,
dependencies={
"config": {"region": "us-east-1", "max_retries": 3},
"feature_flags": {"beta_search": True},
},
add_dependencies_to_context=True,
tools=[get_config],
)
# 也可以在单次运行时覆盖依赖
agent.run("我的区域是哪里?", dependencies={"region": "eu-west-1"})
讲完了这些,我们就了解了两种常见的上下文注入,其实这两者都很简单。一个就是用知识库的方式,一个就是用程序自动注入的方式。
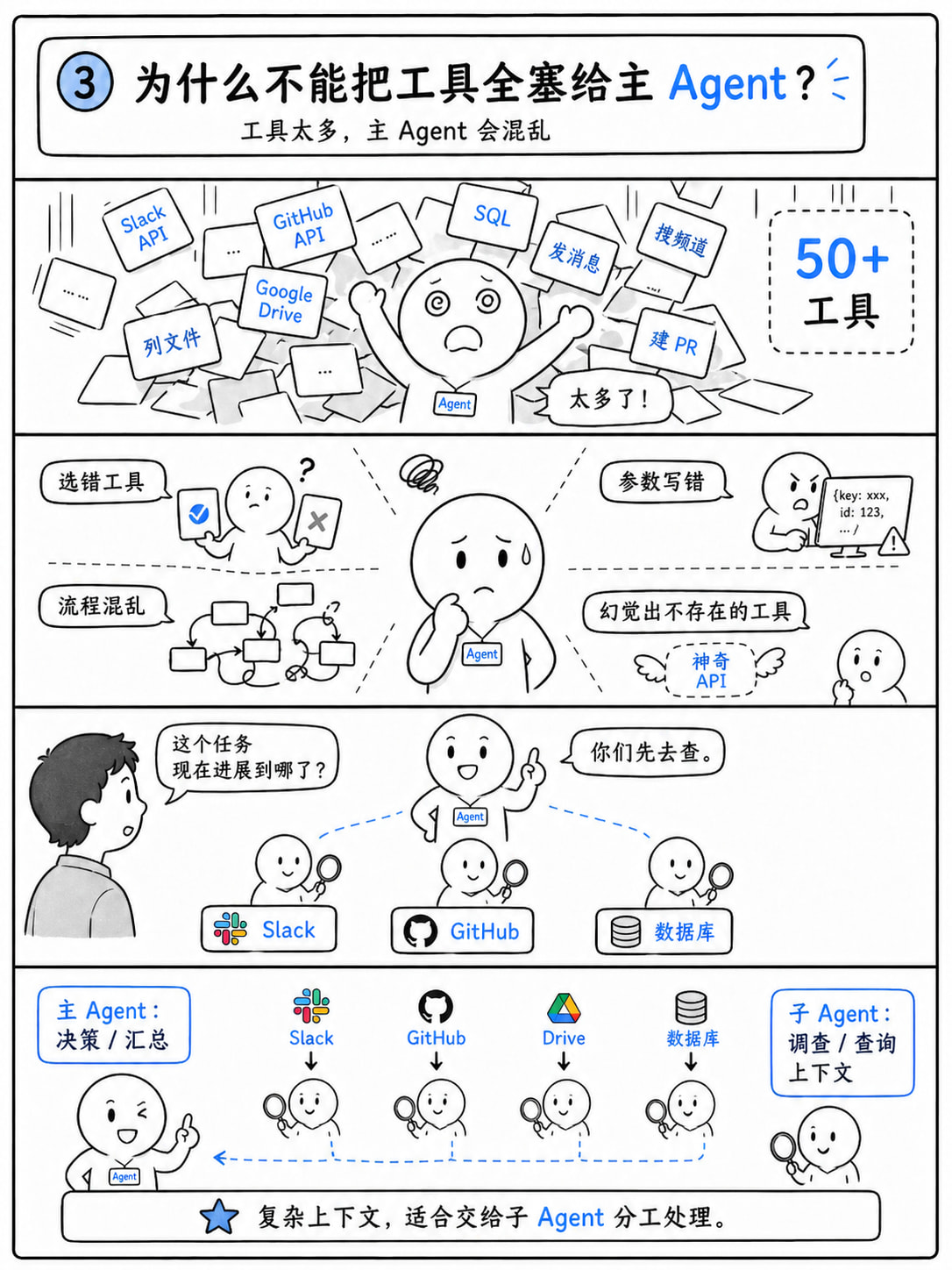
那如果我们需要的上下文比较复杂,不能通过简单查询,就马上得到。比如你需要agent知道今天公司的工作某个任务的进度情况,得同时操作 Slack、GitHub、Google Drive、公司数据库才能得到“这个任务进行到什么程度了”这个上下文。(注意,上下文不是你的目的,你的目的可能更大,需要决策明天的公司加班与否)
而当你定义工具,接入查询工具和其他工具,可能每个系统有 8~15 个 API(发送消息、搜索频道、创建 PR、列出文件、执行 SQL…)
如果你把所有工具直接塞给主 Agent,系统提示词里会塞满 50+ 个工具的描述和参数。
后果:模型会混乱、选错工具、调用参数错误、甚至“幻觉”出不存在的工具。
所以必须引入子agent来做上下文的查询,我们不需要主agent知道那么多细节,只需要子agent去根据问题调查得到上下文,。对于这种子agent,agno提供了context provider来管理。
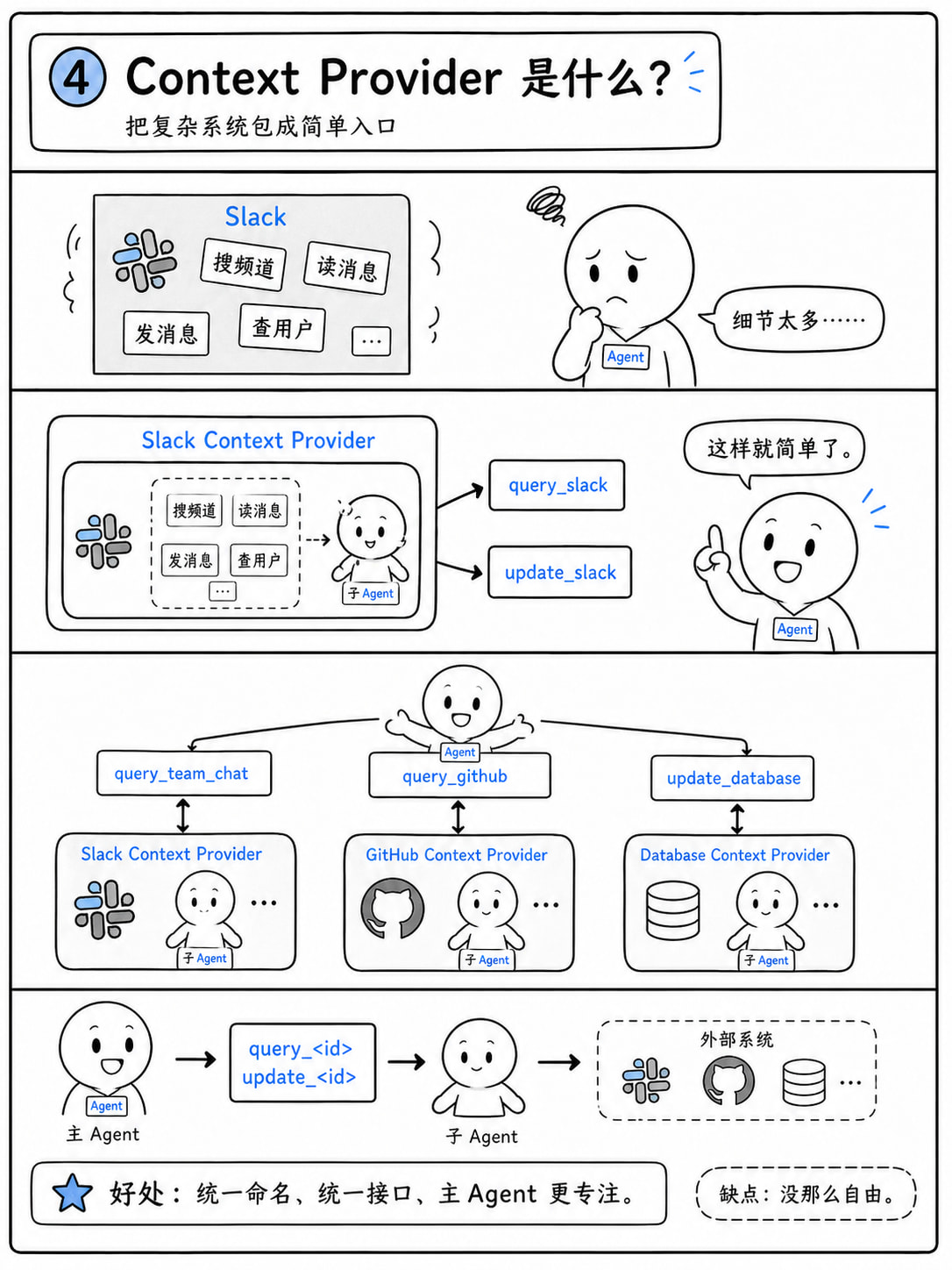
Context Provider
定义:Context Provider 是一个“子 Agent 包装器”,它把整个外部系统(如 Slack、GitHub、数据库)封装成一个只有两个工具的接口:query_<id> 和 update_<id>,供主 Agent 调用。
它就是子agent创建。
不着急实现,我们理解一下原理:
现在主agent希望获取上下文,需要查询两个地方的信息,还有更新数据库(更新在这里也视为一种信息),流程就会如下:
主 Agent
│
┌──────────────┼──────────────┐
│ │ │
query_slack query_github update_database
│ │ │
┌────▼────┐ ┌─────▼─────┐ ┌────▼────┐
│Slack │ │GitHub │ │Database│
│子 Agent │ │子 Agent │ │子 Agent│
└────┬────┘ └─────┬─────┘ └────┬────┘
┌────▼────┐ ┌─────▼─────┐ ┌────▼────┐
│Slack API│ │GitHub API │ │SQL DB │
└─────────┘ └───────────┘ └─────────┘
agno提供了一些内置的provider,直接拥有一些工具
Provider 能力 读写分离FilesystemContextProvider
读取本地目录的文件
只读
WebContextProvider
网络搜索(Exa 或 Parallel 后端)
只读
DatabaseContextProvider
执行 SQL(读/写)
支持只读和写入两个子引擎
SlackContextProvider
查询 Slack 历史、发送消息
读写
GDriveContextProvider
读取 Google Drive 文档
只读
GitHubContextProvider
读取仓库、创建 PR
读写(PR 隔离)
MCPContextProvider
连接任意 MCP 服务器(模型上下文协议)
取决于 MCP
最简单的例子:让 Agent 读取你电脑上的本地文件
from agno.agent import Agent
from agno.context.filesystem import FilesystemContextProvider
# 创建一个 Provider,指定要暴露的根目录
fs = FilesystemContextProvider(id="docs", root="./my_documents")
agent = Agent(
model=...,
tools=fs.get_tools(), # 只有一个工具:query_docs
)
agent.run("帮我找一下 ./my_documents 里有没有关于预算的文档")
Agent 内部会调用 query_docs,传给子 Agent,子 Agent 会遍历目录、读取文件、回答。
基本实现:
from agno.agent import Agent
from agno.context.slack import SlackContextProvider
from agno.context.web import WebContextProvider, ExaBackend
# 1. 创建 Provider 实例
slack = SlackContextProvider(id="team_chat") # id 会成为工具名的一部分
web = WebContextProvider(backend=ExaBackend(), id="web")
# 2. 将工具合并给主 Agent
agent = Agent(
model=...,
tools=[*slack.get_tools(), *web.get_tools()],
# 还可以把 Provider 自带的 instructions 合并进去
instructions="\n".join([slack.instructions(), web.instructions()]),
)
# 3. 运行
agent.run("最近 Slack 里有人问过 Web 搜索吗?")
# 主 Agent 会调用 query_team_chat 获取 Slack 内容,然后可能再调用 query_web 补充信息。
是的,子agent我们分分钟也可以写,不同的是,provider需要遵守contextprovider这个类的写法:
方面 自定义 ContextProvider 手写子 Agent + 工具 继承 必须继承ContextProvider
无(或者继承 Agent,但通常直接实例化)
必须实现的方法
astatus, aquery(以及可选的 aupdate)
无
返回值类型
必须包装成 Answer / Status
任意(通常返回 str)
工具命名
自动变成 query_<id>
自己取名(可能冲突)
指令注入
可提供 instructions() 方法
需要手动拼接提示词
生命周期
自带 asetup/aclose 钩子
需要自己管理资源
我认为最大的好处还是统一,这个子agent的工具会自动命名,如`query_<provider_name>`,后续导出文档也很简单。劣势在于不自由,如果你的子agent很灵活,实现的功能不附属于主agent,那么就自便。
实现
暂时没有灵感,有灵感补上,或者评论来个佬友梦想一个小agent需求呗,我们来试试。
我现在学了这些东西,但是我觉得很多东西对我好像没有用武之地,所以我也经常在现实中思考,到底我们怎么做才能把agent落到我们生活的困难解决中去。
3 个帖子 - 3 位参与者