前言
一直想测试下各种大模型在实际场景下的上下文能力。之前尝试用《首无》做了一版,但是存在剧透,测试不全面等问题。这次灵机一动,直接告诉大模型在输出的时候直接对剧透内容进行模糊处理。所有内容都人工二次检查过,无剧透可放心食用(除了末尾的完整压缩包,那个会给出所有的原始html文件和原始prompt)。
测试方案
我选择了日本小说家三津田信三的推理小说《如首无作祟之物》作为测试。这个《首无》呢,送进各种opencode和kimi code中显示其上下文使用大概是150K左右。我认为是一个比较合适的这样的一个长度,因为目前大部分国产模型所设定的上下文就是200~300K之间,而150K恰好是一个超过100K,接近上限但又没到上限的这样的一个长度。我觉得很多情况下,100K以后的需求其实是很重要,但是又很容易被各种评测和基线忽视掉的,厂商也只会吹上下文有多长,没太大参考价值。
《首无》简单来说,里面有三个案子,每个案子都有自己的核心诡计和唯一真凶。基本上第一个案子是最简单的(核心诡计和真凶都明说了,模型只要注意到即可),第二个案子的诡计叠了两层,同时包含一点叙述诡计,比较能考验模型的上下文能力。第三个案子的诡计不算难但是叙述诡计很多,很考验上下文能力和一定的推理能力。我所用的prompt:
《首无》原文+请用HTML+SVG绘制一份全中文的登场人物关系脉络图,要那种类似思维脑图那种连线样式风格,并且可以看到每个元素具体说明的。要注意这张图可能会展示给没看过的人,所以涉及剧透的部分使用模糊或者隐藏处理,需要把鼠标移上去才能看到具体的内容。
在html的最后,回答几个问题:本文的三个案子,核心诡计分别都是什么?真凶分别都是谁?核心作案手法分别是什么?注意你不要猜,尽量引用小说原文来辅助回答这几个问题。
把最终的结果保存为一个html文件,命名为首无娱乐测试V2_{你的模型名字}.html
可以看到,这个prompt同时考验模型的上下文能力,html作图能力和一定的推理能力。为了避免通过幻觉或者世界知识答对,我直接要求输入原文进行佐证。这个prompt可以在文末压缩包里找到原始txt文件。
所有的测试都在opencode和kimi code(仅kimi)最新版中完成。所有测试除特殊说明外均采用官方接口和官方api key,思考之类的都拉到了最大。过程也检查过了都没有作弊。
本次测试的模型有:stepfun-3.5-flash, MiniMax-M2.7, deepseek-v4-flash, Qwen-3.6-Max-Preview, MiMo-v2.5-pro, Kimi-K2.6, GLM-5.1, deepseek-v4-pro。
测试结果:官方接口
stepfun-3.5-flash
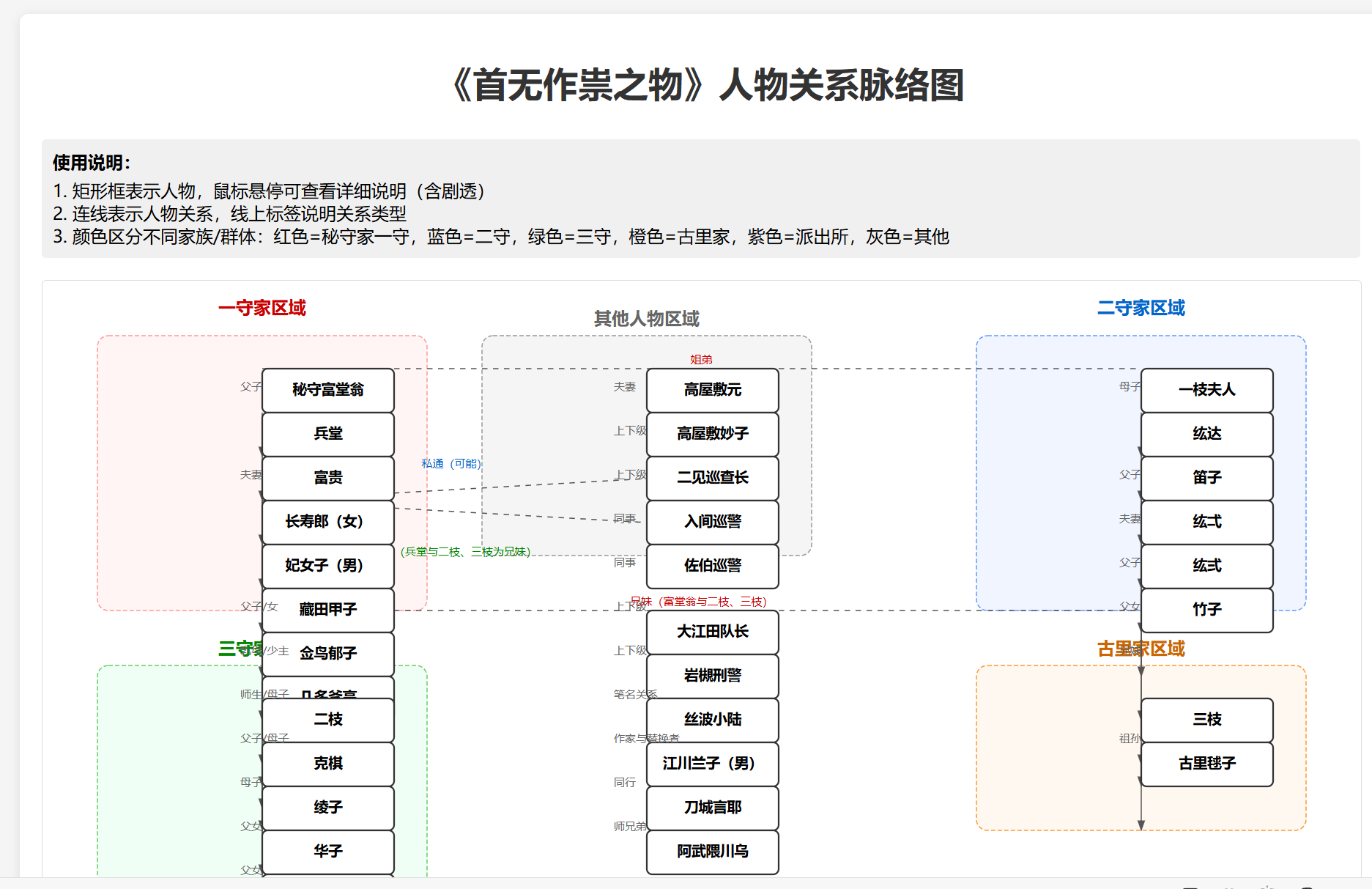
耗时2m47s,是最快的一个。第一案第二案的首发,诡计,真凶,原文都没任何问题。但第三案完全被误导,给出了完全错误的凶手和手法。考虑到其模型大小和速度,这个结果意外的还能接受。布局你们自己评价,反正很简陋,基本没眼看。。哦对了stepfun并没有听话地创造文件,而是直接给我了html源码让我自己去写文件 ![]() 。不过作为一个小模型我也忍了吧。
。不过作为一个小模型我也忍了吧。
MiniMax-M2.7

耗时正好4min。整体布局中规中矩吧,但是第二案第三案都完全被误导了,给出了完全错误的答案。作为一个200+b想主打养虾的模型来说,这个上下文我感觉做事我不是很放心啊。。用起来的时候记得勤压缩上下文吧。
deepseek-v4-flash

耗时23m44s。是的,你没看错。不过我仔细检查了下思考过程,其实大概3分钟就已经出了一版了,后来自己纠结了大概20min去改进网页布局一直在小修,但是仍然布局一坨。。不过令人惊喜的是作为一个200多b的模型,3个案子核心诡计,真凶的回答和理解完全正确。这个上下文能力,学去吧。
Qwen-3.6-Max-Preview

耗时3m24s,但是我必须先吐槽下,这个所谓的旗舰模型犯了和stepfun一样的错误,直接给了我html源码而不是文件!差评!而且最最离谱得是,qwen把三个案子的核心手法和真凶都完全弄错了,甚至第三个案子本身都是错的。。只能说差出天际了。
MiMo-v2.5-pro

耗时5m 19s,但是我比较难绷的是头两次直接给我返回The request was rejected because it was considered high risk.我也不知道risk在哪里?小米的审查这么严吗?我可是直接走的api余额甚至不是token plan。而且和qwen一个毛病,三个案子的真凶都被误导了。不过比qwen好一些,核心手法倒是找到了,就是真凶被误导了。图中有个小剧透被我手动打码了,其实也还好。
Kimi-K2.6
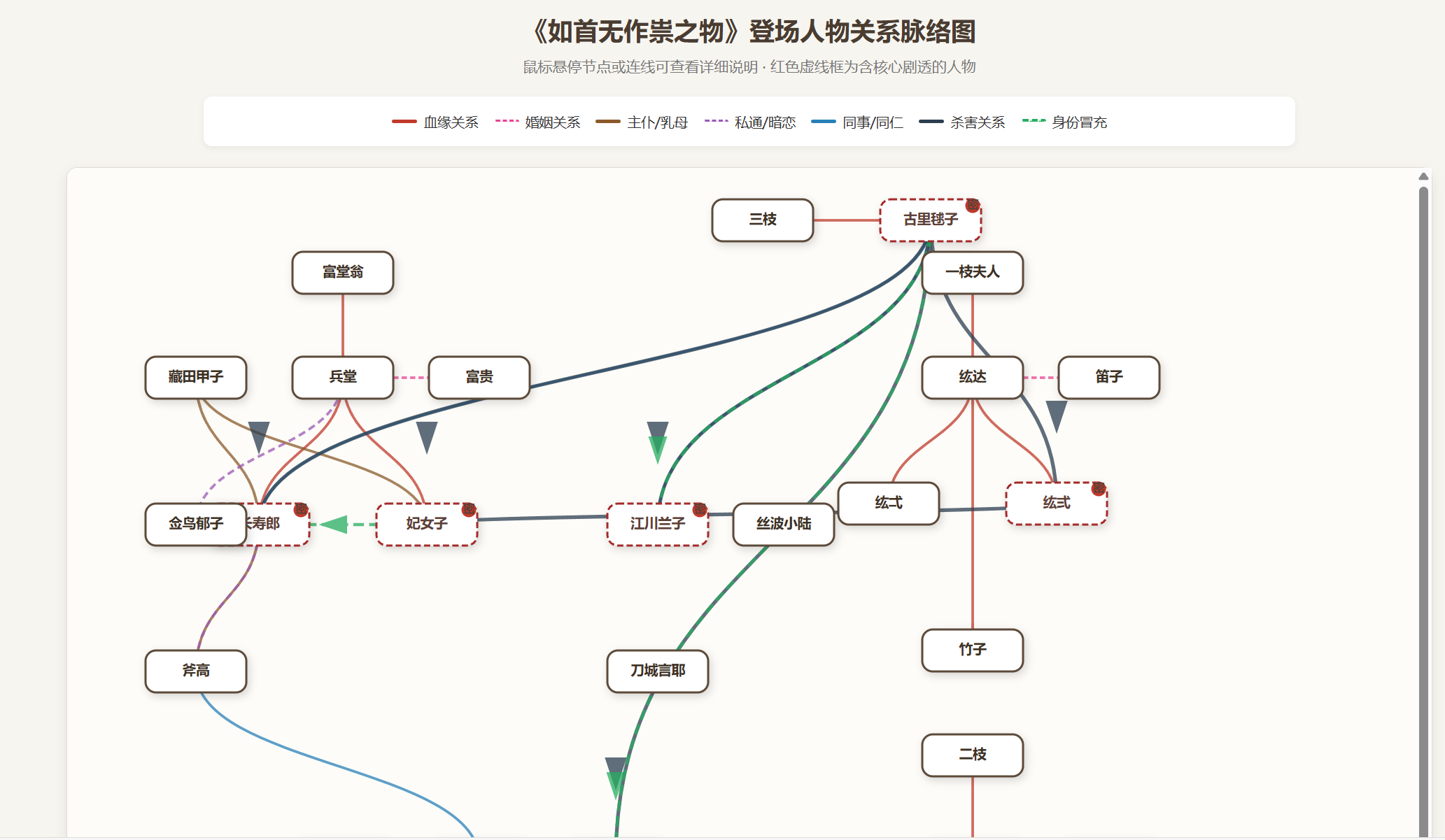
耗时大概7分钟,和上一次一样,3个案子的真凶和核心诡计,手法,完全正确,甚至都引用的原文。我觉得k2.6的262k上下文应该也是真的。
GLM-5.1
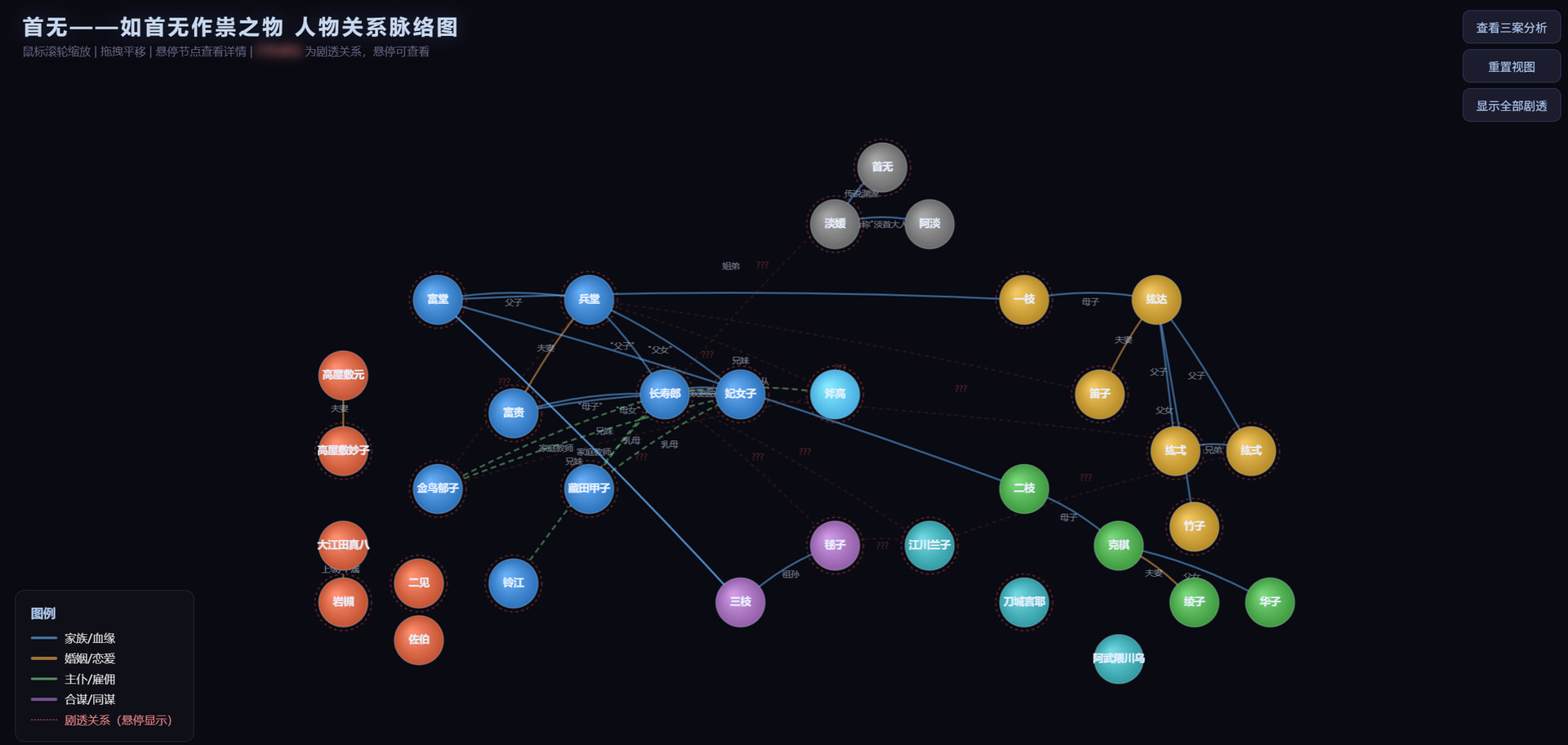
耗时5m 54s,这次没有中断。可以看到整体的布局和网页设计我觉得是目前为止最强最舒服的一个。可惜第二案和第三案被部分误导了,看来glm5.1的上下文能力还是有进步空间呐。
deepseek-v4-pro

耗时8m38s。这个网页布局我觉得也很可以了,该避免剧透的部分也设计的很舒服。三个案子的真凶和核心诡计手法也都没有悬念,甚至推理出了一些原文没明说只是暗示的隐藏信息,没想到还有惊喜。还是那句话,学去吧。
测试结果:非官方接口
Opencode Go中的deepseek v4 pro max
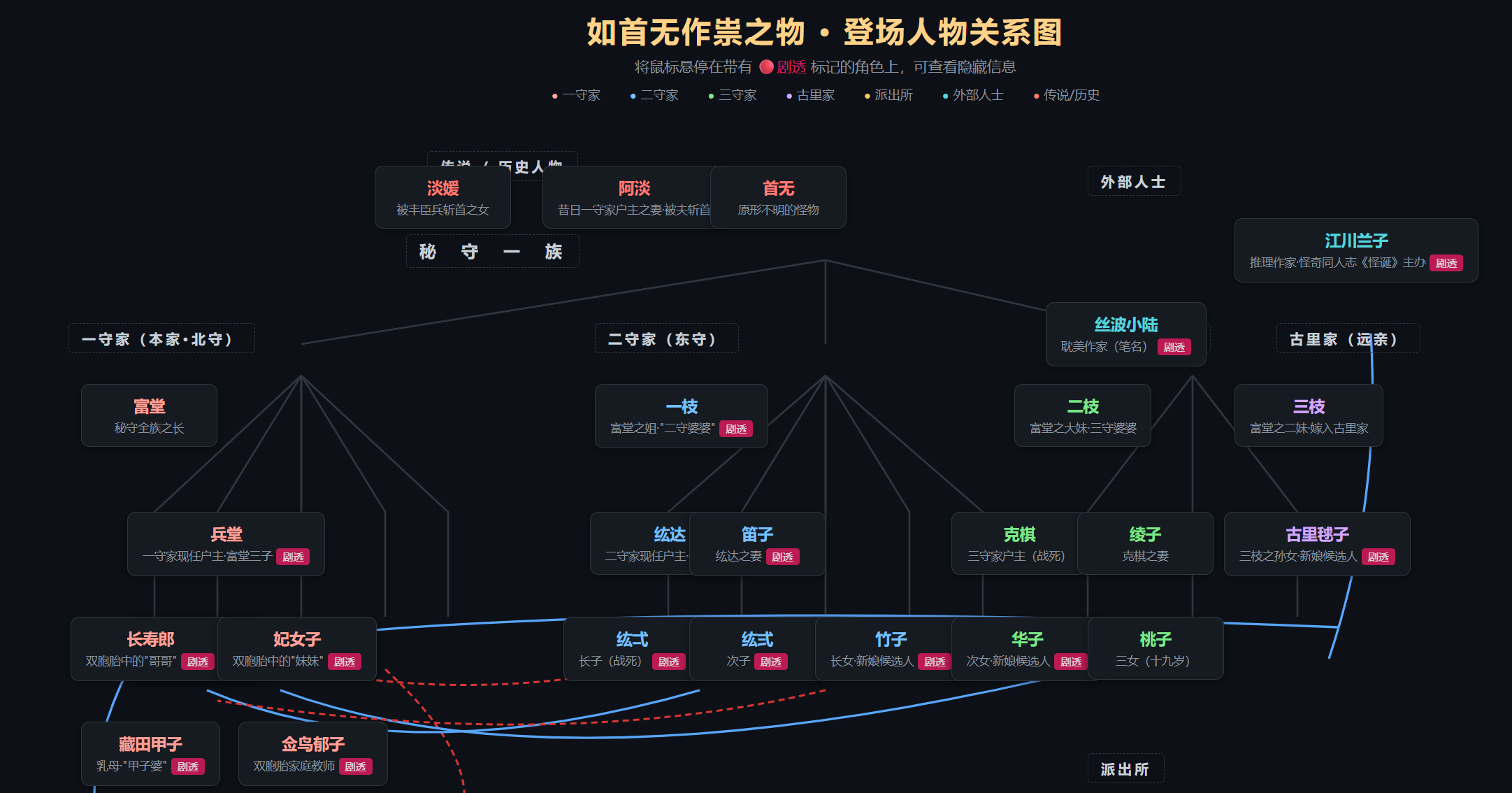
耗时29m30s。不过我觉得也是和中国地区的连通性有关,经常在那卡半天,不知道是网的问题还是服务器的问题。3个诡计和解答问题不大,但是第二个案子略微被误导,同时也没有推理出隐藏剧情,网页布局也不如官方api的,我很怀疑opencode go中的deepseek v4 pro并不是满血,用的时候要谨慎。
最终总结
网页布局各位可以自行评价。从对长上下文和剧情的理解来看,kimi-k2.6和deepseek-v4双模型都是顶尖那档的。glm,minimax,stepfun算是中规中矩吧,mimo和qwen真的是拉完了,和吹的体感完全不一样。。叠甲:这些都是个人的娱乐测试,仅代表个人观点,不作为任何结论。欢迎各位讨论和理性分析。包含提示词和各个模型最终输出的压缩包在下面,各位可以按需下载,自行复现和测试。
首无娱乐测试v2.zip (356.2 KB)
8 个帖子 - 6 位参与者