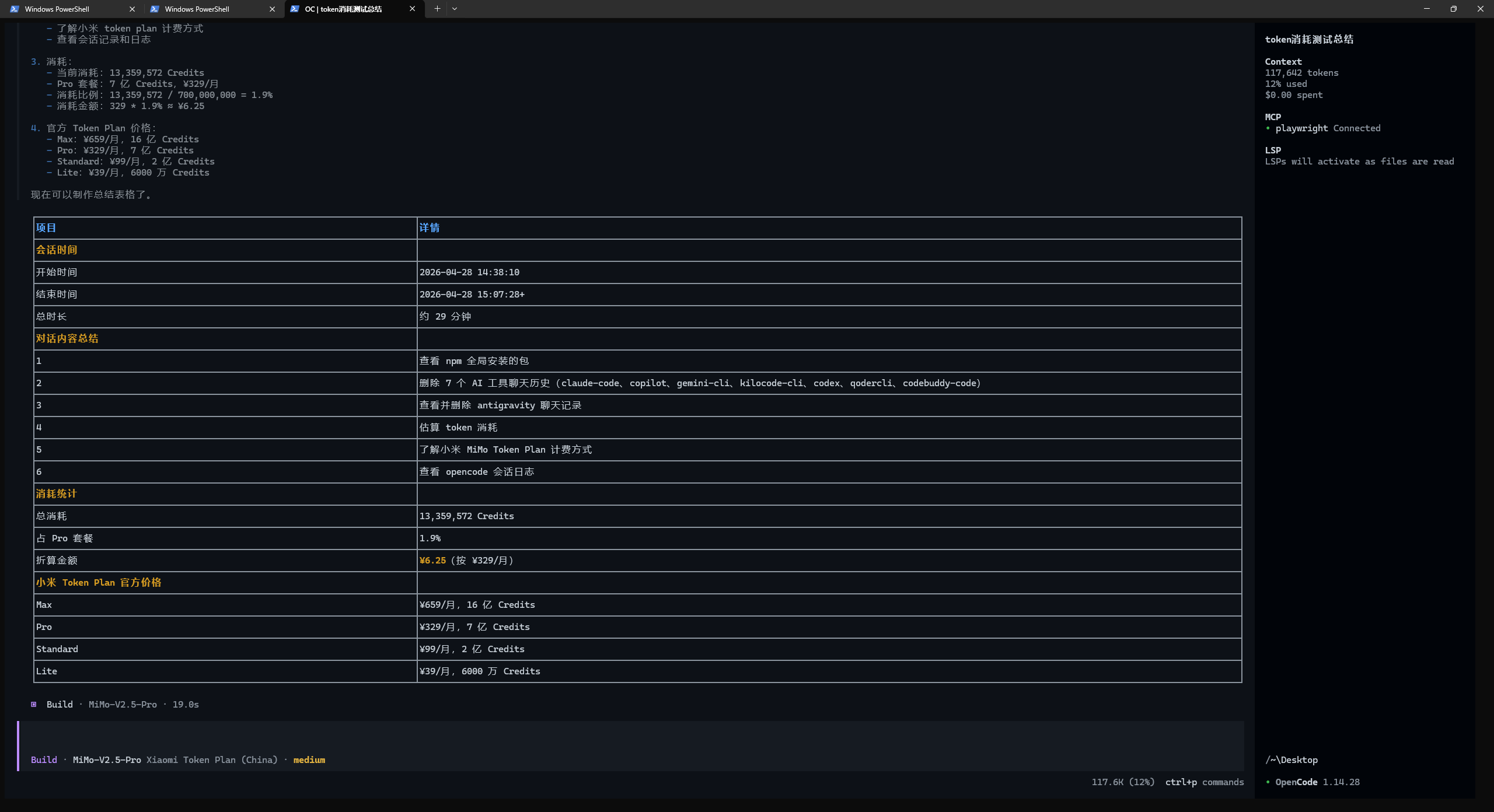
用领取到的小米token plan试了一下,原来opencode这种智能体这么消耗token,半个小时1300w的token(6块钱)没了,这还只是国内的模型,真吓人。

然后用美团的LongCat试了一下纯文本的token消耗,是Ai写了一个脚本测试的,和opencode这种工具调用的差太多了,半个小时下来400w的token。
# -*- coding: utf-8 -*-
"""
高并发挥霍 Token(个人本机自用):无预算、无熔断、不测价。
拉大 concurrent / total_calls / max_tokens 即可更猛;服务端限频时请自行调高或调低并发。
依赖: pip install "openai>=1.0"
"""
from __future__ import annotations
import asyncio
import sys
import time
from dataclasses import dataclass
try:
from openai import AsyncOpenAI
except ImportError:
print("请先安装: pip install openai")
sys.exit(1)
# ========= 只改这一段 =========
@dataclass(frozen=True)
class C:
base_url: str = "https://api.longcat.chat/openai/v1"
api_key: str = "*************"
model: str = "LongCat-Flash-Lite"
# 单次回复长度上限(越大、烧得越快,视服务端上限改)
max_tokens: int = 8192
temperature: float = 0.9
# 同时进行的最大请求数(受本机与对方限流影响,自己试到稳定上限)
concurrent: int = 64
# 一共发多少次 chat 请求;想一直跑到手动 Ctrl+C 可把下面改成 run_forever 版(见文件末尾注释)
total_calls: int = 102400
# 极短输入 + 逼着长输出,偏输出 token
user_content: str = "直接输出尽可能多的连续文字,填满回复,不要寒暄,不要 Markdown,不要分段标题。"
CFG = C()
# =========
async def burst(cfg: C) -> None:
timeout = float(max(120.0, cfg.max_tokens * 0.05))
client = AsyncOpenAI(
api_key=cfg.api_key,
base_url=cfg.base_url,
timeout=timeout,
max_retries=0,
)
sem = asyncio.Semaphore(cfg.concurrent)
done = 0
ok_calls = 0
bad = 0
total_prompt = 0
total_completion = 0
lock = asyncio.Lock()
started = time.perf_counter()
async def progress() -> None:
nonlocal done
elapsed = time.perf_counter() - started
rate = done / elapsed if elapsed > 0 else 0.0
print(
f"\r完成 {done}/{cfg.total_calls} "
f"有usage {ok_calls} 异常 {bad} "
f"p={total_prompt:,} c={total_completion:,} "
f"{rate:.1f} req/s ",
end="",
flush=True,
)
async def one(_: int) -> None:
nonlocal done, ok_calls, bad, total_prompt, total_completion
async with sem:
try:
r = await client.chat.completions.create(
model=cfg.model,
messages=[{"role": "user", "content": cfg.user_content}],
max_tokens=cfg.max_tokens,
temperature=cfg.temperature,
)
u = r.usage
async with lock:
done += 1
if u is not None:
ok_calls += 1
total_prompt += u.prompt_tokens or 0
total_completion += u.completion_tokens or 0
await progress()
except Exception:
async with lock:
done += 1
bad += 1
await progress()
await asyncio.gather(*(one(i) for i in range(cfg.total_calls)))
elapsed = time.perf_counter() - started
print()
print("-" * 56)
print(f"耗时 {elapsed:.2f}s 平均 {cfg.total_calls / elapsed:.2f} req/s")
print(f"响应里含 usage 的次数: {ok_calls} 请求异常: {bad}")
print(f"累计 prompt_tokens: {total_prompt:,} completion_tokens: {total_completion:,}")
if total_prompt + total_completion:
print(f"合计约 {total_prompt + total_completion:,} tokens(以服务端 usage 为准)")
def main() -> None:
c = CFG
print("高并发烧 Token")
print(f" {c.base_url}")
print(f" model={c.model} concurrent={c.concurrent} calls={c.total_calls} max_tokens={c.max_tokens}")
asyncio.run(burst(c))
if __name__ == "__main__":
main()



3 个帖子 - 2 位参与者
来源: linux.do查看原文