叠甲:本帖子不含xxxxxx和某企业关联的新闻,请放心阅读,如有错误请理性讨论并指出,如果你不想看这个帖子点击右上角关掉浏览器(macOS为左上角),请不要恶意举报
ChatGPT 5.5发布
OpenAI在4月23日发布了ChatGPT 5.5模型,Terminal Bench 2.0和CyberGym表现出色,前端质量也有很大改善
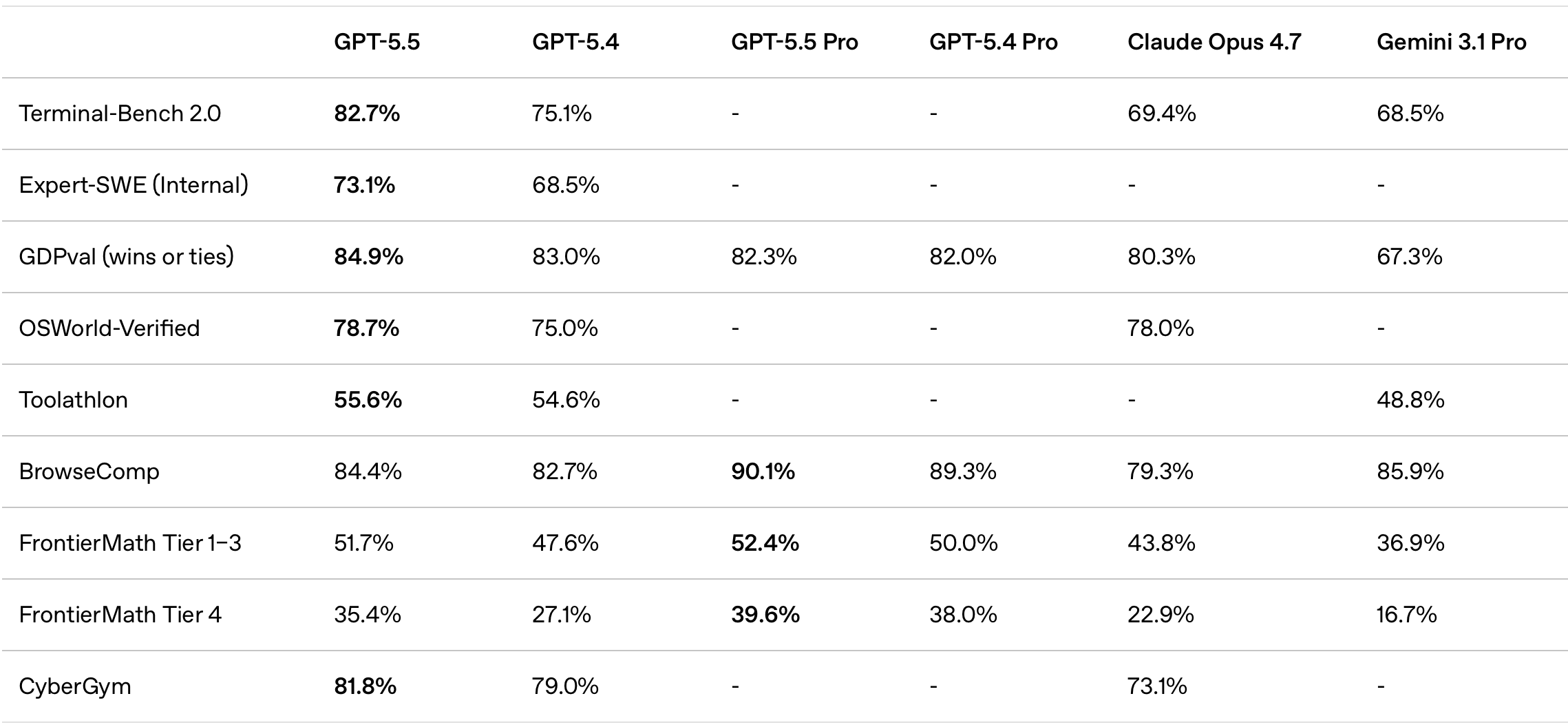
为啥没有SWE Bench Pro?报喜不报忧呗。
如下是GPT 5.5 vs GPT 5.4 vs Claude Opus 4.6 vs GLM 5.1 VS Kimi 2.6的榜单
Opus 4.7暂不列出
编码类
Benchmark GPT-5.5 GPT-5.4 Claude Opus 4.6 GLM-5.1 Kimi K2.6 领先 SWE-Bench Pro 58.6 57.7 53.4–57.3 58.4 58.6 GPT-5.5 / Kimi K2.6 并列 Terminal-Bench 2.0 82.7 75.1 / 65.4 65.4 63.5 66.7 GPT-5.5 Expert-SWE Internal 73.1 68.5 — — — GPT-5.5 SWE-Bench Multilingual — — 77.8 — 76.7 Claude Opus 4.6 SWE-Bench Verified — — 80.8 — 80.2 Claude Opus 4.6 SciCode — 56.6 51.9 — 52.2 GPT-5.4 OJBench Python — — 60.3 — 60.6 Kimi K2.6 LiveCodeBench v6 — — 88.8 — 89.6 Kimi K2.6Agent工作
Benchmark GPT-5.5 GPT-5.4 Claude Opus 4.6 GLM-5.1 Kimi K2.6 领先 HLE-Full w/ tools 52.2 52.1 53.0 / 53.1 52.3 54.0 Kimi K2.6 BrowseComp 84.4 82.7 83.7 / 84.0 68.0 / 79.3 w context 83.2 GPT-5.5 BrowseComp Agent Swarm — — — — 86.3 Kimi K2.6 DeepSearchQA F1 — 78.6 91.3 — 92.5 Kimi K2.6 DeepSearchQA Accuracy — 63.7 80.6 — 83.0 Kimi K2.6 Toolathlon / Tool-Decathlon 55.6 54.6 47.2 40.7 50.0 GPT-5.5 MCP Atlas / MCPMark 75.3 70.6 / 62.5 56.7 / — 71.8 55.9 GPT-5.5 on OpenAI MCP Atlas OSWorld-Verified 78.7 75.0 72.7 — 73.1 GPT-5.5 Tau2-bench Telecom 98.0 92.8 — — — GPT-5.5从上面榜单可以看出,GPT 5.5也不是可以到平替Opus的级别吧。
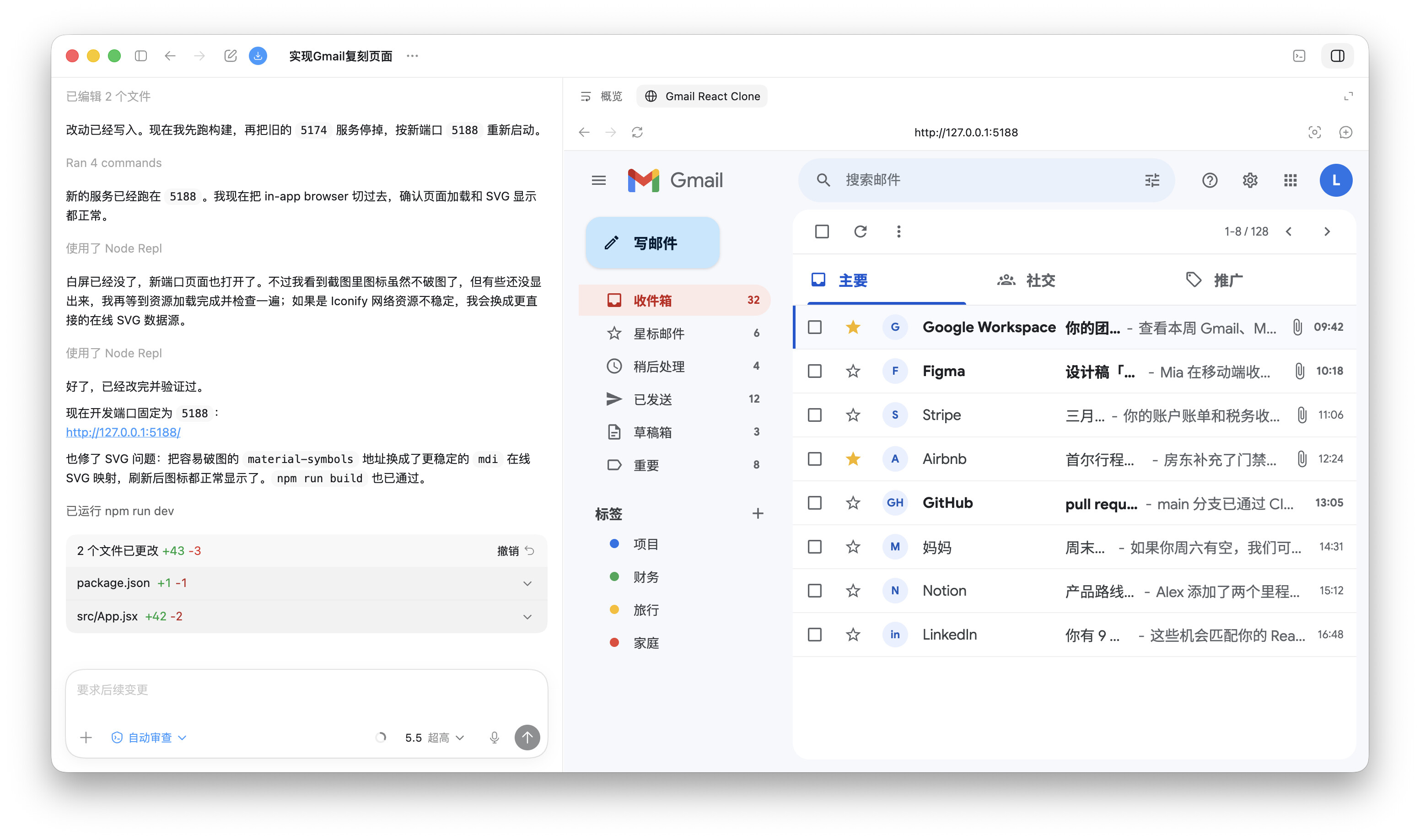
实测:复刻Gmail页面,没有使用提示词工程,效果很可以,相比于上一代GPT 5.4有大幅提升(前端)
1 个帖子 - 1 位参与者
来源: linux.do查看原文