- 我的帖子已经打上 开源推广 标签: 是
- 我的开源项目完整开源,无未开源部分: 是
- 我的开源项目已链接认可 LINUX DO 社区: 是
- 我帖子内的项目介绍,AI生成、润色内容部分已截图发出: 是
- 以上选择我承诺是永久有效的,接受社区和佬友监督: 是
以下为项目介绍正文内容,AI生成、润色内容已使用截图方式发出
2025年末bash is all need思想的普及,包括claudecode,codex,cursor,antigravity等ai编程工具都采用了bash命令这种思想,例如,当我们让ai找一个具体的代码的时候,他会grep搜索相关的关键词,不停的翻看查找,这就有一个问题,我们刚操作ai助手的时候,他是一个比较纯洁的上下文,所以性能是最强的时候,随着上下文增多,性能越来越差,佬友们肯定感同身受。在算法层面,transform架构也面临同样的问题,deepseek-ngram(ps:有幸改了一个单词误用作为了deepseek-ngram仓库的贡献者)提出了一种解决思想,以空间为代价,换取性能上的优化,我的这个开源项目也借鉴了这种思想。
github.com
GitHub - study8677/antigravity-workspace-template: 🪐 The ultimate starter kit for AI IDEs, Claude...
🪐 The ultimate starter kit for AI IDEs, Claude code,codex, and other agentic coding environments.
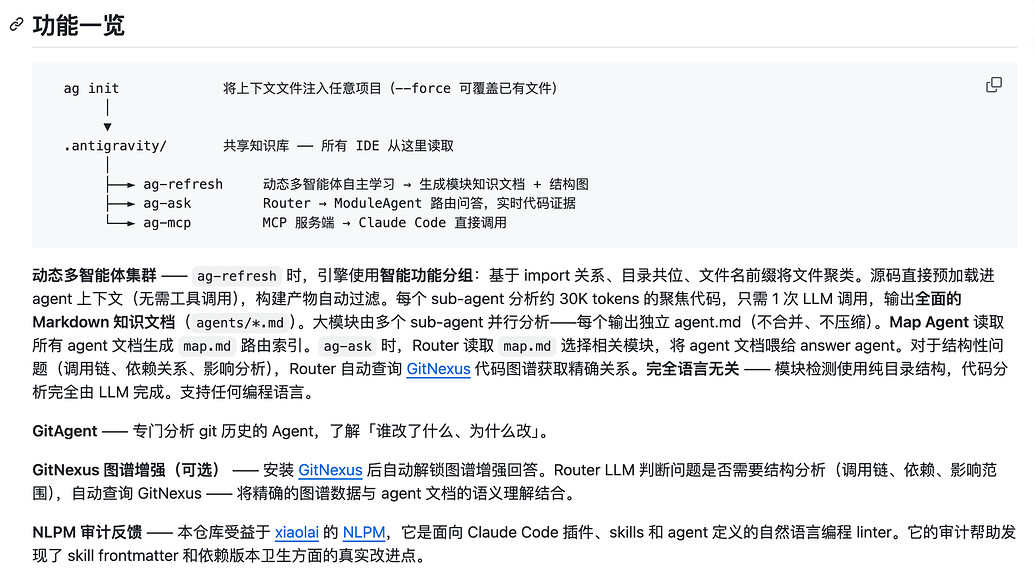
具体的思路如图,维护一个项目知识库及agent,claudecode和codex这种工具只需要ask就可以获取项目的非常详细的细节,而不用牺牲上下文,这个方案和subagent获取信息相比,更全面,也兼顾不同架构之间的信息,同时他也不依赖最顶级的claude/gpt的编程模型,测试时,minmax2.7这个级别的模型便可以很好的完成任务。
同时agent.md文件用的是python的import this,这个很简洁,平时使用也一直在用为系统提示词
项目开源之后,因为运气原因,不知不觉就1.1kstar了,逛l站也很久了,也开源了一些东西,也希望分析给佬友,如果有issue或者方向的指点,感激不尽。
当前的难点也很明显,之前只规划于python项目,所以有一层import架构层,有一个issue提出go项目不能用,所以就砍掉,借鉴了另一个知识图谱的项目,然后github_trending上有一个把仓库向量搜索的解决方案,个人认为向量匹配这方面并不是很优雅的解决方案,原因是,不够简单明了。
当前方案还有一个问题是,每次refresh都要全部来形成agent.md,这个很有问题,目前正在寻找解决方案,即每次只需要刷新改动部分,和git部分就好了。
(ps:在进入l站前,项目一直停滞,虽然实习公司报销订阅费,但是一直没有api来使用,感谢各位佬的教程,反代教学,得以咸鱼30块买到质保teams,项目才能很好的推进)
如果需要项目经历,欢迎pr,非破坏性质都会合并。
欢迎star
10 个帖子 - 5 位参与者
来源: linux.do查看原文