Key Takeaways 要点总结
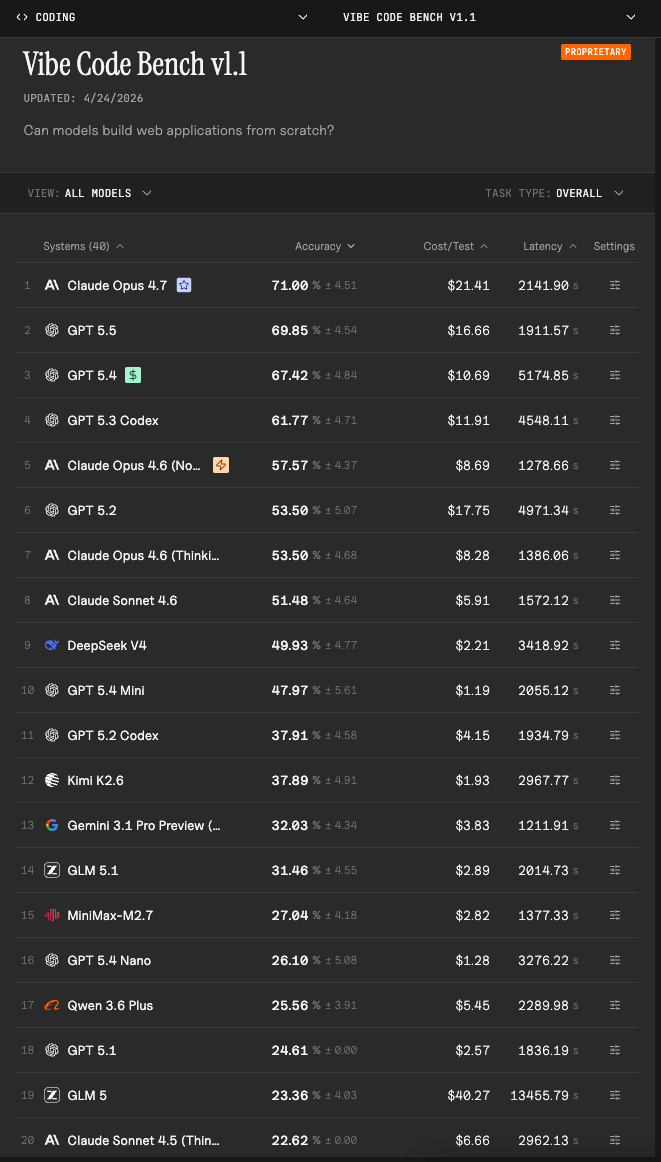
- Claude Opus 4.7 now leads at 71.00% overall accuracy, ahead of GPT 5.4 (67.42%), GPT 5.3 Codex(61.77%), and Claude Opus 4.6 (Nonthinking)(57.57%).
Claude Opus 4.7 现在以 71.00% 的总体准确率领先,高于 GPT 5.4 (67.42%)、GPT 5.3 Codex (61.77%) 和 Claude Opus 4.6 (Nonthinking) (57.57%)。 - The top seven models are relatively tightly clustered (71.00% down to 51.48%), followed by a sharp drop to the middle tier (rank 9 at 37.91%).
前七个模型的准确率相对紧密聚集(从 71.00% 降至 51.48%),随后急剧下降到中档水平(排名第 9 的准确率为 37.91%)。 - Distribution across apps remains highly uneven: even the top model still has non-trivial low-performing apps, while weaker models remain concentrated in the lowest pass-rate bin.
各应用中的分布仍然高度不均衡:即使是最高准确率的模型仍有表现不佳的应用,而较弱模型的准确率则集中在最低通过率区间。 - Open-source/open-weight models underperform relative to top closed models on this benchmark, and cross-benchmark ordering does not transfer cleanly from SWE-Bench/Terminal Bench.
开源/开放权重模型在这个基准测试中的表现不如顶尖的封闭模型,并且跨基准的排序并不能从 SWE-Bench/Terminal Bench 顺利迁移。 - Even at rank 1, roughly one-third of workflows fail, so reliable end-to-end app generation is still unsolved.
即使在排名第一的情况下,大约三分之一的流程会失败,因此可靠的端到端应用生成仍然未得到解决。
1 个帖子 - 1 位参与者
来源: linux.do查看原文