最近手头订阅了智谱 GLM 和 MiniMax 的 Coding Plan。但在实际使用中,遇到一个极其蛋疼的资源错配问题:GLM 不够用,MiniMax用不完
1. 遇到的问题
之前我使用的是 Claude Code,为了充分利用两个coding plan
计划是用 NewAPI 做一层套壳路由,在不同的 Agent 任务中配置不同的模型,实现自动分流。但实操下来完全不可行: 一旦触发了官方 API 的 429 Rate Limit(并发或限流报错),Claude Code 会直接将连接降级为非流式(Non-streaming)。
并且非流式的响应速度慢得令人发指,需要 100s 到 300s 才能返回一次内容。这时候终端界面就跟死机了一样卡在那里,并且在后台一直重试。如图:
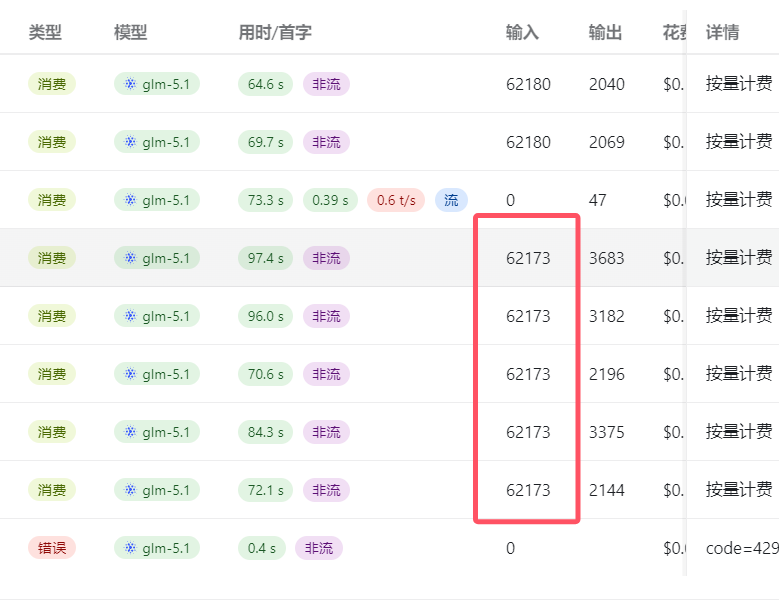
深挖根因分析: 这大概率是协议格式背的锅。Claude Code 底层强制使用 Anthropic 的专属 XML 格式。当流式传输中断或报错时,模型吐出的 XML 标签损坏,导致没有返回 CC 期待的正确格式。CC 客户端的底层逻辑误以为是网络波动,就会一直重试,最终演变成死循环。
2. 解决思路
为了根治这个底层的协议病,我迁移到了OpenCode。
它原生支持 OpenAI 格式。 没有了强扭的 Anthropic 格式转换,API 429会自动重试,而不是转化成非流。
我之前不愿意更换工具的原因是担心迁移成本,但是实测下来迁移成本很低。
OpenCode 可以直接读取ClaudeCode现有的 Skill。只需要在 TUI 界面配置好 API 和 Key,然后在终端里直接和 AI 对话,让它自己把之前的 MCP 服务安装到 OpenCode 目录下即可。
3. 大模型分流
解决掉工具链的问题后,还需要实现 OpenCode 实现 GLM 和 MiniMax 的完美切分,这才是我切换工具的目的。
我的策略是“按需分配”:把脏活累活(查文件、写总结、压缩上下文)交给便宜量大的 MiniMax,把核心的写代码任务给 GLM-5.1。
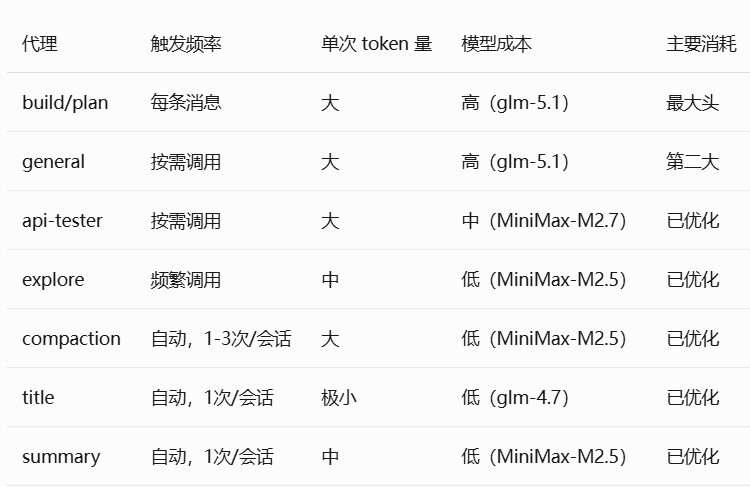
下附我的 opencode.json 路由配置:
{
"$schema": "https://opencode.ai/config.json",
"disabled_providers": [],
"agent": {
"explore": {
"model": "newapi/MiniMax-M2.5"
},
"compaction": {
"model": "newapi/MiniMax-M2.7"
},
"title": {
"model": "newapi/MiniMax-M2.5"
},
"summary": {
"model": "newapi/MiniMax-M2.5"
}
},
"provider": {
"newapi": {
"name": "newapi",
"npm": "@ai-sdk/openai-compatible",
"options": {
"baseURL": "https://newapi.XXX.cn/v1"
},
"models": {
"glm-4.7": { "name": "glm-4.7" },
"glm-5": { "name": "glm-5" },
"glm-5.1": { "name": "glm-5.1" },
"glm-5-turbo": { "name": "glm-5-turbo" },
"MiniMax-M2.5": { "name": "MiniMax-M2.5" },
"MiniMax-M2.7": { "name": "MiniMax-M2.7" }
}
}
}
}
我尝试让opencode跑一个测试的subagent,再解决里面存在的问题
实测跑下来,大约有 50% 的高频轻量接口请求被路由到了 MiniMax,并且subagent的上下文没有携带到主agent当中
下面讲讲这么操作的优点:
- MiniMax 处理探索和总结类的任务时,吐字速度明显快于 GLM。
- 上下文短了以后注意力更集中:主 Agent 的脑容量是有限的。在这套架构下,Subagent的运行逻辑类似于函数调用。它在独立的进程里查日志、跑测试,测试完毕后,只把最终的排查结果返回给主 Agent。
主 Agent不需要知道测试脚本是怎么跑的,这就极大程度地避免了无用日志污染上下文。对 AI 来说,上下文越干净,找 Bug 和改代码就越准。
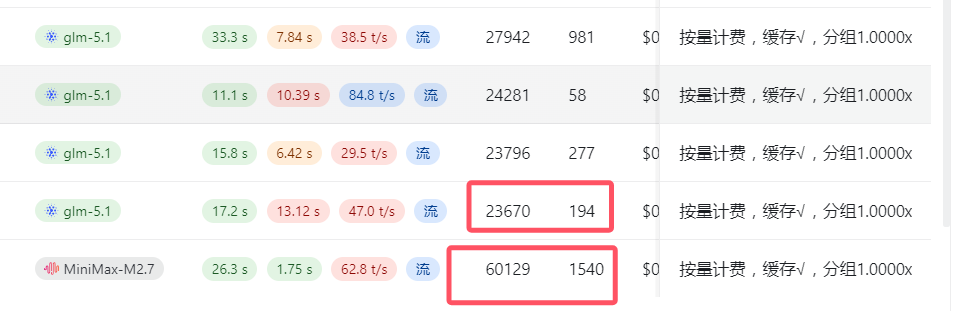
大家可以看对比图,MiniMax 探索完文件系统后,交接给 GLM 的上下文其实被砍掉了一大截,但丝毫不影响 GLM 后续修改代码:
 最后是鸣谢
最后是鸣谢
特别鸣谢 @钟阮 钟佬提供的技术支持以及二开的 NewAPI,这两天频繁私信骚扰,钟佬还是不厌其烦的给我聊思路聊实现,十分感谢
1 个帖子 - 1 位参与者