个人见解 不喜勿喷
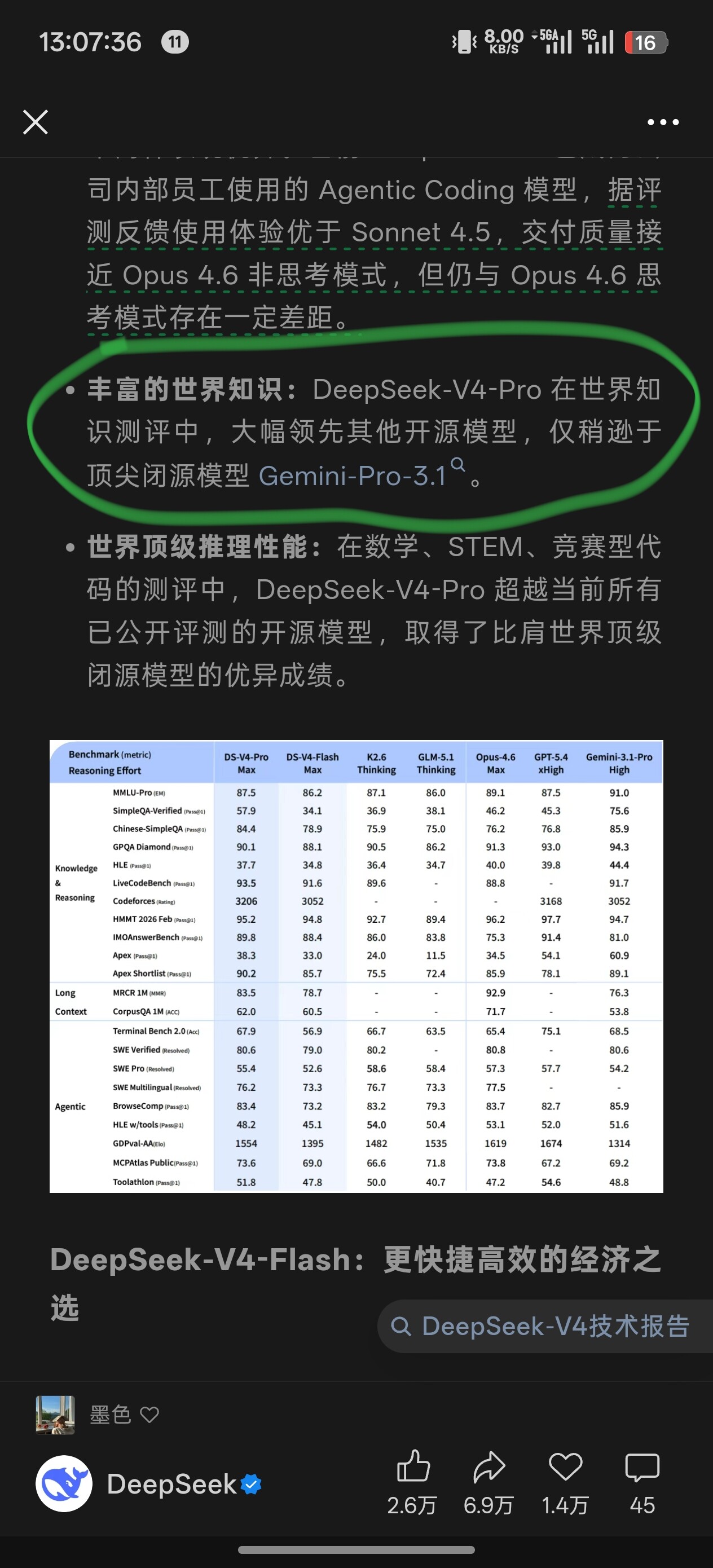
v4 别的不说,世界知识这一点确实牛逼大了 这预训练真的下了难以想象的苦工或者说技术突破了…
Claude和gpt其实也没做到接近gemini的世界知识
国内更是没有一家能碰瓷的 都在玩coding特化这条路,比如靠opus迭代 蒸馏的就发个版本的minimax,刷分刷的离谱,实际体验拉胯,kimi整体好点但也是分和体验对不上的。也就glm蒸出点东西了,分数和coding体验比较接近。至于qwen那种不知道什么原因参数越大越不行 出现很强边际效应的,预训练肯定也有很大问题。
不用说,现在其他国模肯定在连夜赶紧知识蒸馏v4甚至基于二次预训练
想各种办法融合到他们的moe里了
deepseek这下真的源神了
如果deepseek不开源开放权重 其他国模这辈子应该都不会有这样的世界知识水平
3 个帖子 - 3 位参与者
来源: linux.do查看原文