硬件配置
组件 规格 CPU Intel i5-13600K GPU RTX 4090 48G + RTX 4070Ti 12G 内存 DDR4-3600 128G (4x32G) 主板 华硕 Z690-P D4 系统 Windows 11 LTSC WSL Ubuntu 22.04VLLM版本:0.19.1
部署指令:
uv venv vllm-env --python 3.12 --seed --managed-python
source vllm-env/bin/activate
uv pip install vllm --torch-backend=auto
启动参数:
vllm serve /root/LLM/Qwen3.6-27B-FP8 --host 0.0.0.0 --port 8000 --tensor-parallel-size 1 --max-model-len 262144 --reasoning-parser qwen3 --enable-auto-tool-choice --tool-call-parser qwen3_coder --speculative-config ‘{“method”:“qwen3_next_mtp”,“num_speculative_tokens”:2}’ --kv-cache-dtype fp8 --gpu-memory-utilization 0.92 --max-num-seqs 4 --max-num-batched-tokens 4096 --enable-prefix-caching --attention-backend FLASHINFER --served-model-name Qwen3.6-27B
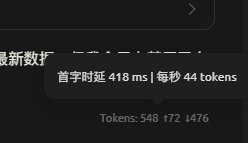
速率(cherry studio):
generation_config.json:
{‘temperature’: 1.0, ‘top_k’: 20, ‘top_p’: 0.95}
个人观点:我不建议使用任何非官方出品的蒸馏、量化版本,GGUF等。之前在3.5的时候,我几乎体验遍了所有的其他模型,体验感非常差。特别是ollama、lm studio这类方式部署的,完全和官方出品的不是一个层级的(并非精度问题)。
结论(非数据党,纯体感):3.6比3.5强非常多!特别是长任务,多级tools调用上。表现非常优异!目前VLLM开启MTP速率在45tok/s左右,坐等SGLang支持,目前SGLang对FP8兼容有BUG,会胡言乱语,看issuse有修复,还没合并,SGLang在3.5可以达到60tok/s
以下多图杀猫
主体验Hermes
截图继续上下文工作,ocr能力优秀。
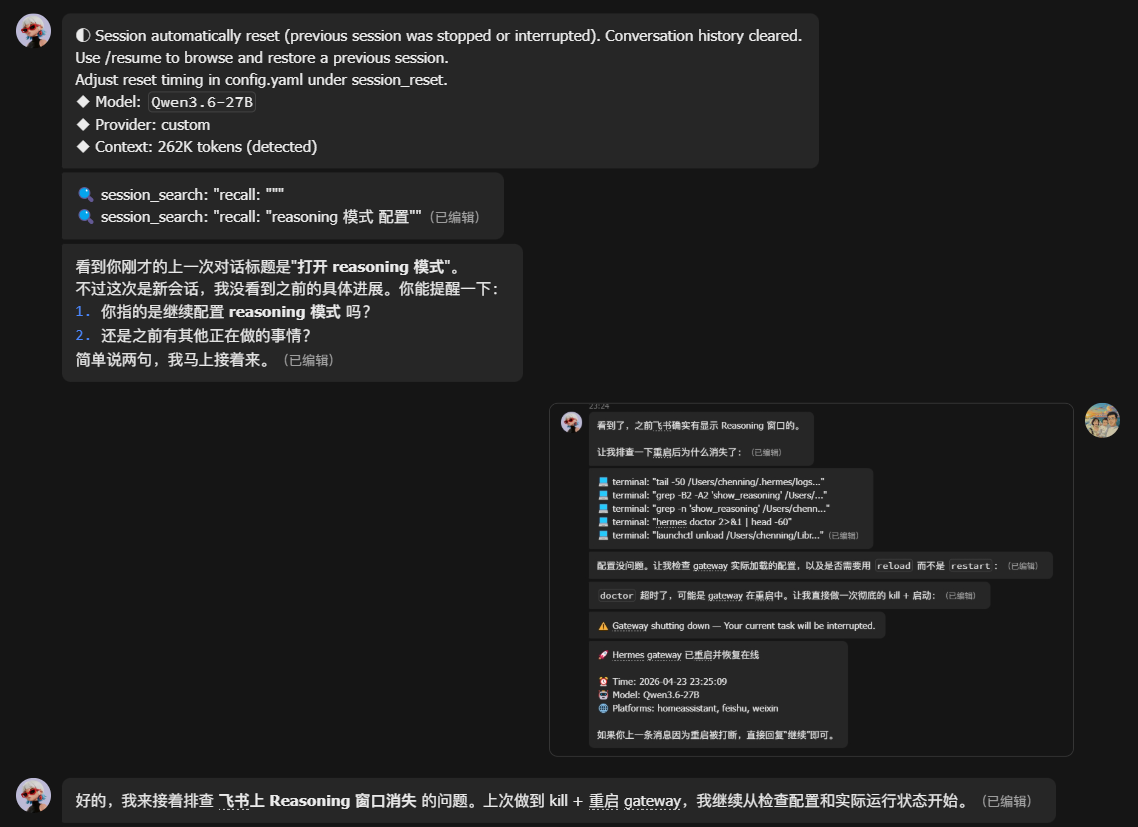
26次工具连续调用不犯浑
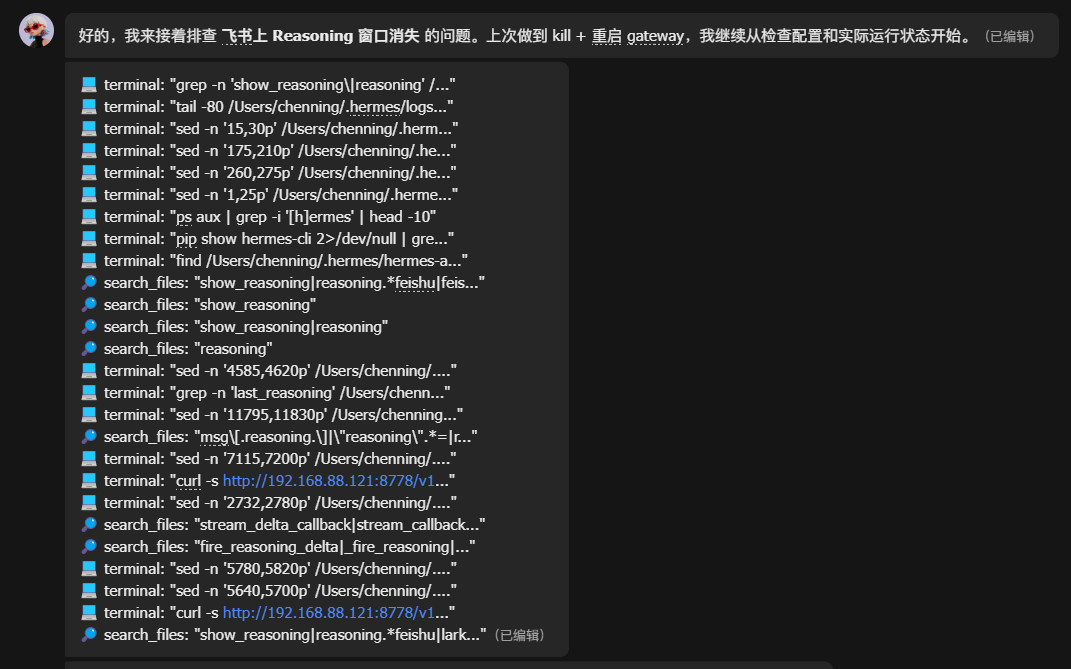
自我debug,以前3.5不会主动提自己能知道怎么修某些bug。(可能存在认知偏差)

复合型长难skill完成度优秀!接近gpt-5.4水准。

内容赏析
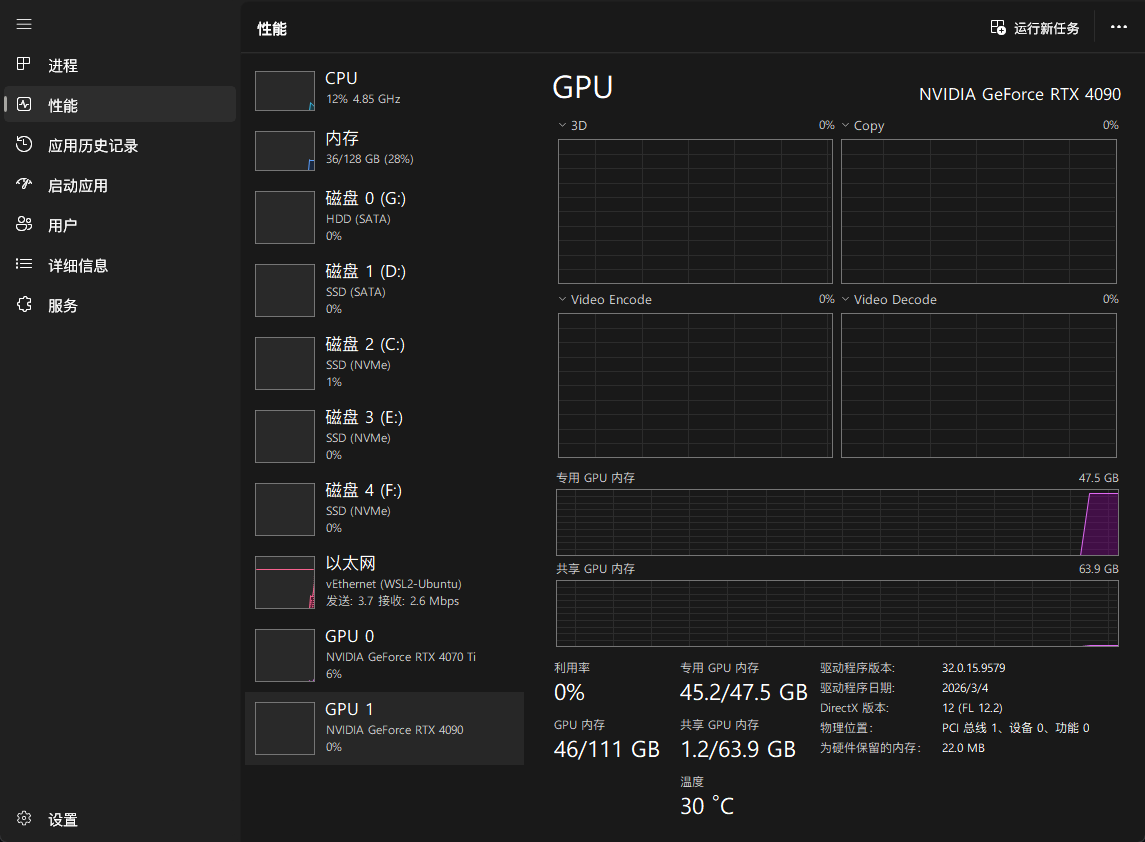
显存占用:
佬友们有什么想要测评的,可以留言!
9 个帖子 - 5 位参与者