各位佬,我下载了20篇领域内的顶刊(用minerU转化为了markdown格式)然后准备让Claude code阅读、总结这些文献(主要是总结文献的故事脉络,方便之后参考借鉴这些顶刊的语言风格和叙事手法)。
效果非常好,总结的内容很准确。
但是,我很快发现不对劲了,我的usage飞快的上升,几乎几分钟就用了5h限额的一大半 ![]() (max 5x账号)
(max 5x账号)
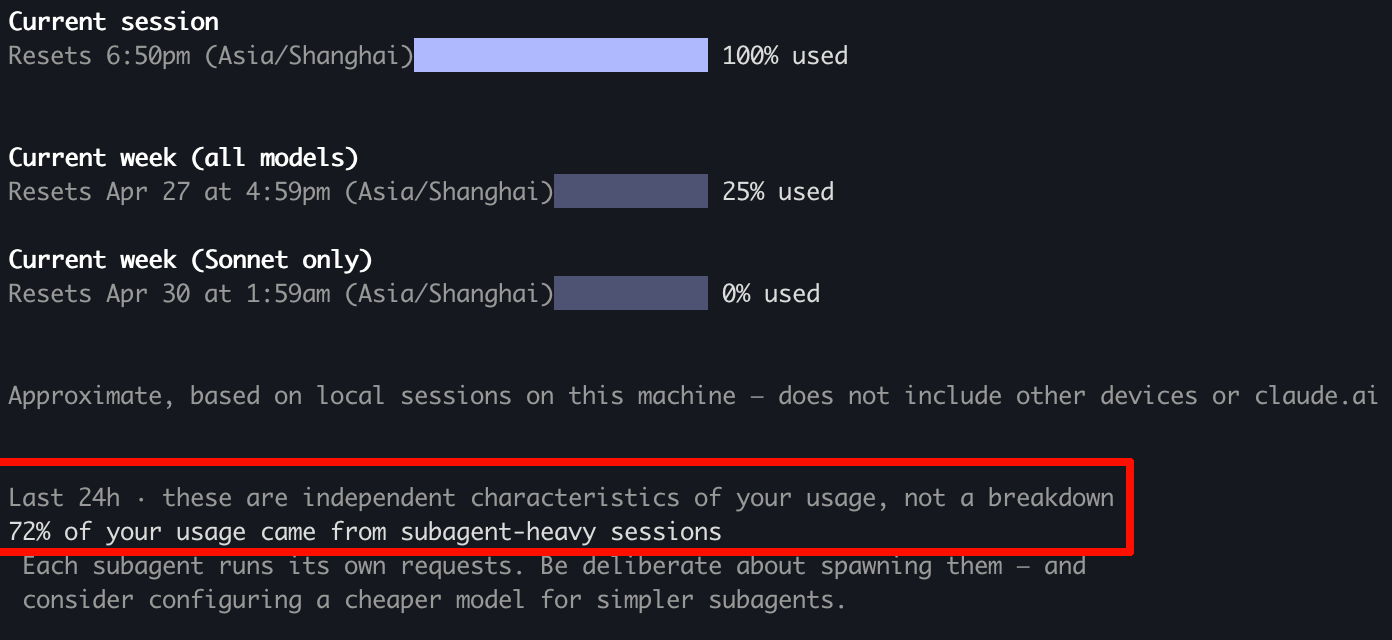
我用的是opus4.7 xhigh,感觉这次用量消耗的飞快的原因是subagent。不知道佬友们有什么好的方法来改善这个问题,sonnet的智力够吗(等我重置额度后试试)?
不知道通过cc的codex插件来节省tokens好不好用?
我的prompt如下,感觉还行,分享一下:
我在 /Users/***/Desktop/paper/references/ 下有 20 篇文献子目录,每个子目录里有原文 markdown、images。我正在把每篇文章的内容分别总结一份summary.md到对应的子目录中。
模板(需要严格对齐):以/Users/***/Desktop/paper/references/NatCommun_2025_****/summary.md(已完成的样板)为风格参照。结构是:
# 文章总结:<原文标题>
## 一、基本信息
- 期刊 / 在线日期 / DOI / 原文文件 / 核心材料 / 一句话定位
## 二、故事主线与图解读
(按原文叙事顺序。每一步叙事直接包含对应 Fig X 的 panel 级详细解读,
不要把"图解读"单独成节)
### 第一步:...
**Fig. X 解读**
- **Panel a**:方法 + 方法原理 + 关键数值 + 它在故事里推进什么
- **Panel b**:...
*Fig. X 的角色*:...
### 第二步:...
## 三、可借鉴的写法
1–2 句
要求:每个 panel 必须写清方法名 + 方法原理 + 原文实际给出的关键数值 + 在故事里承担的角色,不得编造数字;斜体 标术语/数值,粗体强调;全中文;150–300 行。
4 个帖子 - 3 位参与者
来源: linux.do查看原文