Blazing fast inference: By shifting the decode bottleneck from memory-bandwidth to compute, DiffusionGemma generates up to 4x faster token output on dedicated GPUs. (1000+ tokens per second on a single NVIDIA H100, 700+ tokens per second on NVIDIA GeForce RTX 5090).
一些补充
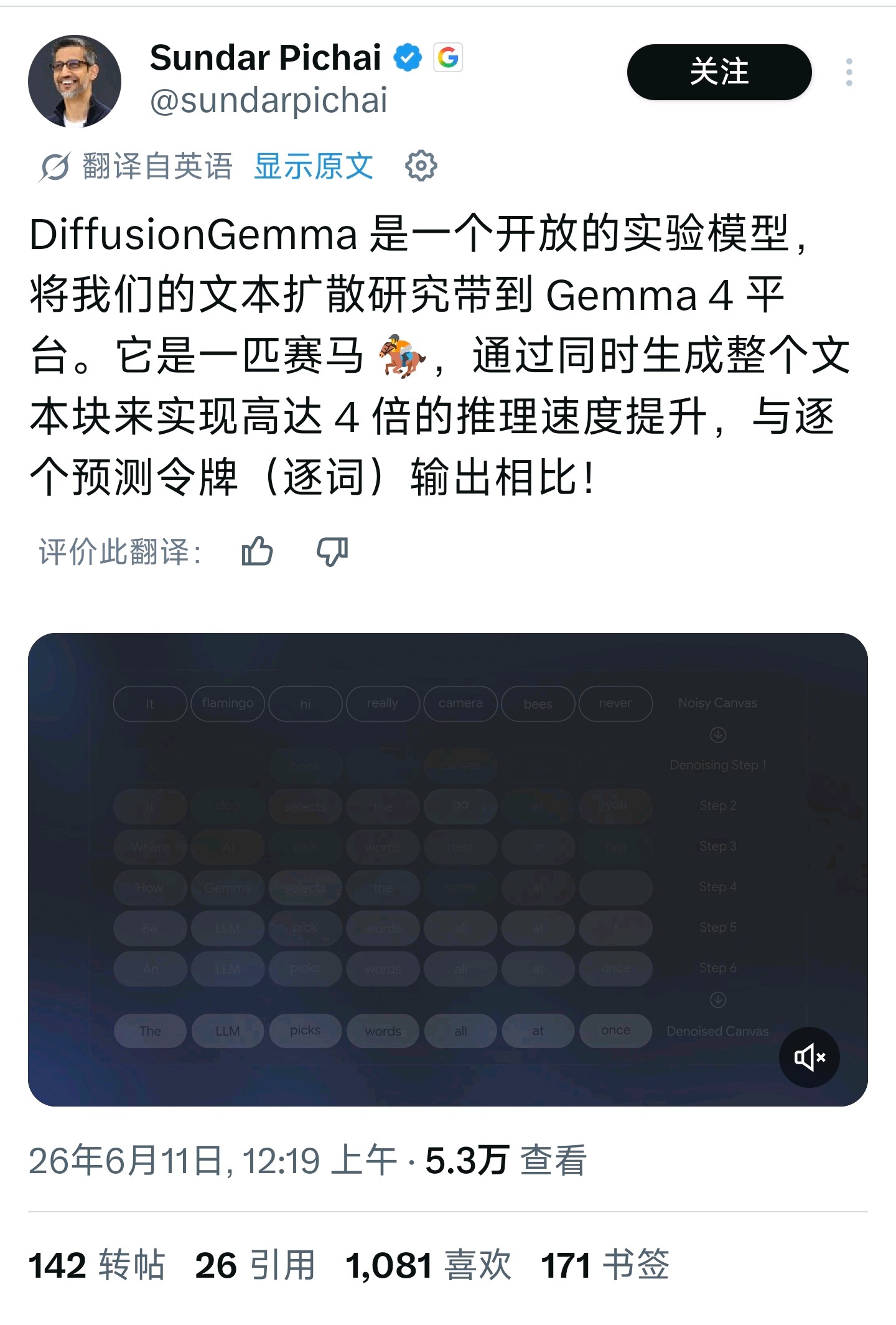
Diffusion是一种不同于主流文本大模型Next Token Predict的模型架构,常用于图片生成领域中。NTP是从左向右逐个token生成的,而Diffusion则是给定一块空白区域,模型预测这片区域的每个位置可能的内容,并一次次进行纠错,最终生成完整内容。
14 个帖子 - 9 位参与者
来源: LinuxDo 最新话题查看原文