昨天帮甲方升级了一下本地的老模型,因为本人并不是从事运维工作,只是临时补坑,还是浪费了点时间.现在回头做个梳理,希望佬友们在用得到的时候也有个参考(感觉都比较基础,专业的大佬可以跳过不看)
模型下载:国内环境推荐直接使用modelscope下载,如果是内网环境的话,可以下载完再上传到服务器.这里重点关注2个地方
-
模型选择
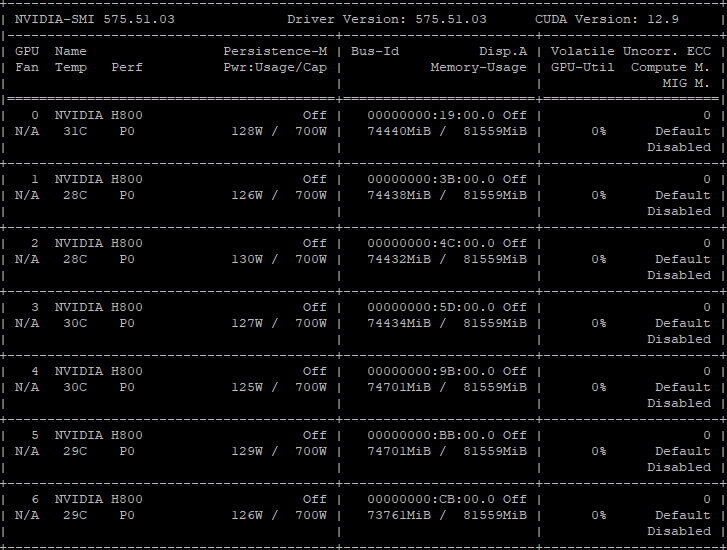
一般来说我们首先考虑显存大小,先本地使用nvidia-smi,查看本机显存
推荐阅读[分享创造] 基于 Claude Code Workflow 的 Loop Engineering 流水线 - Claude-lights-out
推荐阅读gap 了快3年,今年已过半,迷茫焦虑中,想听听过来人的建议
非量化模型可以有个简单的公式:显存 ≈ 参数量 × 2 ,然后基本上要留1/4以上余量提供给上下文kv cache,当然你如果已经安装完发现显存不够,可以通过量化参数–quantization降低显存要求
PS.这台服务器真让人流口水啊,也不用担心装不下的问题
-
模型对应的配置要求:
注意仔细阅读模型的介绍页
会有推荐的显卡,如果你的显卡等级比推荐的低,大概率就是装不了
在安装方式那里,我们会看到要求的版本,现在好像vllm部署比较多,所以我们进入模型页面对应的vllm安装方式会看到 -
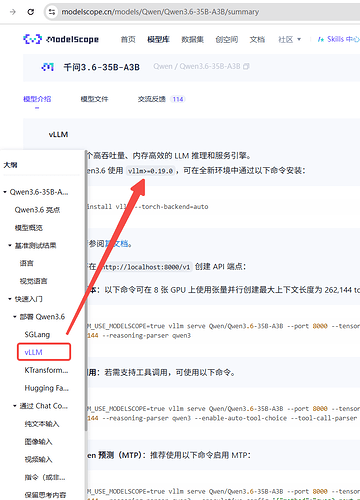

这里就有第一个踩坑的点:虽然他标注的vllm>=0.19.0,但是我建议你就安装对应的版本.我昨天按文档上的安装了最新vllm版本运行后又会出现版本兼容问题,浪费了不少时间调版本(也不知道是不是vllm高版本不向下兼容的问题,反正vllm里提示transformers版本不对,然后我就问哈基米解决方案,来回升降vllm和transformers版本,最后也解决不了,这实际部署行为,大模型可信度有限)
服务器CUDA版本升级因为服务器是N卡而且现有的服务器CUDA版本太低了,对于要求版本的vllm不兼容,所以第一步先升级cuda.
先查询你要安装的cuda版本,这里我以要装的vllm 0.19.0为例:
安装要求:
-
OS: Linux
-
Python: 3.10 到 3.13
-
NVIDIA GPU:
compute capability >= 7.0
官方依据:
- vLLM 0.19.0 GPU 安装要求:
 docs.vllm.ai
docs.vllm.ai
GPU - vLLM
- NVIDIA GPU compute capability 官方查询表:
NVIDIA CUDA GPU Compute Capability
Find the compute capability for your GPU.
这里如果显卡不满足cap的话就只能降vllm版本,装老一点的模型了
然后开始具体安装=> 前置:停掉所有占用显卡的进程,查询指令如下
nvidia-smi --query-compute-apps=pid,name --format=csv,noheader,nounits
如果是systemd启动的话可以在列表中先找到相关的服务
systemctl list-units --type=service --state=running
然后直接kill 或者使用对应的systemctl stop xxxx停止服务和nv manager服务
# 停止 Fabric Manager
systemctl unmask nvidia-fabricmanager
systemctl stop nvidia-fabricmanager
# 查询当前驱动和已安装的 fabricmanager
dpkg -l | grep -E 'nvidia-fabricmanager|nvidia-driver'
apt-mark showhold | grep -E 'nvidia|cuda' || true
# 解除旧 fabricmanager 的 hold 并卸载,我本地的是nvidia-fabricmanager-550
apt-mark unhold nvidia-fabricmanager-550 nvidia-fabricmanager-580 2>/dev/null || true
apt purge -y nvidia-fabricmanager-550 nvidia-fabricmanager-580
# 停止所有可能占用 GPU 的持久化服务
systemctl stop nvidia-persistenced
接着去NV官网下载对应的CUDA Toolkit
wget https://developer.download.nvidia.com/compute/cuda/12.9.0/local_installers/cuda_12.9.0_575.51.03_linux.run
sh cuda_12.9.0_575.51.03_linux.run
根据提示页面输入’accept’和选择install即可,等待安装完毕
安装完再系统的全局软链接更新指向新版本的 Toolkit
mv /usr/local/cuda /usr/local/cuda.bak
ln -s /usr/local/cuda-12.9 /usr/local/cuda
# 查询 NVIDIA 驱动版本,fabricmanager 要匹配驱动版本,不是 CUDA toolkit 版本
nvidia-smi --query-gpu=driver_version --format=csv,noheader | head -n 1
# 查询 575 server 驱动和 fabricmanager 可用版本
apt update
apt-cache policy nvidia-driver-575-server nvidia-fabricmanager-575
apt-cache madison nvidia-driver-575-server
apt-cache madison nvidia-fabricmanager-575
# 安装匹配版本的 server driver + fabricmanager
apt install -y nvidia-driver-575-server nvidia-fabricmanager-575
# 驱动升级后必须重启
reboot
#恢复管理器
systemctl daemon-reload
systemctl enable --now nvidia-fabricmanager
systemctl start nvidia-fabricmanager
systemctl status nvidia-fabricmanager
nvidia-smi topo -m
这里注意装完驱动必须重启服务器,然后nvidia-smi 后看到 CUDA Version: 12.9,至此cuda升级完毕
安装升级vllm因为原先这台机器的vllm并不是我来安装的,所以升级的时候,直接安装一套新的conda做虚拟环境管理
wget https://repo.anaconda.com/archive/Anaconda3-2024.10-1-Linux-x86_64.sh
chmod +x Anaconda3-2024.10-1-Linux-x86_64.sh
./Anaconda3-2024.10-1-Linux-x86_64.sh
#修改环境变量
echo 'export PATH=~/anaconda3/bin:$PATH' >> ~/.bashrc && source ~/.bashrc
conda create -n vllm python=3.10 -y
source ~/.bashrc && conda activate vllm
#安装模型要求的vllm版本,这里替换了国内源,提高下载速度
pip install vllm==0.19.0 -i https://pypi.tuna.tsinghua.edu.cn/simple
后续就是调试vllm的启动命令了,这基本参照官方文档和问ai都能搞定,无非就是配置几个选项和上下文大小和量化指标那些
6 个帖子 - 4 位参与者