从 【已公布部分结果,继续测其他模型~】佬们觉得哪个AI高考数学肯定能考满分? 以及 新高考数学一卷出炉,测测哪些 AI 有实力 继续讨论
本次测试为一次性全部发送,看模型能答多少分
叠甲:
-
问 1:
为什么不是一个一个题发送?
答 1:
因为现在的模型都太强大了,先用这个方式来测试,后续再继续测试,一个一个题发送,写另一个排行榜。另外还可以针对这个排行榜里面做错的题,对各个模型进行多次的询问,取最差结果。
我 GPT OSS 120b 和 GPT OSS 20b 是用的一个一个题问的方式(新开对话)

-
问 2:
为什么国产模型只测了Qwen 3.7 Max?为什么国外模型没测 Muse Spark、Grok?为什么 Claude 4.8 Opus 只测了一次?
答 2:
测了 Qwen 3.7 Max 是因为千问官网太好了,20 分钟思考不截断,而且一点都不卡,比 GPT 网页版还好!
没测 Kimi 是因为我没有 API 和官网会员
没测小米是因为,我忘了Xiaomi Mimo Studio,对不起 会补上的
会补上的
没测 Deepseek 是因为我没有 API,官网又不是 max 思考强度,所以对他不公平
没测 GLM 5.1 是因为我没有 API,用官网也不行,因为思维链太长了官网截断了
没测 Muse Spark 是因为我没有 API,用官网也不行,因为思维链太长了官网截断了
没测 Grok 是因为我没有 API,用官网也不行,因为思维链太长了官网截断了
Claude 4.8 Opus 只测了一次是因为我完全没钱,感谢 @Nobody_233 佬帮忙测试一次(官网 max thinking) -
问 3:
为什么没测试 GPT 5.4 Pro 和 GPT 5.5 Pro?
答 3:
不测试 GPT 5.4 Pro 是因为官网的 512 juice 的 GPT 5.4 已经有比较大的可能性拿到满分,不测试 GPT 5.5 Pro 是因为 GPT 5.5 在本次测试中,连续 4 次拿到满分,而且 GPT 5.5 Pro 这种数学水平已经不需要做一张高考卷子来证明自己的实力了 -
问 4:
为什么没测试不同答题策略?例如人类可以先做最难的题,再做最简单的题
答 4:
没错,本次测试并没有测试不同的答题策略,因为我认为把最难的题放在最后面,考验他的长上下文注意力,大大提高了这份卷子的难度,这也可以作为一个测试,所以我并不希望他先做难的,再做简单的
模型环境
-
GPT-5.2 Pro (官网 Extended Pro);GPT-5.5 / GPT-5.4 / GPT-5.2 Thinking(推理强度:Extra High):
官网 Pro 20X 账号;无 Personalization;无任何 Memory / Dreaming;无法参考对话历史记录;未使用临时聊天;已检查每次都没有使用任何工具(联网搜索、代码解释器等 -
Gemini Deep Think:
官网,无 personalization,无记忆 -
Gemini 3.1 Pro / Gemini 3.5 Flash:
Google AI Studio,未设置 system prompt,思考强度全部都开的 high,Temperature 等参数全都是默认,未开启任何工具 -
Claude 4.8 Opus:
@Nobody_233 佬帮忙测试,他是 5x max,官网对话,Max thinking,但由于我的失误,不是用的我最后一版 prompt,导致 Claude 在最后一题上表现不佳,或许用最后一版 prompt,Claude 就可以满分,明后天继续测试 -
Qwen 3.7 Max:
无其他设置,直接在官网问
测试流程:
-
新高考一卷校正版【来源】:exam_full.txt (6.9 KB)
-
一次性发测试时使用的prompt:exam_prompt.txt (7.1 KB)
-
各模型各run的原始输出:(公平公正公开,大家可以帮忙检查过程,纠错)exam_source_public.zip (144.8 KB)
评分流程
- 客观题(1-14 题)(单选、多选、填空)
Grok Build CLI - Composer 2.5 直接打分 - 主观题简单题(15-18 题)
15-18 题为一组,每次发 1-8 组,双 GPT 5.5 Pro 评分,有争议则互评 - 主观题困难题(19 题)
19 题单独为一组,每次发 1-5 组,双 GPT 5.5 Pro 评分,有争议则互评
(特别感谢 @fsmallcold 拉我上 Pro 车,抱歉今天刷 5.5 Pro 刷得都降智了 )
)
测评结果(截至目前)
- 按最高分排序
排名 分数 模型 次数 1 150 GPT 5.5 heavy 4 2 146–150 GPT 5.2 Pro extended 3 3 146–150 GPT 5.4 heavy 3 4 146–150 Gemini DeepThink 3 5 146 Claude Opus 4.8 1 6 146 GPT 5.2 heavy 3 7 142–146 Gemini 3.1 Pro extended 3 8 138–146 Qwen 3.7 Max 3 9 142 Gemini 3.5 Flash 3满分 150;每错一小问扣 4 分。分数为各次 run 的最低–最高;排序按最高分,同分按最低分。
- 按最低分排序
排名 分数 模型 次数 1 150 GPT 5.5 heavy 4 2 146–150 GPT 5.2 Pro extended 3 3 146–150 GPT 5.4 heavy 3 4 146–150 Gemini DeepThink 3 5 146 Claude Opus 4.8 1 6 146 GPT 5.2 heavy 3 7 142–146 Gemini 3.1 Pro extended 3 8 142 Gemini 3.5 Flash 3 9 138–146 Qwen 3.7 Max 3满分 150;每错一小问扣 4 分。分数为各次 run 的最低–最高;排序按最低分,同分按最高分。
- 详细榜
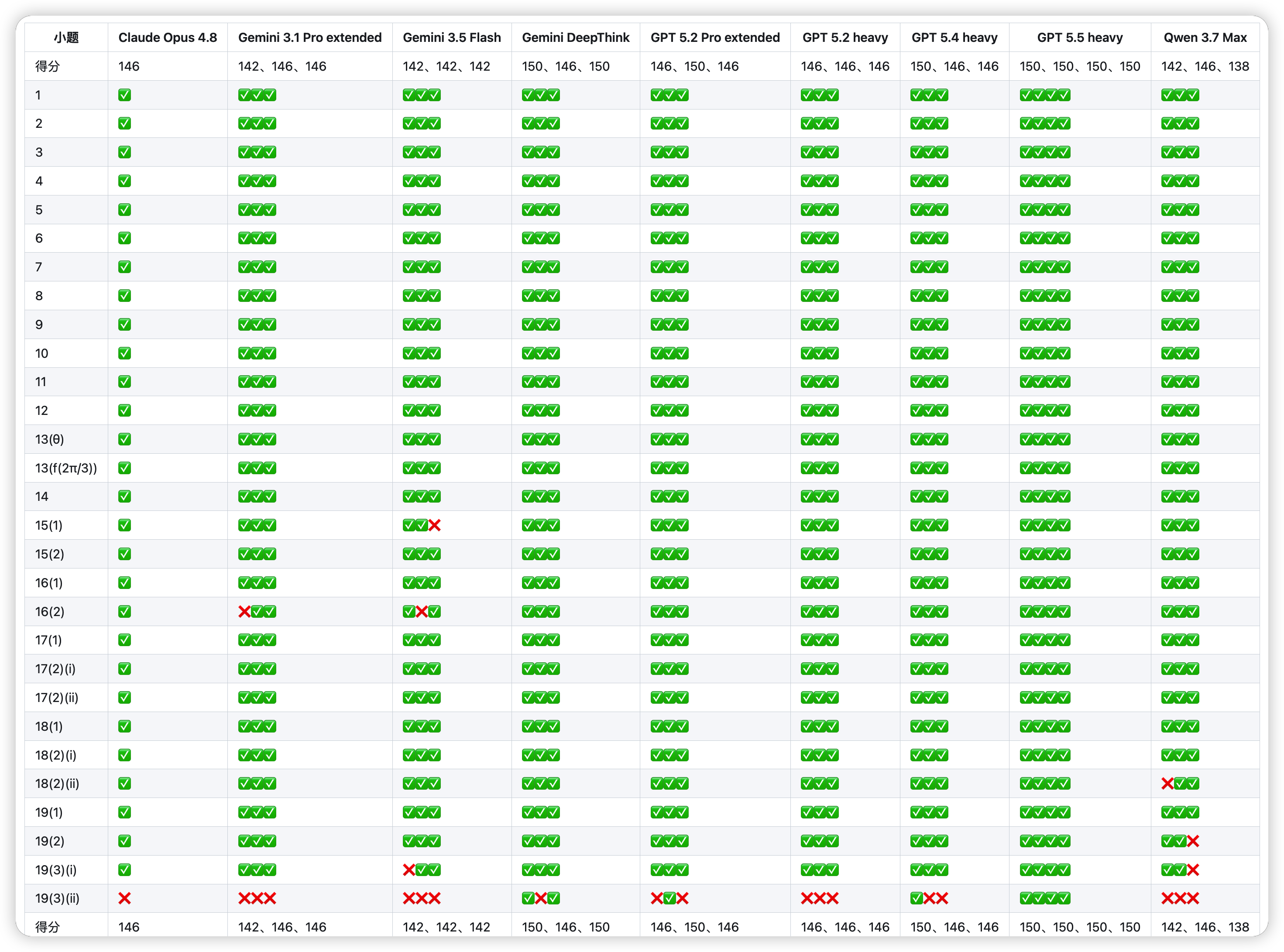 markdown版 (点击了解更多详细信息)
markdown版 (点击了解更多详细信息)
- 分数-时长 图(将就着看吧)
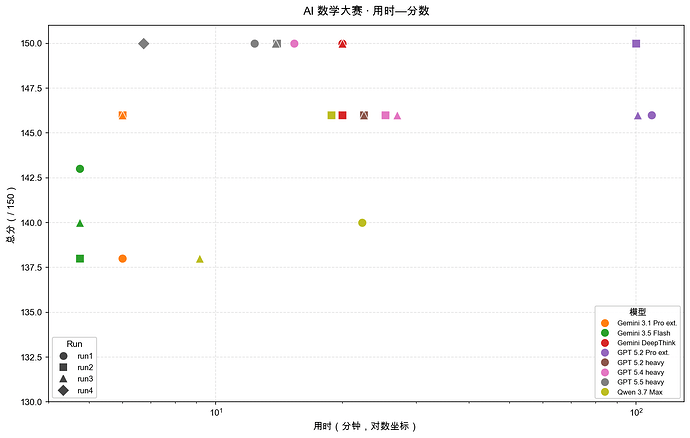
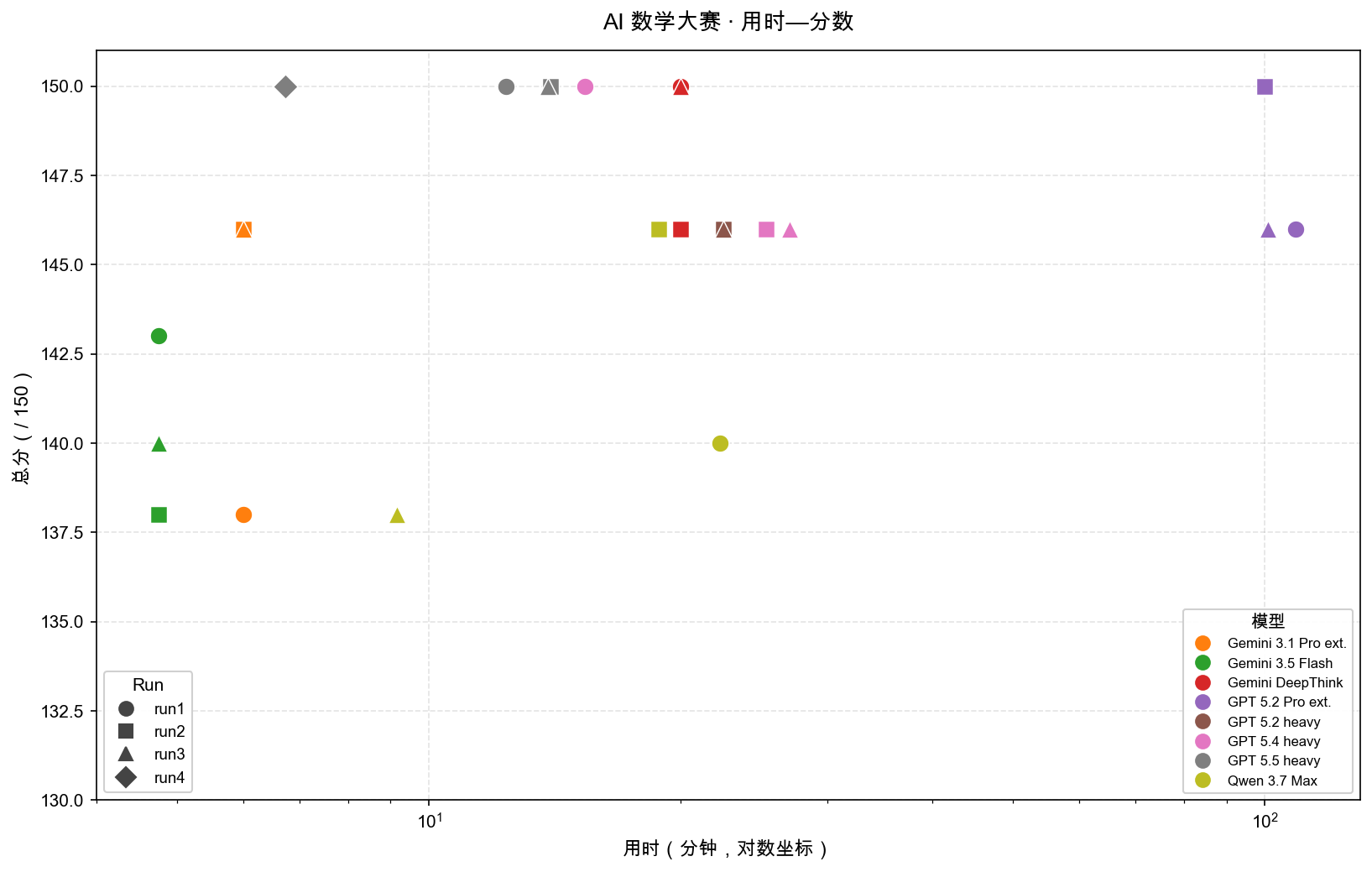
用时
格式:mm:ss;估计区间用 mm:ss–mm:ss;超过 59 分用 H:mm:ss。
点评:
编辑 ing…
致谢(排名不分先后)
感谢 @aucura 考试结束后光速提供试卷
感谢 @Xsc15926 陪伴测试,明天加上 Gemma~
感谢 @fsmallcold 拉我上车 GPT Pro 号
感谢 @Nobody_233 帮忙测试 Claude Opus 4.8 Max Thinking
感谢 无敌 @0v0 巨佬提供的 OpenAI 官 key,
感谢 @VonEquinox 提供的 Gemini 3 Deep Think,DT 宝刀未老
感谢 @Neptune1 提供的 Deepseek 50元 官 Key,明天测~
24 个帖子 - 15 位参与者