正文
很多佬友用着中转站,却不太清楚这些概念,也不知道自己买的服务质量如何、有没有被坑。这篇把几个核心指标讲清楚。
一、倍率
充值倍率:充值金额和获得额度的比例。例如充值倍率 1r:10,就是花 1r 获得 10额度。额度单位由站长设定,通常是刀(美元),部分公益站以 ldc 为单位。
分组倍率:中转站通常会按模型划分不同倍率
不同分组对应不同的倍率。
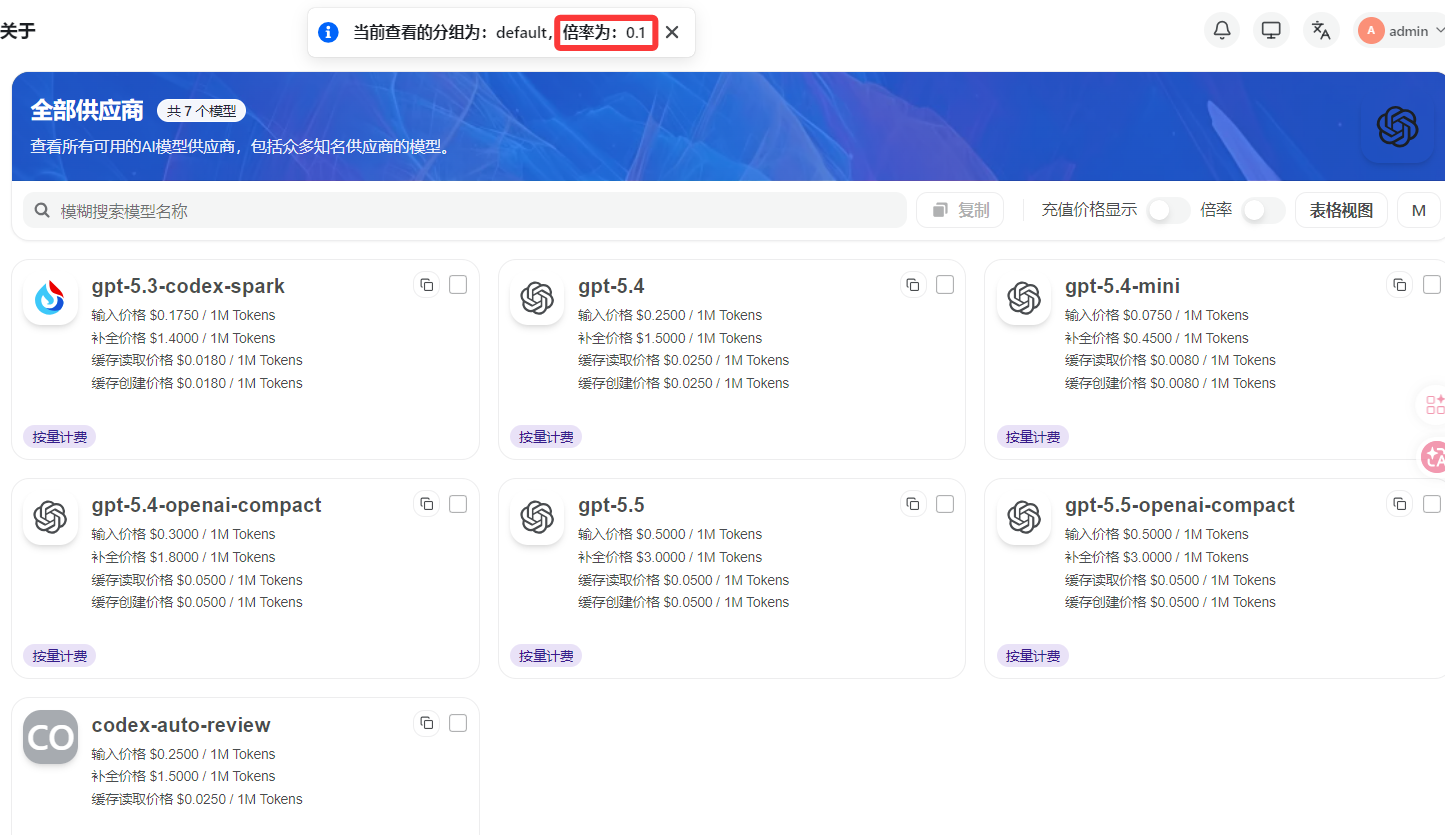
举例:某站
default 分组倍率为 0.1,那么 default 分组下所有模型都按官方价×0.1 计费。比如 gpt-5.5 官方价是输入 5、输出 30,乘以 0.1 后就是上图的输入0.5、输出 3。
搞懂倍率后,就可以对赠送的额度有直观的理解了。例如一二公益站赠送200刀额度,实际计价是按官网倍率1:1来的,和某付费站注册赠送20刀额度,分组倍率0.1,实际是一样的总额度,但是从视觉上看,感观差异就很大了。前提:这里假设该站模型的「基准价」是按官方价定的。有的站会自己抬高基准价,倍率低不代表最终便宜,详见后文。
二、首字速度与缓存
首字速度(TTFT):从你发出请求到收到回复第一个字之间的时间间隔。注意: 推理模型「思考」的时间也算在首字里——它要先想完才吐第一个字,所以推理模型的首字天然比普通模型慢。
首字快慢主要由三件事决定:
- 上游模型本身的速度:尤其推理模型要先思考,这段时间跑不掉;
- 中转到上游(OpenAI/CLAUDE/GEMINI等)的网络距离和线路质量:服务器离上游越近、线路越优,每次往返越快——这是中转能优化的主要部分;
- 服务器是否过载:高峰期 CPU 被打满会明显拖慢首字。

常见误区:很多人以为「出口带宽大(1G/10G)首字就快」。其实带宽和首字延迟是两回事。带宽决定的是「能同时扛多少请求、传大数据快不快」(吞吐量),首字是「 延迟」,取决于线路往返和上游速度。带宽只有在高并发把链路打满时才会间接拖慢延迟— —平时堆带宽并不会让单次首字更快。带宽的真正价值在下面的 RPM 部分(扛并发)。
缓存:指「提示词缓存」(prompt caching)——把重复的输入前缀缓存下来,命中的输入token 按更低价计费(通常约为原价的 1/10)。所以系统提示词固定、多轮对话等场景,缓存命中率越高越省。前面的价格表里就有缓存价一列。
三、RPM
RPM(Requests Per Minute):每分钟请求数。
- 个人使用一般 RPM 都小于 10。
- 这个指标主要反映中转的承载能力:服务器和上游账号池越大,能扛的 RPM 越高。
- 一个付费站如果日常 RPM 能稳定上千,规模就不小了(不过 RPM还和客户活跃度有关,不能简单换算成具体客户数)。
四、怎么判断自己有没有被坑?
1. 先把各级倍率和价格算清楚。
真实花费要把「充值比例」和「模型/分组倍率」一起算,不能只看倍率低就以为便宜:
- 有的站倍率低,但充值比例坑,或者把模型基准价抬高了;
- 综合折扣 ≈ 官方价 × 倍率 ÷ 充值比例。
举例:充值 1:1、倍率 0.2、模型按官方价——实际只花官方价的0.2,相当于比直接用官方 API 便宜约 5 倍。
2. 最影响体验的是首字速度。
首字是最能直接感知的指标——问个问题,模型老半天才回,体验就很糟。简单请求、线路好的大站能做到 1–2s,甚至1s内。但推理模型、长上下文请求,首字2–5s 都算正常,这跟上游和请求大小有关。
3. 低价站靠不靠谱。
如果看到一个倍率低得离谱的中转站,就要想想它能扛多少RPM。一旦请求量超过服务器上限,CPU被打满,首字会爆慢,发个「hi」可能要等很久才回。所以很多中转站会限制并发,本质就是压RPM。而个人用 AI 经常会开多个窗口同时跑,如果并发限制太狠,用起来也难受。这是低价和体验之间的取舍,挑站时值得留意。
声明:内容均由本人亲自编写,ai用于矫正markdown格式,方便佬友阅读。
4 个帖子 - 4 位参与者