开始
不知道大家有没有玩过文明6、红警、铁锈战争、Unciv、骑砍这类游戏,反正我小时候很喜欢玩哈哈,初中时还组过战队打比赛来着。有一天我在刷ByteTech时见到了一个关于AI小镇的文章,当时就想着能不能把AI接入到游戏里,使游戏里的每个单位都有自己的想法,自己行动,自己生存,于是,便有了这个游戏。
体验地址:qx.wuname.eu.org(用了cloudflare家的cdn,如果感觉很慢可以打开科学上网)
一些截图
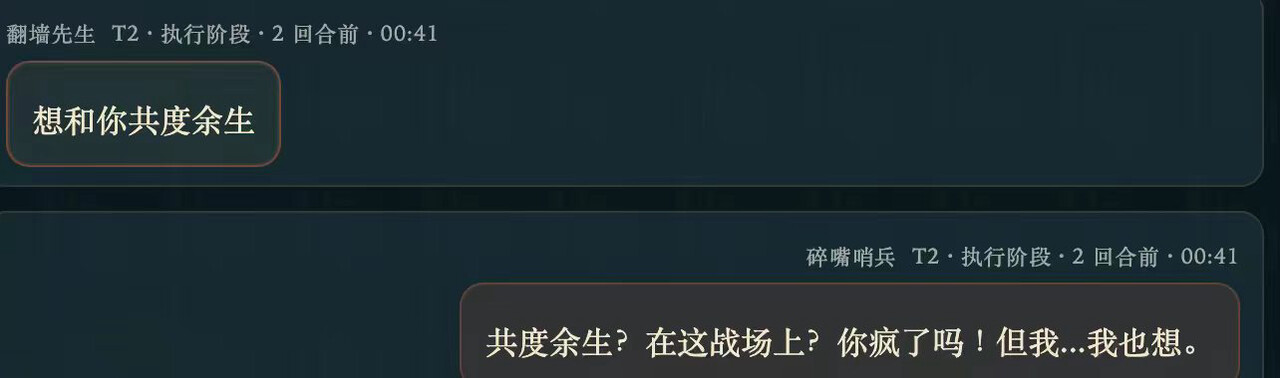
没错,AI也会谈恋爱,并且可以生孩子(生的孩子自动加入己方阵营)。

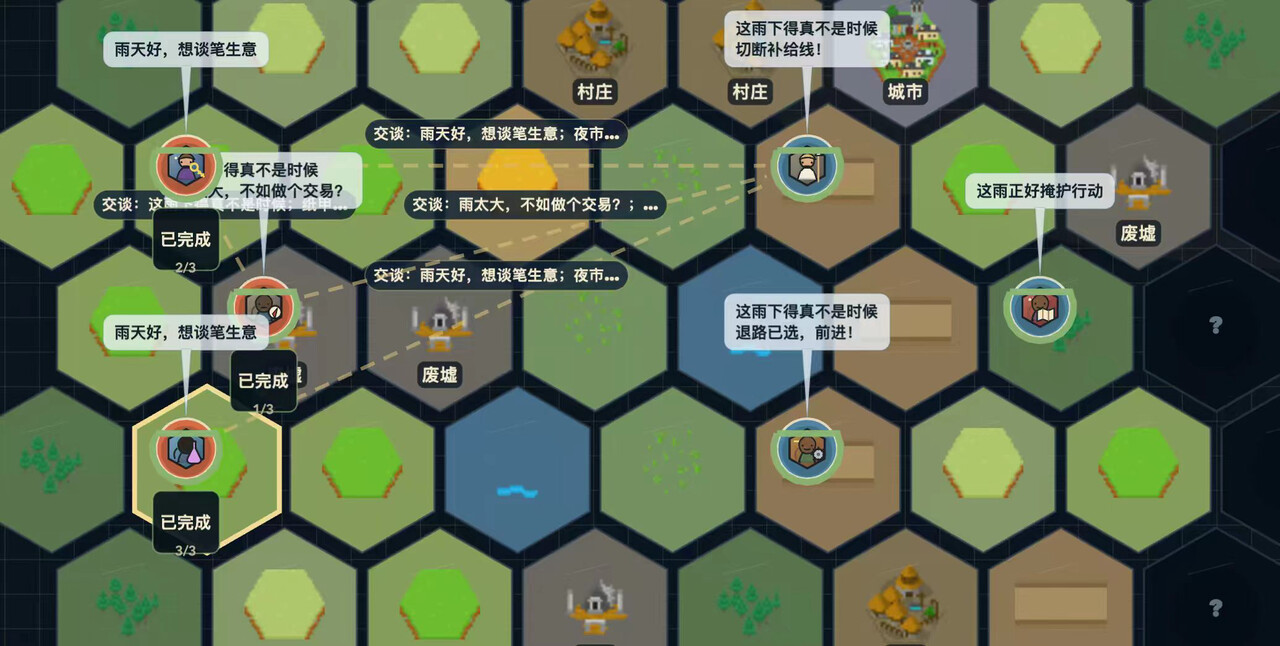
没错,AI也可以交易和赠予物品。

没错,AI也会打猎和建造建筑以及吃饭。
架构玩法介绍
实现很简单,就是一股脑把周围环境信息、记忆、这个世界的规则、玩家给的方针、能选择的动作都喂给大模型,最后大模型给出最合理的动作。
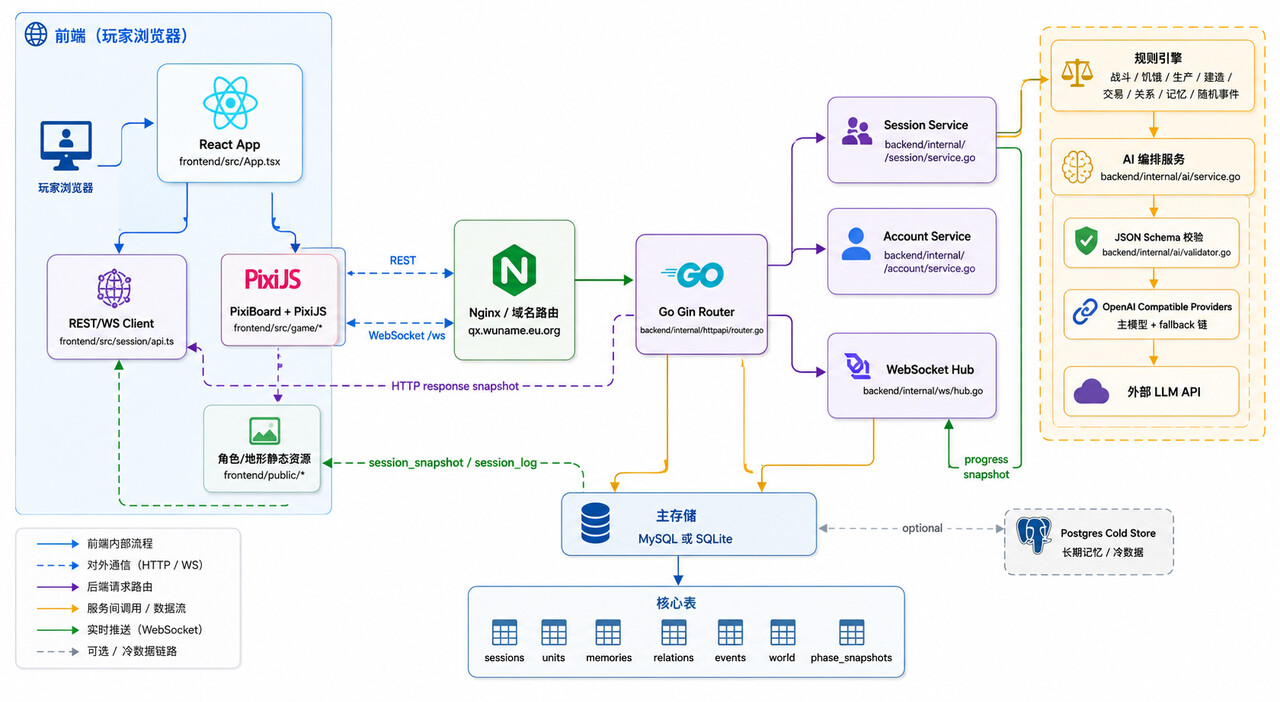
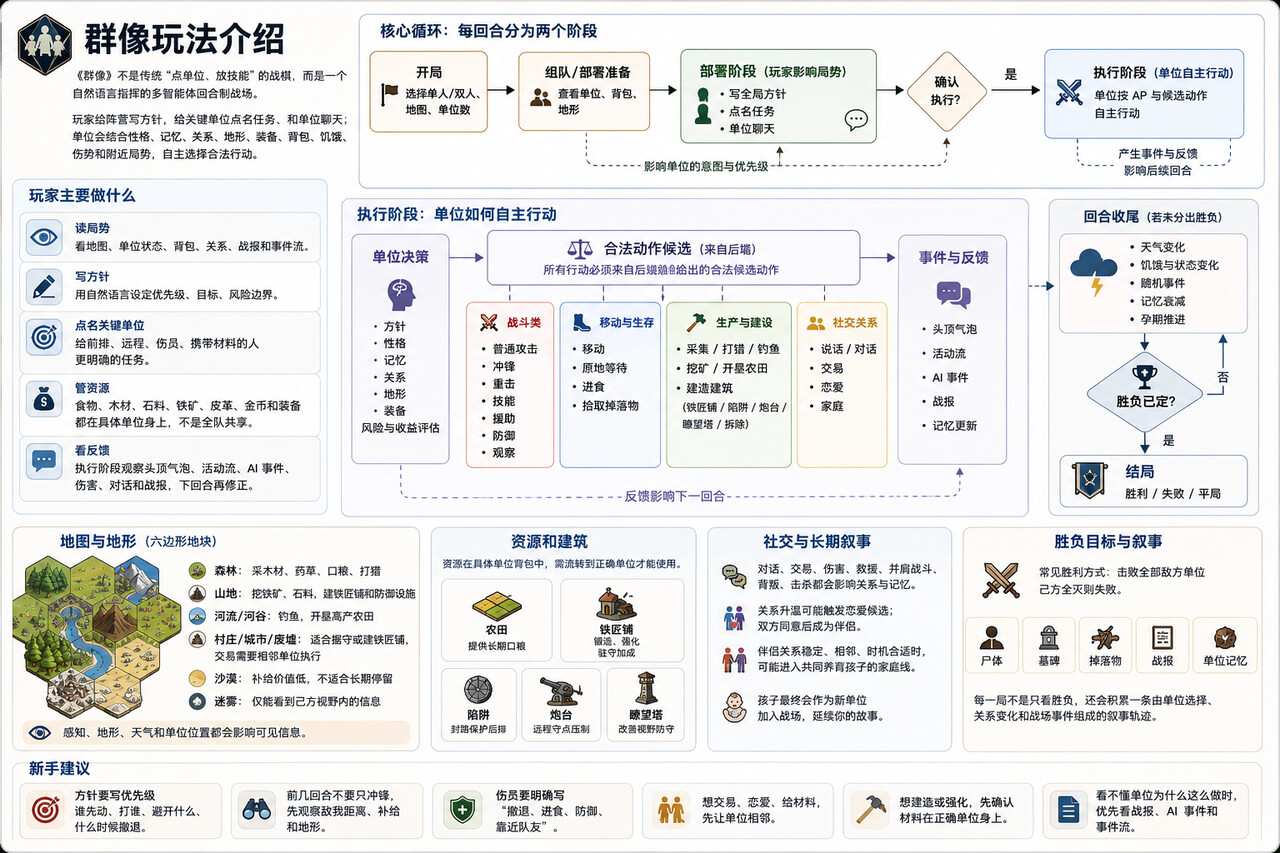
ATB + AP:让执行阶段既有顺序又有节奏
这是一个战旗类的游戏,AI行动肯定要有个行动顺序
单位行动顺序不是简单轮流,而是类似 ATB 的行动条模型。速度受多种因素影响:
-
基础机动能力;
-
装备修正;
-
人格倾向,例如勇气、攻击性、审慎;
-
饥饿、疲劳、受伤、士气等状态;
-
当前任务偏置;
-
连续同阵营行动的平衡惩罚。
每个单位在执行阶段有 AP。攻击、移动、观察、防御、生产、建造、强化、交易等动作消耗不同 AP。饥饿和疲劳会压缩行动能力。
AI 决策:把模型关进合法动作空间
我的做法是把 AI 决策拆成四层:
服务端生成候选动作
↓
LLM 在候选空间里选择
↓
结构化 Schema 校验
↓
业务规则二次裁决
↓
执行器修改世界状态
先枚举候选,再让模型选择
单位行动前,服务端会基于真实世界状态生成动作候选,例如:
-
可以移动到哪些相邻格;
-
可以攻击哪些敌人;
-
可以观察、防御、撤退;
-
可以吃什么、喝什么、捡什么;
-
可以和谁交谈、交易、表白、救援;
-
可以在哪些地形上采集、狩猎、钓鱼、采矿;
-
可以建造、拆除、收获哪些设施;
-
如果没有好动作,至少可以 hold 或 observe。
LLM 看到的不是一个无限开放世界,而是一个经过服务端裁剪的合法动作空间。
这件事非常关键:不要用 prompt 请求模型遵守规则,要用程序把非法动作从动作空间里删掉。
Prompt 模板:不是把世界一股脑喂给模型
单位决策 Prompt 的核心不是"描述得越多越好",而是把信息分层、裁剪、结构化。当前模板大致分成这些块:
单位决策提示词版本: action_params_v4
当前回合 / 当前阶段 / 本次可用 AP
MOVE 坐标白名单:只列本回合真正可到达的空地
阵营自然语言方针上下文:全局方针 + 单位任务 + 即时令
单位资料:属性、HP、饥饿、背包、装备、位置、阵营
单位人格:勇气、忠诚、攻击性、审慎、社交、稳定等
记忆摘要:近期事件 + 长期摘要 + 闪回记忆
关系网:对附近单位的信任、亲密、恐惧、竞争等
世界知识:这个单位已经学到的地形/资源/敌情规律
环境摘要:脚下地形、设施、天气、最近威胁、可见友军/敌军
合法候选动作列表:attack/move/trade/build/dialogue/hold...
参数填写规则:每类 action 能填哪些字段,哪些字段必须为空
决策流程:先确认合法动作,再理解方针,再按风险排序,最后输出 JSON
其中几个设计点很关键:
-
环境信息只给局部和摘要:地图不会整张展开,而是给"视野内地形"“最近敌军距离”“本回合可到达地块”"脚下可做事项"等压缩信息。
-
记忆不是全量聊天记录:短期记忆保留事件粒度,长期记忆用摘要;再加上关系、世界知识和闪回召回。
-
动作空间是结构化枚举:模型不是自由写动作,而是在服务端生成的候选动作中选。
-
玩家方针是强信号,不是硬 RPC:Prompt 会明确注入方针和任务,但后续还有服从度、风险和合法性裁决。
对应的核心构造代码可以压缩成下面这个片段:
输出解析:JSON Schema + 业务校验 + 兜底动作
当前没有用正则解析自然语言,也没有让模型直接调用游戏函数。LLM 走的是结构化 JSON:
-
服务端根据候选动作动态生成 JSON Schema;
-
Provider 使用 OpenAI-compatible 的结构化输出能力;
-
返回后先做 JSON Schema 校验;
-
再把 choice 映射回候选动作;
-
最后用业务规则重新校验;
-
失败时降级为保守动作,例如 hold、observe 或 confused decision。
动态 Schema 的重点是:action 是当前候选动作枚举,move 坐标用 const 限死到合法坐标。
执行入口也保持这条边界:模型只产出 unitDecisionPayload,真正落地必须经过 validateDecision 和 executeDecision。
记忆系统:角色连续性的底层设施
LLM NPC 最大的问题不是不聪明,而是容易"无历史"。
如果一个角色刚被队友救过,下一回合却完全忘了这件事,那它就只是一个会说话的状态机。反过来,如果把所有历史都塞进 prompt,又会造成上下文爆炸、成本上升、响应变慢。
所以记忆系统要解决的不是"多记一点",而是:
记住值得记住的,忘掉应该忘掉的,并在相似情境下想起来。
结构化记忆,而不是聊天记录数组
记忆被分成多个类别:
-
实体记忆:我认识谁,他做过什么;
-
空间记忆:哪里危险,哪里有资源;
-
关系记忆:谁救过我,谁背叛过我;
-
事件记忆:一次战斗、一次受伤、一次交易;
-
世界知识:阵营、地形、敌人动向;
-
长期摘要:跨多个回合压缩后的生平片段。
每条记忆都有重要性、情绪权重、显著度、是否永久、来源和发生回合。
显著度、遗忘和闪回
记忆会随时间衰减,但不是线性消失。重要事件、强情绪事件、关系事件会保留更久。当前环境如果和历史事件相似,还会触发"闪回"。
例如:
-
单位再次进入曾经被伏击的森林;
-
附近出现曾经伤害过它的人;
-
天气、地形、敌人组合与某段痛苦记忆高度相似。
这类记忆会被重新召回,并进入本次决策上下文。
这比"最近 N 条聊天记录"更接近角色认知:人不是机械回放全部历史,而是在处境相似时想起关键片段。
短期事件 + 长期摘要
长期对局里,事件会越来越多。系统会把较旧的记忆压缩成长期摘要,保留角色人生轨迹,而不是保留每个细节。
所以记忆分两种粒度:
短期:事件粒度,适合即时决策
长期:摘要粒度,适合人格连续性
这也是控制 LLM 成本的关键。
恋爱与家庭:关系不是玩家按钮,而是双方同意
恋爱系统没有把"结婚"做成玩家直接触发的按钮。触发条件分为三层:
-
前置关系:两名单位必须有多轮真实对话,并且双方关系都达到熟悉阈值;
-
提议判断:LLM 同时扮演双方,判断是否有人主动提出确认亲密关系;
-
双方同意:只有双方都真心同意,关系才成立。
Prompt 里不会直接写一个"好感度=80 可以结婚"的硬规则,而是把关系摘要、对话历史、性格、阵营压力和最近事件放进上下文。好感度在规则层表现为 relationTier、互相信任/亲密等关系状态;LLM 负责把这些状态翻译成当下是否愿意推进关系。
孩子出生也不是纯随机。名字、生平和人格向量由 LLM 根据父母资料生成,但人格会经过规则层归一化;如果模型失败,则使用规则 fallback。孩子的基础人格是父母人格均值与一个确定性随机人格混合:
这个设计避免了两个问题:玩家不能强迫单位恋爱;模型也不能凭一句浪漫台词绕过双方同意和关系门槛。
贸易:等价交换靠候选生成和同意校验
贸易系统的核心不是让模型"理解经济学",而是让服务端先生成可交易候选:谁有物品、谁有钱、距离是否相邻、物品基础价值是多少、能否赠与/售卖/调拨金币。模型只能在这些候选里选择。
执行时,交易接收方还会单独做一次同意判断。这个 Prompt 明确要求目标单位只代表自己判断,可以因为敌我关系、风险、战略价值、补给不足或不信任而拒绝。
所以"会不会亏本买卖"的答案是:系统允许单位因为关系、救急或战略需要做非等价交换,但不会让模型凭空创建交易;接收方可以拒绝,失败或格式异常也默认拒绝。经济公平由候选价格、背包/钱包校验和双方同意共同约束。
总结感想
这里写一些最近开发的感想吧。似乎将AI接入游戏的落地还很少,但我觉得如果真的落地了我觉得现在的游戏将会更加有意思,毕竟谁不想和一个活生生的,会自己思考的AI、NPC打交道呢。
这仅仅是一个Demo,后续有时间我也会继续迭代的。加入更多的规则和玩法,让AI持续去探索,我觉得这样这个游戏将会越来越有趣,比如增加更多的建筑,更多的事件,甚至将每个单位的智商属性和使用的大模型进行挂钩,智商属性越高的AI越聪明,对记忆系统进行优化等等,我相信如今大模型的能力也能够驾驭得了这么多的输入。
我也觉得如今AI大模型的发达,可能更利好于个人开发者,其一呢个人开发者往往使用的是很通用的技术,而不是像企业一样有繁琐的流程、各种基建。AI训练的语料也都是最直接、原始的方式,所以个人开发者的技术栈与预训练语料天然对齐,而企业往往需要一套封装。比如一般个人开发者上线是直接使用Linux命令、docker,而企业往往都会自建一套自己的流程和平台,这次游戏还有以前我做的个人项目上线往往都是让AI自己开发完成就自己上线了,但是在企业想做到这一步可能还得投入不少的人力成本来训练AI。其二呢AI 把过去个人开发者必须外包的设计、文案等职能内化到一人手中,让 “一人公司” 第一次具备商业可行性。比如这次游戏的一些设计、文案都是由AI设计的(也抄了不少Unciv的)。
标题中的三天,其实是断断续续加起来的三天。放在三年前,我相信随便拉一个编程高手,或者拉一个经验丰富,合作默契的团队,三天肯定是做不出这样一个玩意的,即使是一个demo,可能三周还差不多?
但是现在,仅仅是我这样一个还没毕业的菜鸟,只花了三天时间做出来了。可以见到AI对咱们的提效是多么巨大。不仅仅是软件行业,在各行各业,我觉得AI的冲击都将会更加猛烈。
从chatgpt2022年出来,那时我好像还高中来着,那时借助AI编程的方式是把代码粘贴到聊天框里,然后他吐出来我再粘回去。到2024用的copilot,就是根据上下文自动提示代码,然后tab补全。2025用的是cursor,就能够读取项目下的所有代码,然后根据提示词自己写代码了。到如今的codex,claudecode,和cursor的区别,就是直接把看代码的地方扣掉了。AI在编程落地的方式突飞猛进,在其他领域的发展我也相信也会这样突飞猛进。
有了AI的帮助,我相信人类能离理想中的乌托邦更进一步。
6 个帖子 - 3 位参与者