论文:[2605.27922] Harness-Bench: Measuring Harness Effects across Models in Realistic Agent Workflows
代码:GitHub - Qihoo360/harness-bench · GitHub
 harness-bench.ai
harness-bench.ai
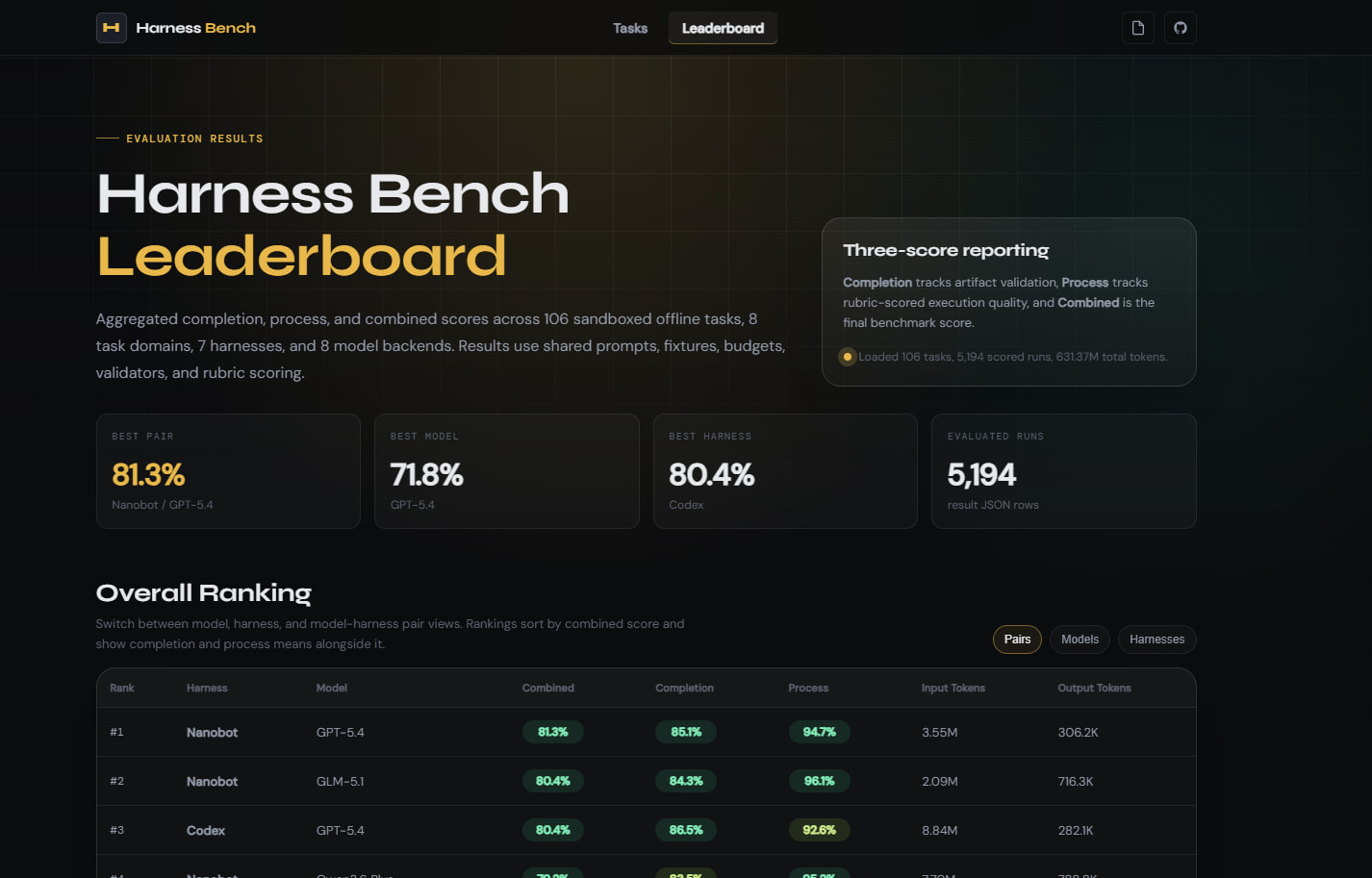
Leaderboard - Harness Bench
Harness Bench leaderboard across harnesses, models, domains, and completion, process, and combined task scores.
harness bench 简单来说就是固定任务和模型,只换harness,看agent表现差多少。
方法
106个沙箱化离线任务,8个类别(SWE、数据分析、DevOps、长程状态维护等),每个任务有独立的oracle grader。
评估维度有completion score 、LLM judge score 和security score。
测了6个现在比较火的agent(OpenClaw、nanobot、Hermes、ZeroClaw、NullClaw、Moltis) 8个模型后端(gpt-5.4、claude-opus-4.6、claude-sonnet-4.6、gemini-3.1-pro-preview、qwen3.6-plus、glm-5.1、kimi-k2.5、deepseek-v4-flash),总共5194条execution trajectories。
几个关键结论
同模型换框架,综合分最大差距23.8分(nanobot 76.2 vs OpenClaw 52.4)。说明agent benchmark只报模型得分而不报框架配置是不够的。
Failure mode分析(Table 3)比较有参考价值:36.4%的失败是contract/format类,即agent产出了内容但格式不满足验证条件;24.6%是tool/recovery类,即工具调用出错后没能恢复。真正的推理错误只占一小部分。对框架设计的启示:容错和输出校验比堆模型能力更影响实际成功率。
强模型(gpt-5.4、claude-opus-4.6)跨harness的方差更小,中等模型对harness质量更敏感。好的harness能显著拉高中等模型的上限。
Token效率方面差异显著,同样任务不同harness消耗的token能差3-4倍,主要取决于上下文构建策略。
局限
全部是离线沙箱任务,没有在线服务、用户交互、长期记忆场景。LLM judge score 依赖LLM judge,引入了评估方的主观性。只测了配置级差异,没有因果分解。
Section 5提出的execution-alignment概念值得注意:框架的核心价值在于维持agent推理、workspace实际状态、工具返回结果、最终验证条件之间的对应关系,大多数失败的根本原因不是模型推理出错,而是agent的内部判断和外部实际状态脱节了,比如以为文件改对了其实没改,以为命令成功了其实报错了。
1 个帖子 - 1 位参与者