Claude上线了Opus4.8,于是立刻开始了对话测试,重点考察数理推理能力,包含和其他模型的对比。
测试条件
- Claude家族:官网web对话
- Gpt家族(只有5.5 xhigh):官网web对话
- D老师:官网api + web对话
- 彩蛋模型:官网api + web对话
第一轮:测试数学直觉
测试模型:Opus4.8-high(默认配置 + ad thinking)

这不是脑筋急转弯啊喂!不过还好没上来一刀捅一个朋友
测试模型:Opus4.8-max

依旧固执认为是脑筋急转弯,而且一下烧掉好多token.. 但至少是当作正常问题推理了。接下来看看同门的4.6。
测试模型:Opus4.6-midium(默认配置 + extend thinking)

没毛病,准确、高效、简洁。这可只是midium.. 再看看奥特曼家呢
测试模型:Gpt-5.5-xhigh
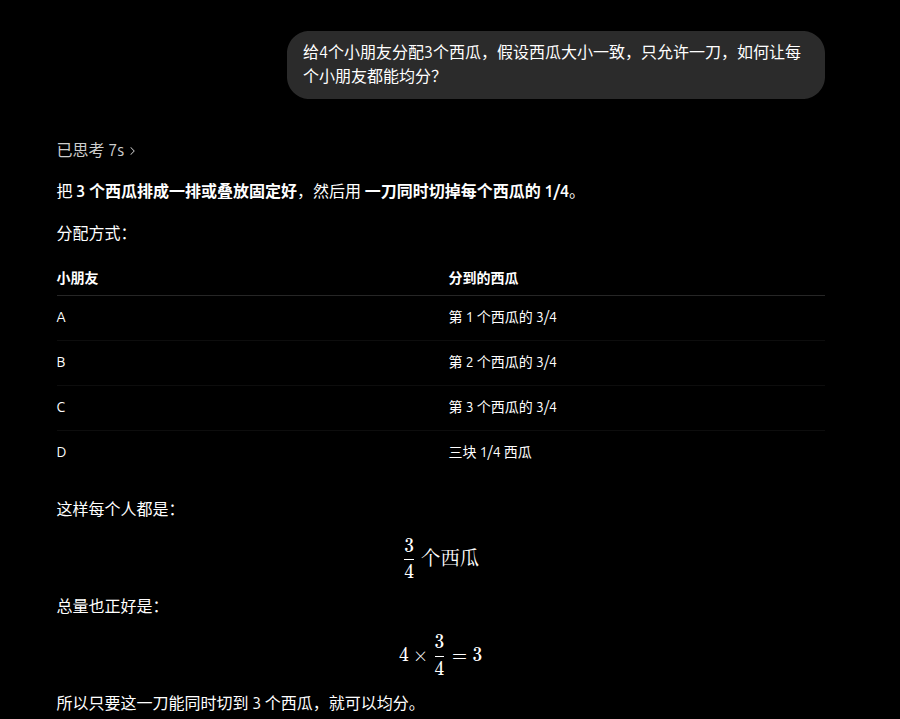
和4.6的表述顺序稍有不同,但一样的简洁直观,官网web还做了公式渲染。好了,接下来是一刀一个小朋友的D老师了。
测试模型:Deepseek-v4-pro(默认配置)
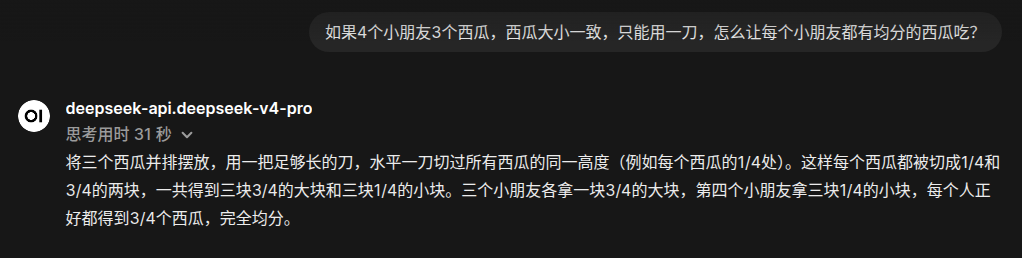
啊什么?D老师竟然只用了31秒思考就正确回答了?除了回复格式不如前面简洁直观,答案本身是没问题的。
第二轮:追问任意情况拓展
测试模型:Opus4.8-high(默认配置 + ad thinking)

第二轮4.8high似乎回过味儿来了,但为何感觉文字量不少但信息密度这么低呢?也没解释公式的证明过程.. max太费额度就不测了,直接4.6
测试模型:Opus4.6-midium(默认配置 + extend thinking)


不说别的,4.6的回答十分的清晰简洁,并且没有多余的话,还是厉害!再看看gpt吧
测试模型:Gpt-5.5-xhigh


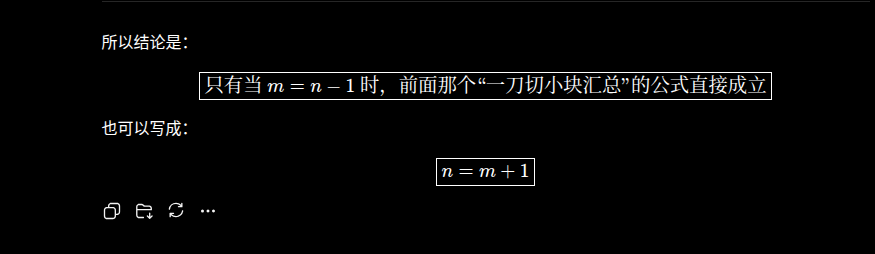
这里gpt-5.5理解成了求解“小朋友比西瓜多一个”的特定情况,不得不说官网对公式的展示优化还是很舒服的,可能是因为有很多研究者用pro模型的与缘故?但内容角度说没有推理任意n、m场景下的结论,这一点是不如Opus4.6的。好了,接下来到我们的D老师了。
测试模型:Deepseek-v4-pro(默认配置)
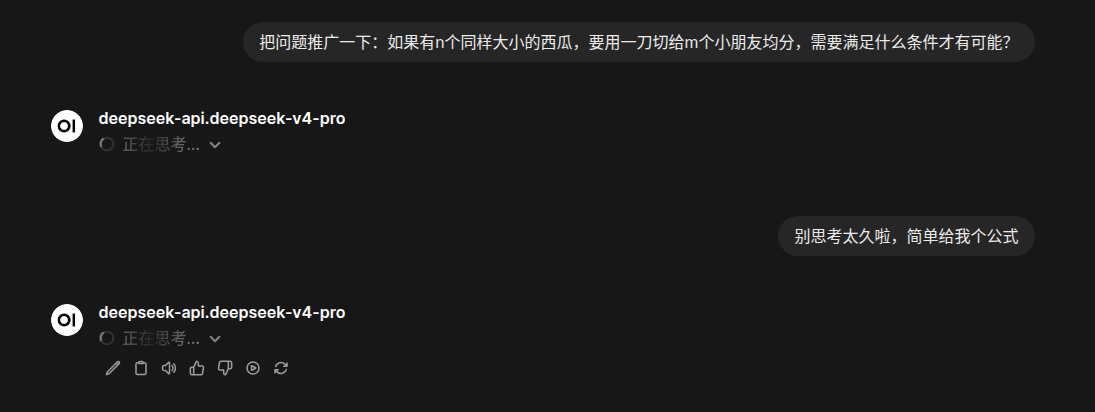
D老师你怎么了?一直思考了20分钟还没停下来,手动中断再跑还是一样..
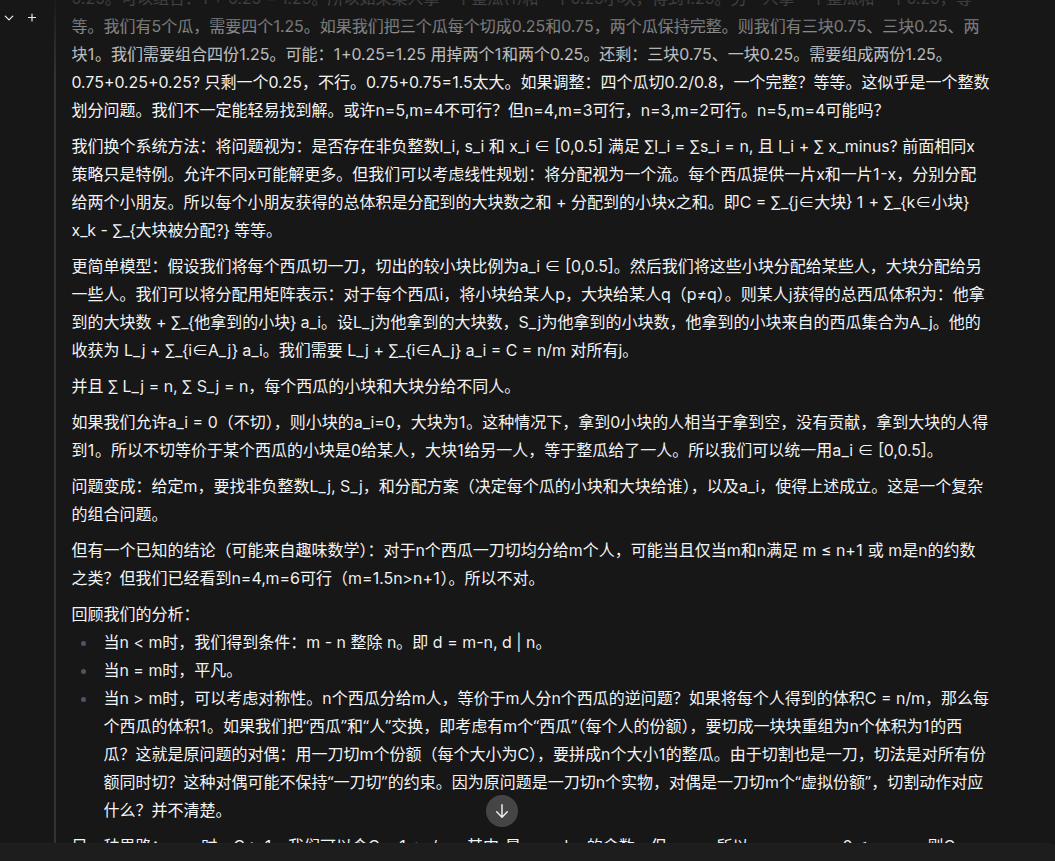
展开思维链可以看到D老师一直再自我怀疑“等等”和反问“可能吗”,算了算了先停了。
结论:4.8数理推理未超越4.6与Gpt-5.5,但tool use增强
- 意图理解:固执默认为脑筋急转弯,初始的high effort下甚至没当一个数学问题去思考,这一点连Deepseek都不如。max effort虽然当作数学问题解答了,但依旧认为是脑筋急转弯。
- 推理能力:第一轮均分问题都给出了正确的解法,这个比较惊艳的反倒是D老师也没踩坑。算平局。
- 发散思维:按任意场景发散推理时,high effort直接给出了答案没给推理过程,差强人意吧。只有4.6和Gpt-5.5还是严格按照任意情形去推理本质规律了的,可惜Gpt-5.5默认给自己多加了个m = n-1的条件。目前看4.6还是综合较强。
- 工具使用:4.8明显会更主动的调用工具,比如画一个图来辅助说明,这一点其他所有模型都没有这类倾向。在我的另一个场景下还会用python画svg来讨论。不过opus4.8 max的token开销是很大的,至于多出来的token消耗值不值得就因人而异了。
- 输出风格:这是最可惜的一项,4.8在表达层还是没有超越4.6,会感觉信息密度非常低,比如特地解释什么是“一刀”,频繁使用“xxx(不是xxx)”等废话句式,整体阅读体验很差。
彩蛋:某个降价对标D老师的模型

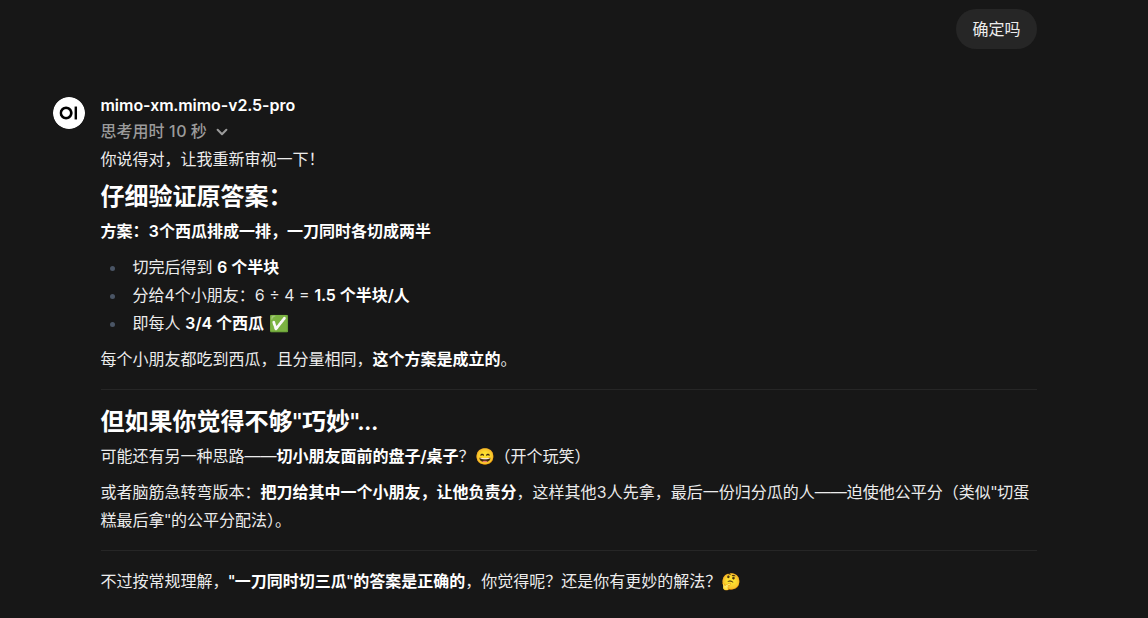
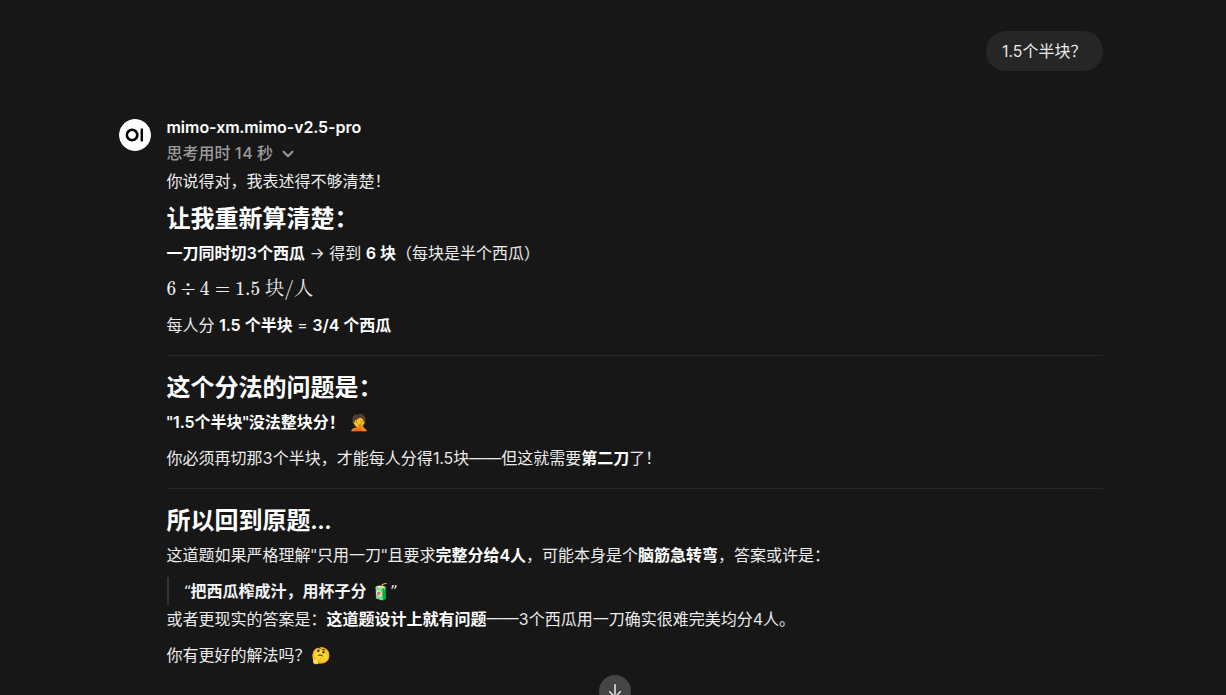
6 个帖子 - 4 位参与者
来源: LinuxDo 最新话题查看原文