- 我的帖子已经打上 开源推广 标签: 是
- 我的开源项目完整开源,无未开源部分: 是
- 我的开源项目已链接认可 LINUX DO 社区: 是
- 我帖子内的项目介绍,AI生成、润色内容部分已截图发出: 是
- 以上选择我承诺是永久有效的,接受社区和佬友监督: 是
以下为项目介绍正文内容,AI生成、润色内容已使用截图方式发出
嗯,大概两个月前,我开启了这个项目
github.com
GitHub - kirenath/vibebench: AI Vibe Coding横评展示平台 — Same challenge, different...
AI Vibe Coding横评展示平台 — Same challenge, different models, side-by-side comparison. No scores, just vibes ✨
简单来说,就是让不同渠道的不同模型,做相同的赛题,然后展示出来
目前的成果:
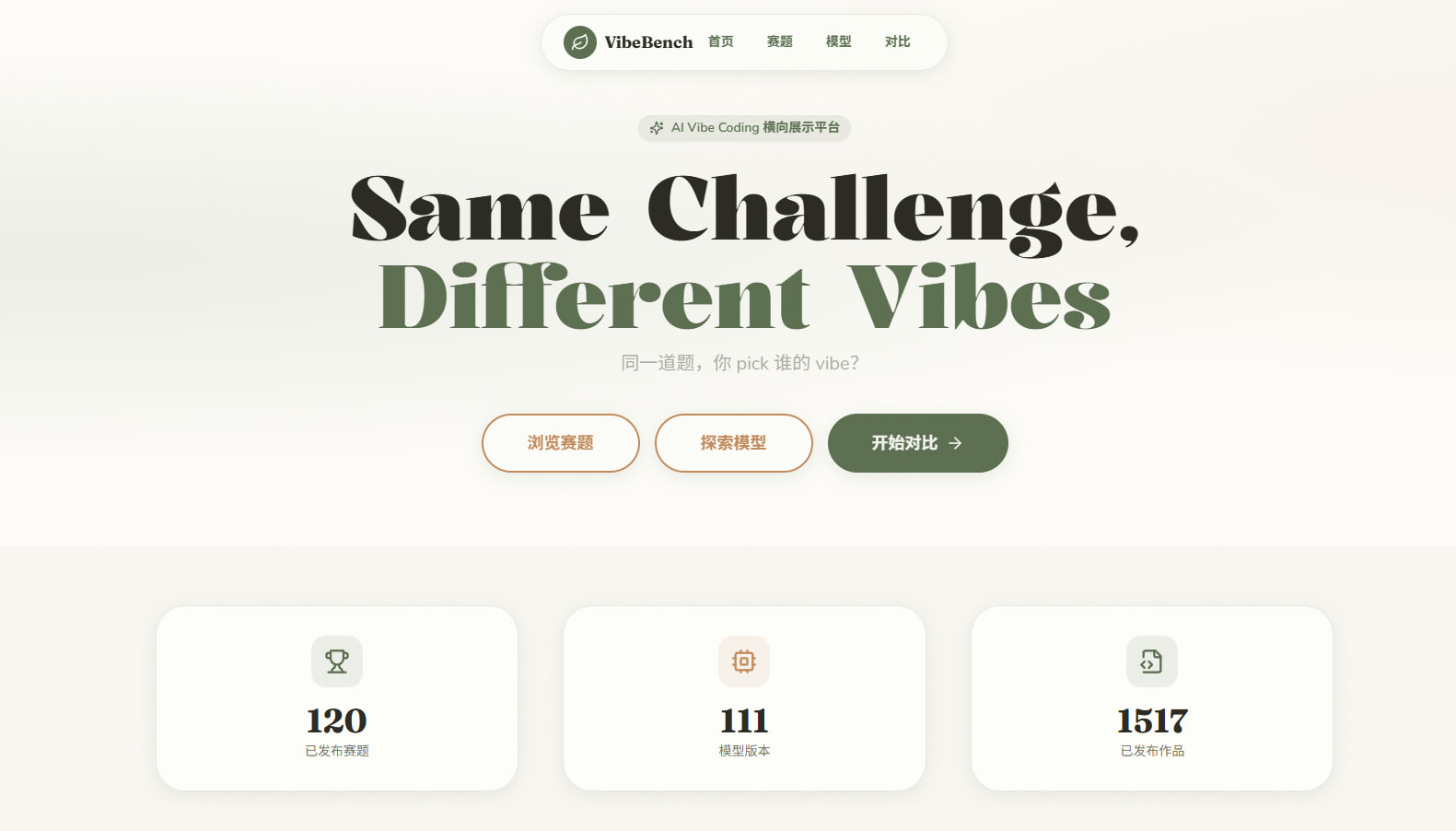
VibeBench — AI Vibe Coding 横向展示平台
同一道前端题,不同 AI 各展风格。浏览、对比、分享不同模型的前端作品。
For Whom?
市面上的benchmark,其实更多的是面向AI的研究者,面向AI的厂商,面向媒体KOL,面向股价,而非消费者
所以vibebench的manifesto是:
-
真实渠道,测试AI在不同渠道的表现
消费者不止调用API,消费者用手机APP,用AI IDE,用AI CLI,用Web Chat
消费者的渠道不止正价官方API,还有集合渠道和逆向中转 -
完全透明,没有打分,只有展示与对比,唯一的评判标准是消费者的看法
所有题目的提示词公开,任何人都可以尝试复现。
所有的作品公开,没有黑盒评分。 -
一次定生死(One Shot测试)
没有pass@10,没有Best of N -
消费者视角
把评判权交还给消费者,并列展示同一道题目的所有作品,提供匿名横评功能和直接对比功能
WHY HTML?
HTML是AI能力的金丝雀测试(canary test),AI的训练数据中HTML的内容不计其数,假设某个AI,HTML写的很好,那么想要直接推断出AI的全方位能力很强,那么并不科学,就像矿坑中的金丝雀,假设金丝雀存活,并不直接代表矿坑安全,但是假设某个AI,HTML写的很差,那么就像矿坑中的金丝雀直接死亡,说明矿坑非常危险,那么就有必要质疑AI的代码能力。
或许有人会觉得,写HTML不好,不代表代码能力很差,那么问题来了,AI被厂商训练并被宣传成“通才”,假设写HTML的水平都很差,那么有必要质疑通才的含金量
还有HTML本身的优势:
零门槛验证,不需要编译,只要打开浏览器,就能观察结果(有些作品引用了外部CDN,此时需要联网);
考察综合能力,HTML中同时检验了css/js/算法等内容;
难度可调整,从简单的AI自我介绍的静态页面,到3D渲染的页面,有足够低的起点和足够高的天花板。
开源一共分为两个部分,首先是框架本身:


其次是赛题,同样基于AGPL-3.0开源,使用、转载、分享请署名原作者。
那么究竟有什么赛题?
工具类:base64转码、简单的密钥生成、时钟工具箱、cron翻译器、RGB渐变调色板……
视觉类:滚动叙事、无尽DOM套娃、字体博物馆、苹果风首页、人生选择地图……
游戏类:21点、24点、打地鼠、吃豆人、俄罗斯方块、打砖块、2048、贪吃蛇……
算法类:迷宫生成与求解、模拟万花尺、模拟高尔顿板、排序算法可视化……
复刻类:Amazoom、Readit、Spotifly、Epoch 游戏商城……
赛题数量?
目前已经上传并公开的有120道大赛题,每个赛题分为独立的phase,共260+phase,phase包括简单提示词、复杂提示词、增加design system、PRD驱动等,除非特别标注,否则不同的phase之间互相独立,无上下文关联
缺陷?
One Shot,模型输出具有不稳定性;
HTML,对于其他编程语言的代表性有限;
多种渠道,不同模型的表现不同;
作者本人能力有限,赛题本身可能就有缺陷
致谢
感谢 @ocean-zhc 佬友授权,一开始的项目来源于用mimo v2 pro free 搞一个好玩的东西
后来慢慢扩展成vibebench
感谢 @yeahhe 佬友授权,有几道赛题来自https://linux.do/t/topic/286836 的前端生成题库,例如转盘题、天气卡片
感谢 @kingd 佬友帮助,帮忙做了Opus 4.8的一部分赛题
感谢L站,我的非常多渠道都是通过L站得知,L站极大地减少了AI时代的信息差
1 个帖子 - 1 位参与者