这个技巧是用来在互联网上寻找同样的系统或者是根据网站特征找到具体网站用的。
本文仅供娱乐
0x0 为什么写这个
在刷L站的时候发现有佬在找一个网站(https://linux.do/t/topic/2249936/11),当时正好在等codex的输出就试着找了找。然后发现有些佬友对这个感兴趣,我就简单的分享一下。
还有一点是我的被赞天数差一天就满条件了,想着捞捞赞。
如果有什么不对或者其他方面的补充,欢迎佬友指正
嘻嘻~
0x1 网络空间引擎
form 豆包

简单来说,网络空间引擎收集和检测了互联网上大部分web资产的首页的指纹特征,以便我们进行这方面的搜索
如果用quake的话,可以用我的邀请码吗,没有积分用了呜呜
FWzm0l
当然你用google语法进行搜索应该也是可行的
0x2 Web网站的前端指纹
我们知道在写前端的时候,我们会在前端中写入一些文字,或者是调用一些自己写的一些前端库或者是路径,因为可以按照这些特征作为线索找到相同的web系统或这特定的web系统,就像通过指纹可以找到一个人一样,我们把这些可以找到特定系统的前端特征叫做web系统的前端指纹(当然还有服务上的特征、协议上的特征等等,但是在这里将就偏题了)。
一些字段:
body:指的是请求浏览网站的响应体,可以F12的看下网络请求,大部分情况下整个前端都在响应体中
title:一个网站的标题,大部分情况下在标签页上显示的就是
favicon:一个网站图标,可以从F12的网络请求中那一张图片
0x3 从一个网站找到相同的网站的方面:
在网络安全(漏洞提交)的角度,这个技巧是用来评估我们找到的系统漏洞的危害用的,比如我们在找到某个系统存在漏洞,我们通过找到当前web系统的首页或者登录页的特征在【网络空间引擎】进行搜索,来看互联网上有多少个系统资产,就说明我们找到的漏洞影响了多少个互联网资产,这是我们提交漏洞后评级的重要依据。
如何选取web指纹这是我根据经验总结的,前端指纹要有不变性、独特性
** 不变性:**因为很多系统都会被经历二次开发,所以我们要找到哪些不那么容易被修改的特征,例如前端中的非通用的、自研的js调用路径
** 独特性:**其实在不变性里面也说过了,我们要找哪些非通用的、自研的js调用路径,或者是变量名这些。举个反例:例如【body:“<html”】这种几乎所有使用html的前端都存在的字段就不需要选取了。
以L站为例子:我们都知道L站是在这个discourse这个开源系统的基础上进行搭建的论坛,我们收集L站的前端特征,就可以找到其他同样使用discourse搭建的论坛
首先标题和图标肯定都在discourse基础上进行过修改的,不符合我们的不变性
所以我们来看L站的响应体,也就是前端
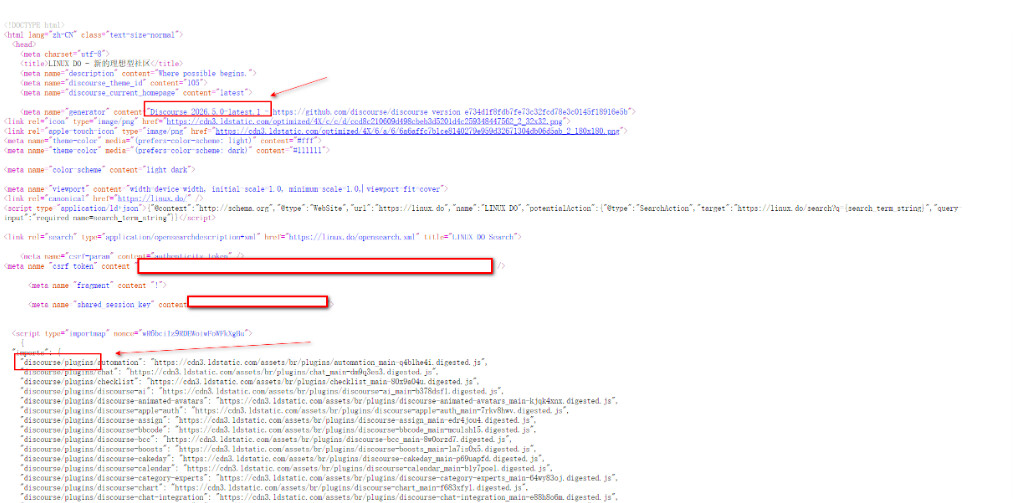
根据discourse这个开源项目的**独特性,**我们可以找到属于他的这些指纹 (我这里用的是360quake的语法,其他平台也有对应的语法,但是要求的特征基本上是一样的)
body:"Discourse " AND body:"discourse/plugins/"
试着搜一搜就可以找到其他的论坛了
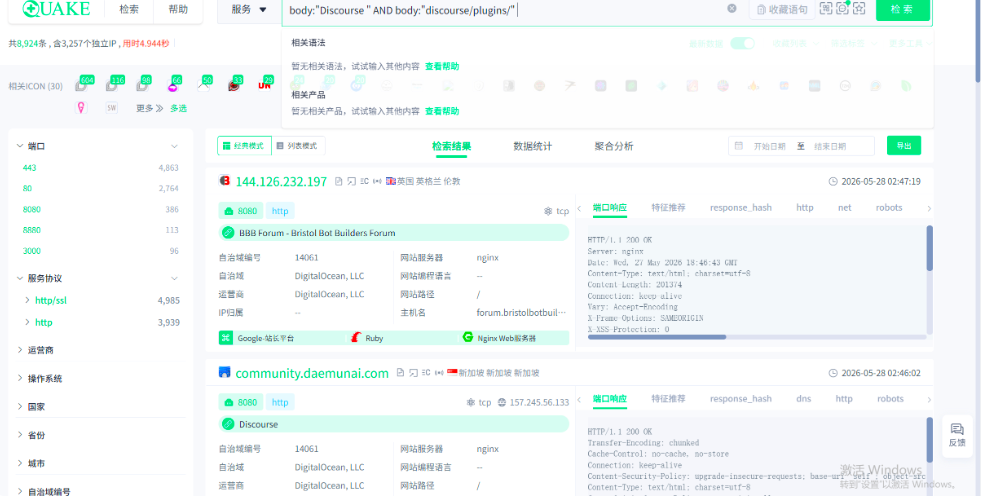
加上地区条件:
body:"Discourse " AND body:"discourse/plugins/" AND country_cn: "中国"

0x4 从一张图片找到对应的网站:
这个也是用到了我们之前说的独特性,拿之前佬的那张图片(https://linux.do/t/topic/2249936/11)进行举例

这张图片,我们可以看到很明显是AI写的一个mvp的基础上开了web的一个工具。而这些文字就是我们的线索,因为一般来说前端(简易的前端,这里不绝对)上的这些介绍用的文字都是硬编码在前端的。
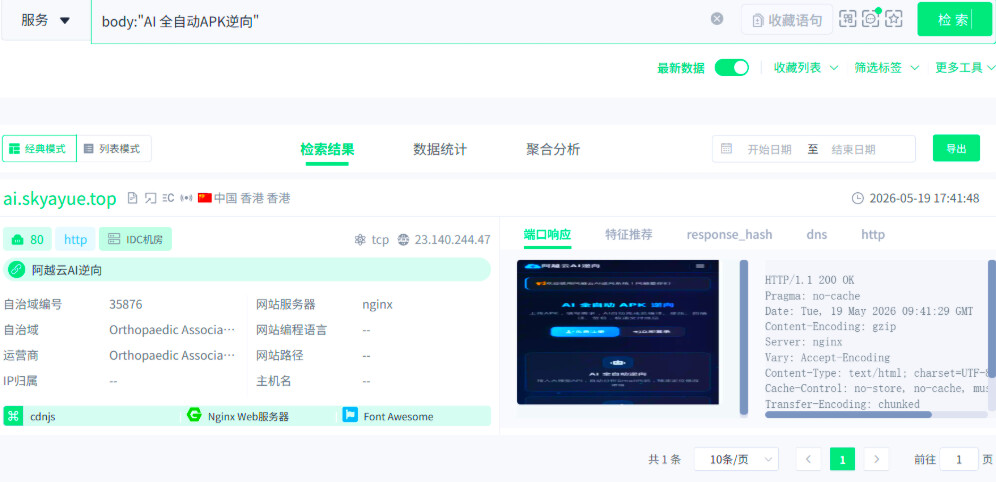
所以我推测他的响应体中存在这些文字,我们选一个最有特征的,于是构造搜索语句如下
body:"AI 全自动APK逆向"
成功找到:
不过现在好像关站了:
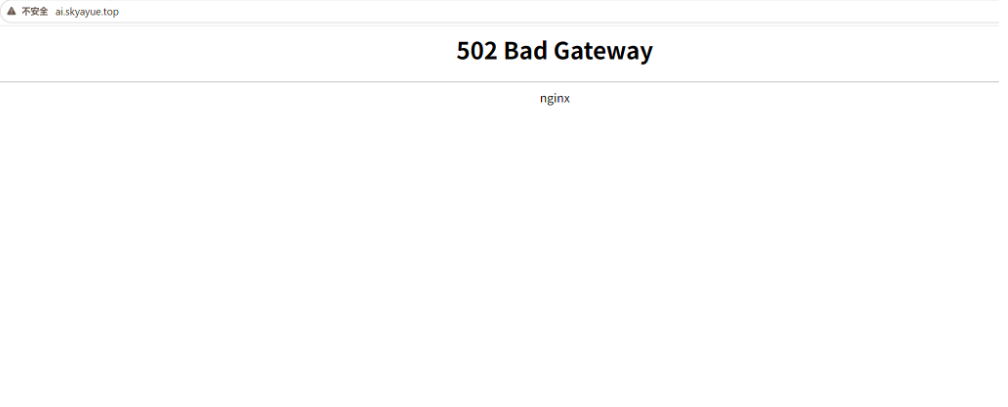
从一张图片找到对应的网站简单来说就是发现其中的在前端中可能存在的模块或者文字。当然这个也很有局限型,由于空间引擎\google探测到的基本上都是首页,所以我们根据一张应用内的图片是不太能直接找到的对应的资产的
2 个帖子 - 2 位参与者