佬们,大家有用多agent进行端到端研发吗?
背景:
领导已经不满足我们使用codex、cc、cursor此类工具进行人机协同研发了,理想很美好:希望就是随时随地都能进行开发,然后下班前扔一个需求给他,明天过来它就开发好了。其次领导想要代码更可控,代码熵要做好管控,所以对每一个阶段的产物要沉淀下来。目前openclaw和hermes对接飞书就是最合适的,因此对hermes的多agent协同进行了研究。
过程:
架构图:
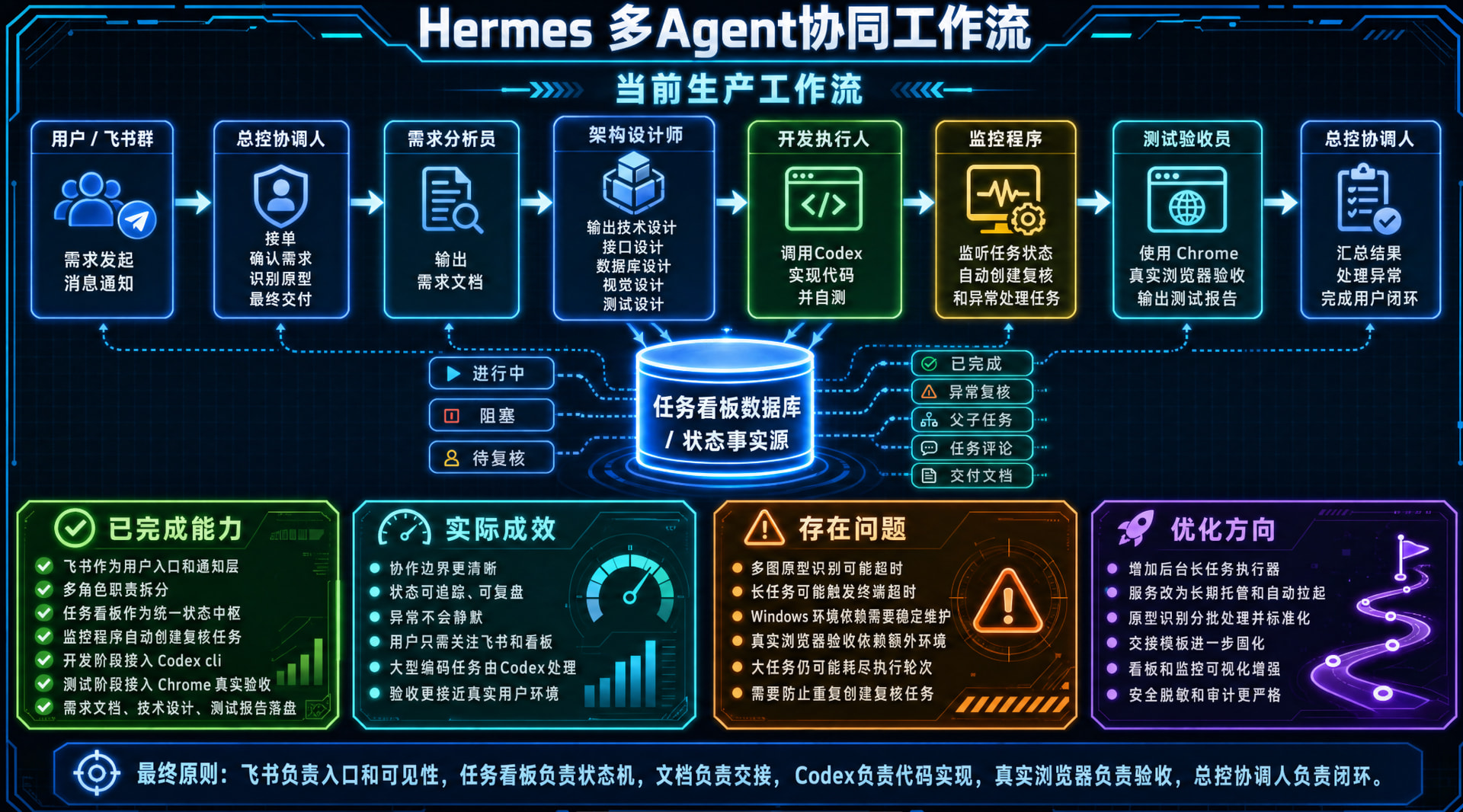
我使用了hermes的kanban多profile协同,编写了workflow和router,没有使用任何第三方skill,比如superpower、openspec等等。拆分了几个agent:
prod-main 生产入口 / PRD 任务创建 / 用户主动请求时的手动路由
prod-prd 生产 PRD / 创建 prod-architect child
prod-architect 技术方案 / 详细设计 / 创建 prod-coder child
prod-coder 生产开发 / 自测 / review-required handoff / 等待 tester approve
prod-tester 实现验收 / 通过后 unblock coder / 失败时缺陷报告
然后自定义了轻量的 Manual SDD 、handoffs、skill,每个agent规定了产物,用于下一个agent使用。
然后对接飞书,拉到一个群里,按prod-main->prod-prd->prod-architect->prod-coder->prod-tester这个链路自动化干活。
现状:
研究hermes多agent协同已经一周多了,也跑了两个需求了
1:第一个需求是同事近期使用codex耗时两周vibe已经开发好的一个全新系统,然后我反向拆解成需求文档,扔给我这套hermes自动化去跑,然后对比效果,细节肯定是比不上,因为使用codex他也是一点点调出来的,我自动化跑的话耗时差不多就几个小时,所以第一版效果就50%,只有形似,经不起推敲的,还有就是高保真问题,即使使用了stitch的mcp有原型组件代码,也只能还原80%,还有很多功能性问题,就是很粗糙
2:第二个需求就是这两天跑的一个存量简单需求,跑了6个小时吧,文档输出耗时了1个小时半,效果还行,完成了80%的要求,还有一些细节问题然他去修复。文档内容是很详细,但是核对内容也成为了一个成本耗时,加大了难度,即使我让ai自己去核对,还是需要我们人工再去核对一遍,因为prd和设计都不对的前提下,那coder开发就跟着偏了。
思考:
1、我认为codex或者cc开发效率肯定是最高,无论质量还是速度,但是无法沉淀下来一套稳定的工作流,就感觉就是纯vibe,一次性开发。
2、使用hermes还是openclaw的多agent协同,有好有坏吧,定义看起来是很合理的,agent干自己的活,干完可以自己沉淀下来,就类似一个prd实习生需求干多了就成为一个资深的prd,然后coder实习生干到后面成为了资深经验丰富的代码专家了。(领导也是看重这一点,想要的就是要有沉淀,要有经验,而不是开发完一个项目就完了,要有提效成功经验,你的提效要和推广给大家复用来提效,而不是纯vibecoding),就比如我研究这套机制的全过程踩坑和经验都要沉淀下来给别人学习。坏处:感觉代码研发更加黑盒了
3、vibe自己的项目没啥问题,企业的项目还是要进行熵管控,去年我们还在使用cursor(也是纯vibeCoding),也制定了很多rule和skill对标公司的代码规范来熵管控,比如:我们已经存在一个日期工具类或者已经有了日期转换的方法,AI就不能再给我们生成一个日期类或者一样的方法。
目前我看市场上也有挺多这种多agent协同的产物了,不知道效果怎么样
所以大家是怎么看待codex直接开发和多agent协同按照稳定工作流开发的?大家企业项目是怎么去开发的?
2 个帖子 - 2 位参与者