首先我必须得喷一下旧版token plan的计费策略,输入/缓存/输出一视同仁计费是人能想出来的策略啊? 没有缓存就是导致大家觉得旧版token不耐用的元凶
下来我们详细分析一下旧版plan和新版的区别,以及在不同的使用场景下我们手头的plan到底是增值了还是缩水了
要对比两版的用量,我们需要找到一个没有变化的锚点,在这里选取token数作为锚点。旧版的plan的计费规则很简单,所有token一视同仁,v2.5 1credit=1token,v2.5pro消耗翻倍 2credit=1token。所以旧plan可用的token数拉表如下
套餐档位 旧 credits v2.5(÷1) v2.5-pro(÷2) Lite 0.6亿 60M 30M Standard 2亿 200M 100M Pro 7亿 700M 350M Max 16亿 1600M 800M新的plan针对输入/缓存/输出做了不同的区分,如下图,v2系列模型没有优化不在讨论范围内
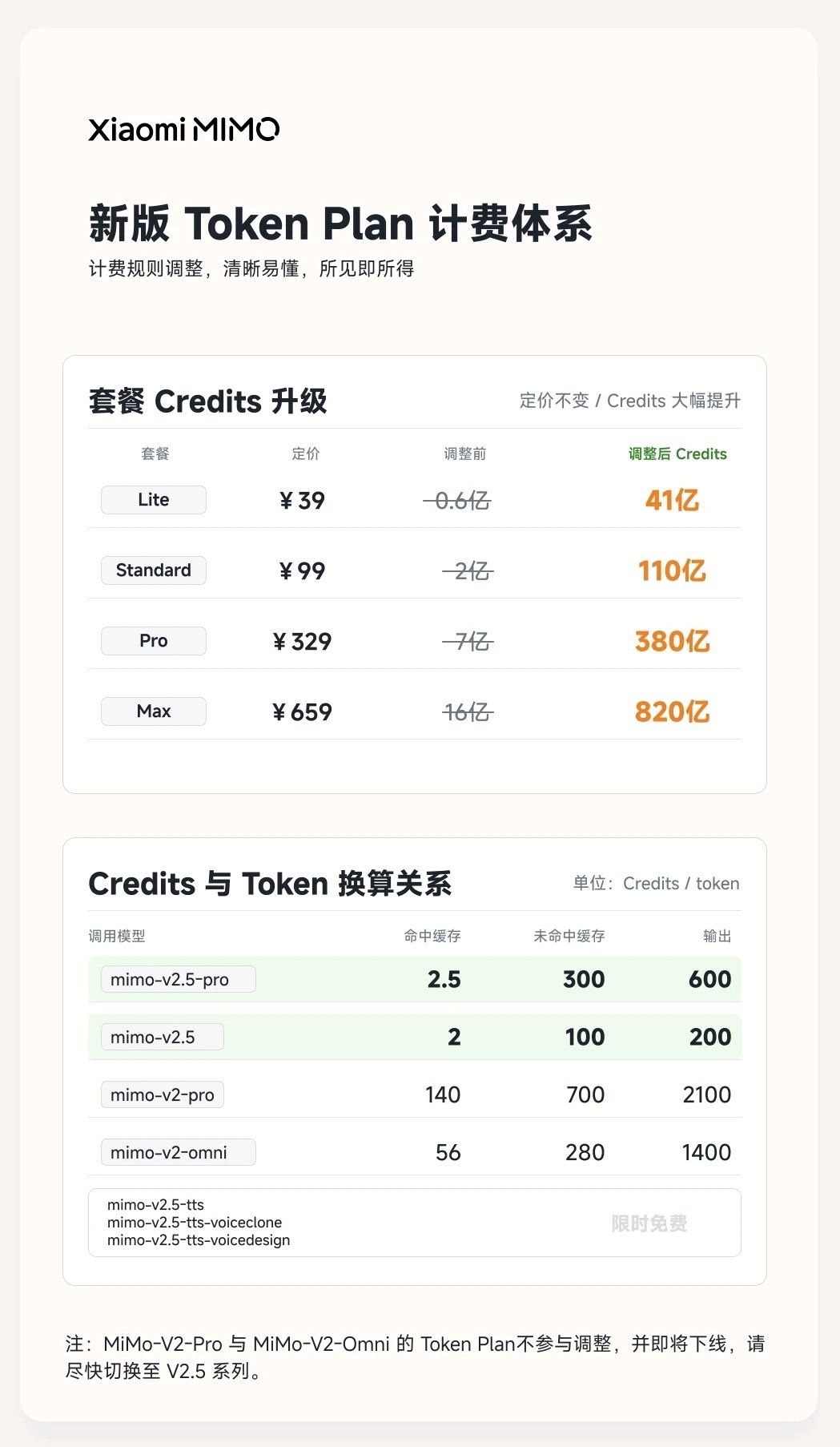
不同的真实应用场景对应的输入,缓存和输出比例是不同的,我们可以通过简单的公式来计算这些场景下实际token可用量,来和旧plan做比较
新 plan 可用 token 数(随工作负载组合变化)
设命中占比 c、未命中占比 u、输出占比 o(c + u + o = 1):
可用 token = 套餐 credits / (2·c + 100·u + 200·o) # v2.5
可用 token = 套餐 credits / (2.5·c + 300·u + 600·o) # v2.5-pro
分母 = 每 token 平均消耗的 credits,三项系数即三路费率(命中 / 未命中 / 输出)。
场景取claude给出的三个真实场景和两个极端边界条件(图一乐,有些人就是喜欢看)
三个代表性工作负载场景
- agent / 对话(命中 95% / 未命中 3% / 输出 2%):高缓存复用、几乎不产生未命中、输出极少。多轮对话和 agent 循环的典型形态——历史前缀逐字复用,每轮只追加少量新内容。
- 翻译批处理(命中 5% / 未命中 75% / 输出 20%):每条请求开头都不同,前缀基本不复用,命中率接近零。摘要、分类、抽取等单轮无状态批量调用同属此类。
- 生成密集(命中 40% / 未命中 20% / 输出 40%):输入端缓存命中尚可,但输出占比极高。长文写作、长链推理(CoT)等以产出为主的负载。
两个极端边界
- 纯命中(命中 100%):所有输入 token 都命中缓存、零未命中零输出。新 plan 的最优场景,每 token 仅耗 2 credits(v2.5),相对旧 plan 放大可达 25–34 倍。
- 纯输出(输出 100%):全部 token 都是输出、零输入。新 plan 的最劣场景,每 token 耗 200 credits(v2.5),可用 token 仅为旧 plan 的 1/4 到 1/3。
下面是拉表的结果
新版 MiMo-V2.5(旧 plan 基线 1 credit/token)
档位 旧 plan agent 翻译批处理 生成密集 纯命中 纯输出 Lite 60M 461M (7.68×) 35.6M (0.59×) 40.7M (0.68×) 2050M (34.2×) 20.5M (0.34×) Standard 200M 1236M (6.18×) 95.6M (0.48×) 109M (0.55×) 5500M (27.5×) 55M (0.28×) Pro 700M 4270M (6.10×) 330M (0.47×) 377M (0.54×) 19000M (27.1×) 190M (0.27×) Max 1600M 9213M (5.76×) 712M (0.45×) 814M (0.51×) 41000M (25.6×) 410M (0.26×)新版 MiMo-V2.5-Pro(旧 plan 基线 2 credits/token)
档位 旧 plan agent 翻译批处理 生成密集 纯命中 纯输出 Lite 30M 175M (5.85×) 11.9M (0.40×) 13.6M (0.45×) 1640M (54.7×) 6.8M (0.23×) Standard 100M 471M (4.71×) 31.9M (0.32×) 36.5M (0.37×) 4400M (44.0×) 18.3M (0.18×) Pro 350M 1626M (4.64×) 110M (0.31×) 126M (0.34×) 15200M (43.4×) 63.3M (0.18×) Max 800M 3504M (4.38×) 238M (0.30×) 272M (0.34×) 32800M (41.0×) 137M (0.17×)从表中我们可以得出一个结论,这次的plan变动利好高缓存场景,v2.5的用量提升符合官方宣传口径的5-8倍。
**但是!**在缓存不足且侧重输出的场景下,出现了plan缩水的情况。我们选定的场景中最严重时仅有原plan的30%,这是小米初版token plan设计不合理带来的反噬,各位佬友可以根据自身情况选择是否继续续费它。
以上所有的讨论都是基于plan价值来讨论的,api就是实打实的降价没有什么可分析的。最后依然是大家在论坛中的讨论可以理性一些,少一些主观情绪的输出, 真诚 、友善 、团结 、专业 ,共建你我引以为荣之社区。
7 个帖子 - 4 位参与者